10 червня 2026 року Google DeepMind випустила DiffusionGemma — відкриту модель на 26B параметрів (3.8B активних), яка генерує текст через diffusion замість стандартного autoregressive-підходу.
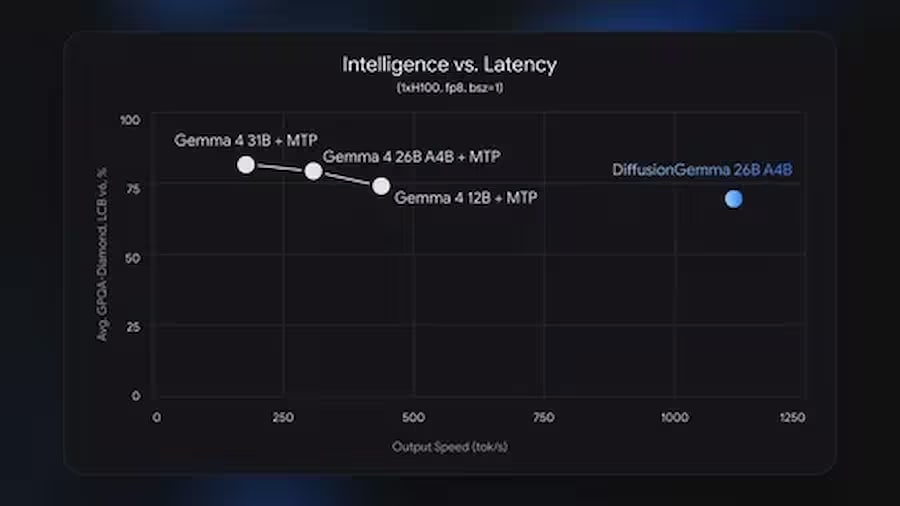
Швидкість: 1000+ токенів на секунду на NVIDIA H100, 700+ на RTX 5090.
Модель запускається локально при 18 GB VRAM, доступна на Hugging Face під ліцензією Apache 2.0.
Підтримується через vLLM, Hugging Face Transformers, MLX, Unsloth, NVIDIA NeMo.
Головний компроміс: швидкість вища за Gemma 4, але якість відповідей — нижча.
Що таке DiffusionGemma
DiffusionGemma — це експериментальна відкрита мовна модель від Google DeepMind, яка вийшла 10 червня 2026 року. Вона побудована на архітектурі Gemma 4 (MoE, 26B параметрів, 3.8B активних) та використовує принципово інший підхід до генерації тексту — text diffusion замість autoregressive decoding.
Модель має контекстне вікно 262 144 токени, підтримує понад 140 мов і є мультимодальною: приймає на вхід текст, зображення та відео. Ваги опубліковані на Hugging Face під ліцензією Apache 2.0.
Офіційна документація доступна на Google AI for Developers. DiffusionGemma є першою diffusion-моделлю, яка нативно підтримується у відкритій inference-платформі vLLM.
Чим вона відрізняється від GPT, Gemini, Qwen і Llama
Усі сучасні великі мовні моделі — GPT-4o, Gemini 2.5, Qwen3, Llama 4 — побудовані на одному й тому самому принципі: autoregressive generation. Модель генерує текст токен за токеном, зліва направо. Кожен новий токен залежить від усіх попередніх. Це ефективно, але повільно: GPU очікує на результат попереднього кроку перед тим, як почати наступний.
Щоб зрозуміти різницю, корисно мати конкретну аналогію. Autoregressive-модель — це машиністка: вона друкує по одному символу, не може повернутися і виправити попередній рядок, поки не дійде до кінця. DiffusionGemma — це редактор, який бачить весь абзац одразу: спочатку пише чернетку, потім кілька разів переглядає і уточнює, поки текст не стає зв'язним.
Як саме відрізняється механіка
Autoregressive-модель на кожному кроці робить одне й те ж: дивиться на всі попередні токени і передбачає наступний. Це означає, що для генерації 256 токенів модель виконує 256 окремих forward pass через нейромережу. Кожен з них залежить від результату попереднього — паралелізувати їх неможливо.
