On June 10, 2026, Google DeepMind released DiffusionGemma — an open 26B parameter model (3.8B active) that generates text via diffusion instead of the standard autoregressive approach.
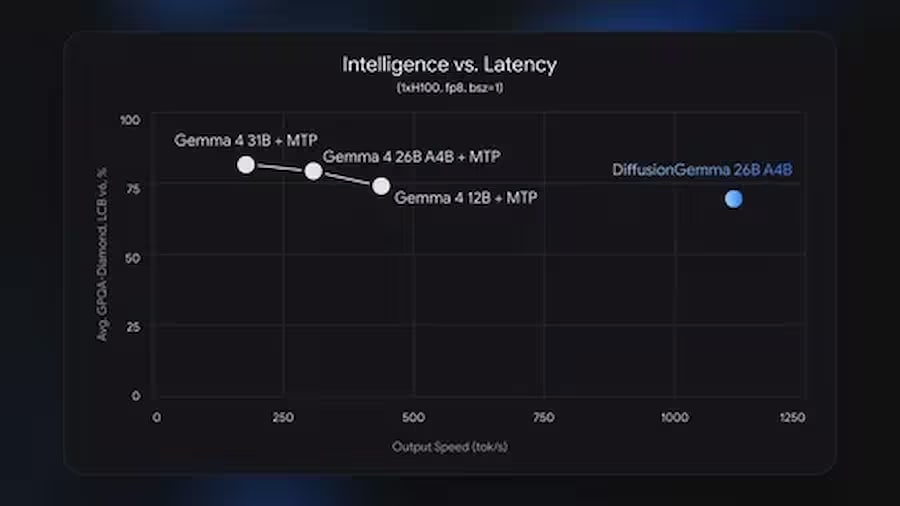
Speed: 1000+ tokens per second on NVIDIA H100, 700+ on RTX 5090.
The model runs locally with 18 GB VRAM, available on Hugging Face under the Apache 2.0 license.
Supported via vLLM, Hugging Face Transformers, MLX, Unsloth, NVIDIA NeMo.
Main trade-off: speed is higher than Gemma 4, but response quality is lower.
What is DiffusionGemma
DiffusionGemma is an experimental open language model from Google DeepMind, released on June 10, 2026. It is built on the Gemma 4 (MoE, 26B parameters, 3.8B active) architecture and uses a fundamentally different approach to text generation — text diffusion instead of autoregressive decoding.
The model has a context window of 262,144 tokens, supports over 140 languages, and is multimodal: it accepts text, images, and video as input. The weights are published on Hugging Face under the Apache 2.0 license.
Official documentation is available on Google AI for Developers. DiffusionGemma is the first diffusion model natively supported in the open inference platform vLLM.
How it differs from GPT, Gemini, Qwen, and Llama
All modern large language models — GPT-4o, Gemini 2.5, Qwen3, Llama 4 — are built on the same principle: autoregressive generation. The model generates text token by token, from left to right. Each new token depends on all previous ones. This is efficient but slow: the GPU waits for the result of the previous step before starting the next.
To understand the difference, it's helpful to have a concrete analogy. An autoregressive model is like a typist: she types one character at a time, cannot go back and correct a previous line until she reaches the end. DiffusionGemma is like an editor who sees the entire paragraph at once: first writes a draft, then reviews and refines it several times until the text becomes coherent.
How exactly does the mechanics differ
An autoregressive model does the same thing at each step: it looks at all previous tokens and predicts the next one. This means that to generate 256 tokens, the model performs 256 separate forward passes through the neural network. Each of them depends on the result of the previous one — they cannot be parallelized.
DiffusionGemma works differently. It generates a block of 256 tokens at once in a few refinement iterations. In the first iteration, all 256 positions are filled with "noise" — random or uninformative tokens. In each subsequent step, the model reviews the entire block and replaces the least confident tokens with more accurate ones. The key detail: at each step, each token sees all its neighbors in the block — this is bidirectional attention, unlike the unidirectional attention in standard LLMs.
The result: instead of 256 sequential forward passes, there are a few parallel iterations over the entire block. The GPU is loaded evenly, without waiting between steps.
Comparison of approaches
Parameter
GPT / Qwen / Llama
DiffusionGemma
Generation principle
Token by token, 1 forward pass per token
In blocks of 256 tokens, several iterations per block
Attention direction
Unidirectional (left to right)
Bidirectional (each token sees all in the block)
Correction during generation
Impossible: token is fixed forever
Possible: block is reviewed at each iteration
GPU load (single user)
Sequential; there is idle time between steps
Parallel; tensor cores are loaded evenly
GPU load (large batch)
Efficient: batch fills the GPU completely
Less efficient: advantage decreases
Infilling (insertion in the middle)
Requires special FIM tricks
Natural task: block sees context from both sides
Output quality
High, proven on benchmarks
Lower than Gemma 4 at the current stage
Speed (single user, GPU)
50–150 tokens/s depending on the model
700–1200+ tokens/s on modern GPUs
License
Varies: from MIT to proprietary
Apache 2.0
Where the difference is fundamental, and where it is not
Bidirectional attention is not just a technical detail. For an autoregressive model, a token at position 100 "doesn't know" what will be at position 101. For DiffusionGemma, each token in the block is generated from the beginning, taking into account all neighbors. This opens up tasks where the autoregressive approach requires special workarounds:
Code infilling: inserting code between two existing blocks, considering the context above and below.
Structured formats: generating JSON or SQL, where the final structure is known in advance.
Document editing: filling in a missing fragment while preserving the style before and after.
At the same time, there are scenarios where autoregressive models retain an advantage. Cloud serving with a large batch size is precisely where DiffusionGemma's parallelism yields less benefit, and GPT-4o or Gemini 2.5 Flash's thousands of requests per second are processed more efficiently. Long analytical answers, complex reasoning, RLHF-tuned tasks — here, years of scaling the autoregressive approach provide a tangible quality advantage.
An honest assessment of the trade-off
Google frankly admits: DiffusionGemma is inferior to the standard Gemma 4 in overall quality on benchmarks. This is not marketing understatement — it is the current state of affairs as of June 2026. The diffusion approach for text is orders of magnitude younger than autoregressive in terms of accumulated scaling experience.
Parameter
GPT / Llama / Qwen
DiffusionGemma
Architecture
Autoregressive
Diffusion
Generation
Token by token (1 forward pass per token)
In blocks of 256 tokens (several iterations per block)
Attention direction
Unidirectional — left to right
Bidirectional — each token sees all in the block
Can correct previous text
No — token is fixed forever
Yes — block is reviewed at each iteration
Infilling (insertion in the middle)
Requires FIM tricks, unstable
Natural task — context from both sides
GPU load (single user)
Sequential, there is idle time between steps
Parallel, tensor cores are loaded evenly
GPU load (large batch)
Efficient — batch fills the GPU completely
Advantage decreases at high QPS
Speed (single user, H100)
~50–150 tokens/s
1000–1200+ tokens/s
Output quality
High, proven over years
Lower than Gemma 4 at the current stage
Ecosystem maturity
Ollama, llama.cpp, vLLM, LM Studio — full support
vLLM, HF Transformers, MLX — llama.cpp and Ollama still in progress
License (main models)
Varies: MIT, Llama Community, Apache 2.0
Apache 2.0
Comparison of autoregressive and diffusion approaches to text generation. Data: Google, vLLM blog, June 2026.
The right way to think about DiffusionGemma is not as "Gemma 4, but faster," but as a different tool with its own trade-off profile: higher speed and natural infilling in exchange for lower overall quality and a less mature ecosystem. For some tasks, this trade-off is already beneficial. For others — not yet.