DiffusionGemma працює інакше. Вона генерує відразу блок із 256 токенів за кілька ітерацій refinement. На першій ітерації всі 256 позицій заповнені «шумом» — випадковими або малоінформативними токенами. На кожному наступному кроці модель переглядає весь блок і замінює найменш впевнені токени на більш точні. Ключова деталь: на кожному кроці кожен токен бачить усіх сусідів у блоці — це двонаправлена увага, на відміну від односторонньої у стандартних LLM.
Результат: замість 256 послідовних forward pass — кілька паралельних ітерацій над усім блоком. GPU завантажений рівномірно, без очікування між кроками.
Порівняння підходів
Параметр
GPT / Qwen / Llama
DiffusionGemma
Принцип генерації
Токен за токеном, 1 forward pass на токен
Блоками по 256 токенів, кілька ітерацій на блок
Напрямок уваги
Одностороннє (зліва направо)
Двонаправлене (кожен токен бачить усіх у блоці)
Виправлення під час генерації
Неможливе: токен зафіксовано назавжди
Можливе: блок переглядається на кожній ітерації
Завантаження GPU (single user)
Послідовне; між кроками є простій
Паралельне; тензорні ядра завантажені рівномірно
Завантаження GPU (великий batch)
Ефективне: batch заповнює GPU повністю
Менш ефективне: перевага зменшується
Infilling (вставка у середину)
Потрібні спеціальні FIM-трюки
Природна задача: блок бачить контекст з обох боків
Якість виводу
Висока, перевірена на бенчмарках
Нижча за Gemma 4 на поточному етапі
Швидкість (single user, GPU)
50–150 токенів/с залежно від моделі
700–1200+ токенів/с на сучасних GPU
Ліцензія
Varies: від MIT до proprietary
Apache 2.0
Де різниця принципова, а де — ні
Двонаправлена увага — це не просто технічна деталь. Для autoregressive-моделі токен на позиції 100 «не знає», що буде на позиції 101. Для DiffusionGemma кожен токен у блоці від початку генерується з урахуванням усіх сусідів. Це відкриває задачі, де autoregressive-підхід потребує спеціальних обхідних рішень:
Code infilling: вставка коду між двома існуючими блоками з урахуванням контексту зверху і знизу.
Структуровані формати: генерація JSON або SQL, де кінцева структура відома заздалегідь.
Редагування документів: заповнення пропущеного фрагменту із збереженням стилю до і після.
Водночас є сценарії, де autoregressive-моделі зберігають перевагу. Хмарний serving із великим batch size — саме там, де паралелізм DiffusionGemma дає менший виграш, а тисячі запитів на секунду у GPT-4o чи Gemini 2.5 Flash обробляються ефективніше. Довгі аналітичні відповіді, складний reasoning, задачі з RLHF-тюнінгом — тут роки масштабування autoregressive-підходу дають відчутну перевагу в якості.
Чесна оцінка компромісу
Google відверто визнає: DiffusionGemma поступається звичайній Gemma 4 за загальною якістю на бенчмарках. Це не маркетингове применшення — це реальний стан справ на червень 2026 року. Diffusion-підхід для тексту молодший за autoregressive на кілька порядків в плані накопиченого досвіду масштабування.
Параметр
GPT / Llama / Qwen
DiffusionGemma
Архітектура
Autoregressive
Diffusion
Генерація
Токен за токеном (1 forward pass на токен)
Блоками по 256 токенів (кілька ітерацій на блок)
Напрямок уваги
Одностороннє — зліва направо
Двонаправлене — кожен токен бачить усіх у блоці
Може виправляти попередній текст
Ні — токен зафіксовано назавжди
Так — блок переглядається на кожній ітерації
Infilling (вставка у середину)
Потрібні FIM-трюки, нестабільно
Природна задача — контекст з обох боків
Завантаження GPU (single user)
Послідовне, між кроками є простій
Паралельне, тензорні ядра завантажені рівномірно
Завантаження GPU (великий batch)
Ефективне — batch заповнює GPU повністю
Перевага зменшується при високому QPS
Швидкість (single user, H100)
~50–150 токенів/с
1000–1200+ токенів/с
Якість виводу
Висока, перевірена роками
Нижча за Gemma 4 на поточному етапі
Зрілість екосистеми
Ollama, llama.cpp, vLLM, LM Studio — повна підтримка
vLLM, HF Transformers, MLX — llama.cpp і Ollama ще в процесі
Ліцензія (основні моделі)
Varies: MIT, Llama Community, Apache 2.0
Apache 2.0
Порівняння autoregressive та diffusion підходів до генерації тексту. Дані: Google, vLLM blog, червень 2026.