How diffusion text generation works
The idea of diffusion came from image generation. There, the model takes a noisy image and gradually "cleans" it over several steps until it gets a clear result. DiffusionGemma applies this same principle to text.
The generation process occurs in three conceptual stages:
Initialization. The model creates a block of 256 random placeholder tokens ("noise").
Iterative denoising. Over several passes, the model gradually replaces the "noise" with actual tokens. At each step, each token "sees" all neighbors in the block — this is bidirectional attention.
Convergence. After several iterations, the block transforms into coherent text.
The key difference from the autoregressive approach: the model does not "fix" a token immediately and forever. It can review and correct the entire block during the refinement process. This opens up new use cases: filling in gaps in text, inserting code in the middle of a file, correcting formatting — tasks where autoregressive models are traditionally weaker.
Technical detail: Google has implemented so-called entropy-bound denoising — a mechanism that determines how many cleaning steps are needed for each specific block. Simple blocks are processed faster, complex ones receive more iterations.
Speed: up to 1000+ tokens per second
Official performance metrics from Google and the vLLM team:
For comparison: standard autoregressive models of similar size yield approximately 50–150 tokens/s on the same hardware under single-user load. DiffusionGemma's 4x advantage is realized precisely in low parallelism mode — for one or a few simultaneous requests.
Important caveat: with large batch sizes (hundreds of simultaneous requests in the cloud), the advantage disappears. VentureBeat notes that for cloud serving with mass batching, autoregressive models remain more efficient. DiffusionGemma is primarily aimed at local deployment and interactive scenarios.
MLX — for Mac with Apple Silicon (supported, but speed is significantly lower)
Unsloth — for fine-tuning
NVIDIA NeMo — for enterprise deployment
llama.cpp — support in progress (PR not yet merged)
Ollama is not yet supported. When llama.cpp gets final DiffusionGemma support, Ollama integration will appear automatically — but the timeline is unknown. For Mac users, MLX works, but without a significant speed advantage over regular models.
Most news focuses on the "4x faster" figure. But the real importance of DiffusionGemma isn't speed, but what lies behind it. To understand this, we need to look at how language models have evolved over the past eight years – and why that evolution has been one-sided.
8 Years of One Path
The transformer architecture emerged in 2017 in Google's paper "Attention is All You Need." From GPT-1 to GPT-4o, from Llama 1 to Llama 4, from Qwen to Mistral – all these models are built on the same principle: autoregressive generation from left to right. Token by token. For over 8 years, the industry has scaled a single architecture, increasing parameters, data quality, and computation.
This wasn't accidental. The autoregressive approach had real advantages: it scaled well, its behavior was understood, and new models could be compared against each other on standard benchmarks. Every year, new versions were released – larger, more accurate, cheaper to infer. But the fundamental logic remained unchanged.
Alternatives existed in academia – masked diffusion, discrete diffusion, MDLM – but none went beyond small experiments. The industry bet on transformers and scaling, and that bet paid off. The problem is that the success of one approach crowds out research into others. When GPT-3 showed that scaling works, most resources went there.
Why the Autoregressive Approach Has a Structural Ceiling
Generating token by token isn't just a matter of speed. It's a matter of how the model "thinks." Each subsequent token is conditionally dependent on all preceding ones, and this dependency is unidirectional and irreversible. The model cannot revise what has already been generated – it can only continue.
This creates several fundamental limitations:
Errors propagate. If the model chooses a bad token at step 15, all subsequent 200 tokens are built on that error. Mechanisms like temperature and top-p reduce the probability of error but don't fully solve the problem.
Infilling is a structural weakness. Inserting text into the middle of an existing fragment is non-trivial for an autoregressive model. Special tricks (FIM – fill-in-the-middle) are needed, which add complexity and don't always work reliably.
GPU idles. With single-user inference, autoregressive generation loads the GPU sequentially: step by step. There are delays between steps. For local execution, this means that for most of the time, powerful hardware is simply waiting.