Правильний спосіб думати про DiffusionGemma — не як про «Gemma 4, але швидше», а як про інший інструмент із власним профілем trade-offs: вища швидкість і природний infilling в обмін на нижчу загальну якість і менш зрілу екосистему. Для частини завдань цей обмін вигідний вже зараз. Для інших — поки ні.
Процес генерації відбувається у три концептуальні етапи:
Ініціалізація. Модель створює блок із 256 випадкових токенів-заповнювачів («шум»).
Iterative denoising. За кілька проходів модель поступово замінює «шум» на реальні токени. На кожному кроці кожен токен «бачить» усіх сусідів у блоці — це двонаправлена увага.
Конвергенція. Після декількох ітерацій блок перетворюється на зв'язний текст.
Ключова відмінність від autoregressive-підходу: модель не «зафіксовує» токен одразу і назавжди. Вона може переглянути та скоригувати весь блок у процесі refinement. Це відкриває нові сценарії використання: заповнення прогалин у тексті, вставка коду в середину файлу, виправлення форматування — завдання, де autoregressive-моделі традиційно слабкіші.
Технічна деталь: Google реалізувала так зване entropy-bound denoising — механізм, що визначає, скільки кроків очищення потрібно для кожного конкретного блоку. Прості блоки обробляються швидше, складні — отримують більше ітерацій.
Швидкість: до 1000+ токенів на секунду
Офіційні показники продуктивності від Google та команди vLLM:
Для порівняння: стандартні autoregressive-моделі аналогічного розміру дають приблизно 50–150 токенів/с на тому ж залізі при single-user навантаженні. Перевага DiffusionGemma в 4x реалізується саме в режимі низького паралелізму — для одного або кількох одночасних запитів.
Важливе застереження: при великих batch size (сотні паралельних запитів у хмарі) перевага зникає. VentureBeat зазначає, що для хмарного serving із масовим батчингом autoregressive-моделі залишаються ефективнішими. DiffusionGemma орієнтована насамперед на локальний запуск та інтерактивні сценарії.
MLX — для Mac з Apple Silicon (підтримується, але швидкість значно нижча)
Unsloth — для fine-tuning
NVIDIA NeMo — для корпоративного розгортання
llama.cpp — підтримка в процесі (PR ще не змерджено)
Ollama поки не підтримується. Коли llama.cpp отримає фінальну підтримку DiffusionGemma, Ollama-інтеграція з'явиться автоматично — але терміни невідомі. Для Mac-користувачів MLX працює, але без суттєвої перевагу швидкості над звичайними моделями.
Більшість новин зосереджуються на цифрі «4x швидше». Але справжня важливість DiffusionGemma — не у швидкості, а в тому, що стоїть за нею. Щоб зрозуміти це, потрібно подивитися на те, як розвивалися мовні моделі останні вісім років — і чому цей розвиток був однобічним.
8 років одного шляху
Архітектура трансформера з'явилася у 2017 році у статті Google «Attention is All You Need». Від GPT-1 до GPT-4o, від Llama 1 до Llama 4, від Qwen до Mistral — усі ці моделі побудовані на одному й тому ж принципі: autoregressive generation зліва направо. Токен за токеном. Понад 8 років індустрія масштабувала одну архітектуру, збільшуючи параметри, якість даних та обчислення.