Long contexts are expensive. Each new token "looks" at the entire preceding context through the attention mechanism. The longer the context, the more expensive each subsequent step becomes.
An Alternative That Actually Works
Diffusion models for text have existed before – but only as academic experiments on a small scale. DiffusionGemma is the first large diffusion model with an MoE architecture released to the public with production-grade support in leading frameworks. This is not a demo or a waitlist – these are open weights that can be downloaded right now.
Prior to this, the closest commercial example was Mercury Coder by Inception Labs – a diffusion model for code released in early 2025. But it remained closed and domain-specific. DiffusionGemma is the first open, general-purpose model in this class.
It's important to understand that Google hasn't just released "another model." The company has integrated DiffusionGemma into real inference infrastructure: native support in vLLM, Hugging Face Transformers, MLX, optimization for NVIDIA Hopper and Blackwell. This is a signal that Google takes the diffusion approach seriously – not as a research artifact, but as a potentially production-ready direction.
A New Generation Logic – and What It Unlocks
The autoregressive approach has a fundamental limitation: the model cannot "go back." An error in the middle of a sentence is fixed, and all subsequent tokens are built upon it. DiffusionGemma can revise an entire block during generation – this is a fundamentally different logic.
In practice, this means new scenarios where autoregressive models are traditionally weak:
Code infilling. Inserting a function into the middle of a file, respecting the context above and below – precisely where bidirectional attention offers a real advantage.
Structured formats. Generating JSON, SQL, or XML with strict structural constraints: a diffusion model can "keep the final form of the block in mind" and adjust the entire text to it at once.
Editing and completion. Filling a gap in an already written document, preserving the style and context before and after – autoregressive models struggle with this, while the diffusion approach solves the task naturally.
Interactive applications. Where latency is critical – autocomplete in an editor, live summarization, real-time translation – 1000+ tokens per second with local execution opens up previously unavailable possibilities.
The implications for RAG pipelines and agent systems are yet to be assessed in practice. But the very fact that an alternative architecture for text generation is now available in production – with open weights, real infrastructure, and support from Google – is significant, regardless of current quality limitations.
What's Next
Autoregressive models in 2017 were also not ideal. GPT-1 generated coherent text, but the quality was far from modern standards. Over 8 years of scaling, data improvements, and new architectural solutions have transformed the transformer into the foundation of the entire industry.
The diffusion approach for text is now roughly where autoregressive was in 2018-2019. There's a first large open sample. There's a real advantage in specific scenarios. There are structural limitations that have not yet been overcome. And there's an open question: how much time and resources will it take for diffusion models to catch up to autoregressive in quality?
Google doesn't answer this question directly. But the very fact that DiffusionGemma was released under Apache 2.0 with full infrastructure support is not an academic publication. It's a statement that the direction is worthy of serious attention.
What This Means for the Future of LLMs
For now, DiffusionGemma is an experimental model. Google doesn't hide that its overall quality is inferior to the standard Gemma 4. For production tasks where accuracy is crucial, autoregressive models remain the better choice.
But there are several signals worth tracking:
The speed of diffusion model development. Autoregressive models scaled for years before reaching their current quality level. The diffusion approach is just beginning this journey.
Scenarios where diffusion already wins. Local execution, code infilling, interactive editing, low-latency tasks – the advantage is already real here.
Impact on infrastructure. DiffusionGemma is the first natively supported diffusion model in vLLM. This means the infrastructure ecosystem is starting to adapt.
Competitors are watching. Inception Labs is already in this space. If the diffusion approach shows consistent quality improvement, other major players will start investing more actively.
DiffusionGemma is not a revolution that will replace GPT and Llama tomorrow. But it is the first serious public proof that an alternative architecture for text generation can work in real-world conditions. And that is already significant enough.
Read more in the series
This is the first article in a series about DiffusionGemma and the new language model architecture.