Це не було випадковістю. Autoregressive-підхід мав реальні переваги: він добре масштабувався, його поведінку було зрозуміло, а нові моделі можна було порівнювати між собою на стандартних бенчмарках. Щороку виходили нові версії — більші, точніші, дешевші в inference. Але фундаментальна логіка залишалася незмінною.
Альтернативи існували в академічному середовищі — masked diffusion, discrete diffusion, MDLM — але жодна з них не виходила за межі невеликих експериментів. Індустрія зробила ставку на трансформер і масштабування, і ця ставка виправдала себе. Проблема в тому, що успіх одного підходу витісняє дослідження інших. Коли GPT-3 показав, що масштабування працює, більша частина ресурсів пішла саме туди.
Чому autoregressive-підхід має структурну стелю
Генерація токен за токеном — це не просто питання швидкості. Це питання того, як модель «думає». Кожен наступний токен умовно залежить від усіх попередніх, і ця залежність є однонаправленою та незворотною. Модель не може переглянути вже згенероване — вона може лише продовжувати.
Це створює кілька фундаментальних обмежень:
Помилка розповсюджується. Якщо модель обрала невдалий токен на кроці 15, всі наступні 200 токенів будуються на цій помилці. Механізми на кшталт temperature і top-p зменшують ймовірність помилки, але не вирішують проблему повністю.
Infilling — структурна слабкість. Вставити текст у середину вже існуючого фрагмента для autoregressive-моделі нетривіально. Потрібні спеціальні трюки (FIM — fill-in-the-middle), які додають складності і не завжди працюють стабільно.
GPU простоює. При single-user inference autoregressive-генерація завантажує GPU послідовно: крок за кроком. Між кроками є затримки. Для локального запуску це означає, що більшу частину часу потужне залізо просто чекає.
Довгі контексти коштують дорого. Кожен новий токен «дивиться» на весь попередній контекст через механізм уваги. Чим довший контекст — тим дорожче кожен наступний крок.
Альтернатива, яка реально працює
Diffusion-моделі для тексту існували й раніше — але лише як академічні експерименти у невеликих масштабах. DiffusionGemma — перша велика diffusion-модель з MoE-архітектурою, що вийшла у відкритий доступ із production-grade підтримкою у провідних фреймворках. Це не демо і не waitlist — це відкриті ваги, які можна завантажити прямо зараз.
До цього найближчим комерційним прикладом був Mercury Coder від Inception Labs — diffusion-модель для коду, що вийшла на початку 2025 року. Але вона залишалася закритою і domain-specific. DiffusionGemma — перша відкрита модель загального призначення у цьому класі.
Важливо розуміти, що Google не просто випустила «ще одну модель». Компанія інтегрувала DiffusionGemma у реальну inference-інфраструктуру: нативна підтримка у vLLM, Hugging Face Transformers, MLX, оптимізація під NVIDIA Hopper та Blackwell. Це сигнал того, що Google ставиться до diffusion-підходу серйозно — не як до дослідницького артефакту, а як до потенційно продакшн-придатного напрямку.
Нова логіка генерації — і що вона відкриває
Autoregressive-підхід має принципове обмеження: модель не може «повернутися назад». Помилка у середині речення закріплюється, і всі наступні токени будуються на ній. DiffusionGemma може переглянути весь блок у процесі генерації — це фундаментально інша логіка.
На практиці це означає нові сценарії, де autoregressive-моделі традиційно слабкі:
Code infilling. Вставити функцію у середину файлу, дотримуючись контексту зверху і знизу — саме те, де двонаправлена увага дає реальну перевагу.
Структуровані формати. Генерація JSON, SQL або XML із жорсткими обмеженнями на структуру: diffusion-модель може «тримати в голові» кінцеву форму блоку і підганяти під неї весь текст одразу.
Редагування і доповнення. Заповнити прогалину у вже написаному документі, зберігаючи стиль і контекст до і після — autoregressive-моделям це дається важко, diffusion-підхід вирішує задачу природно.
Інтерактивні застосунки. Там де затримка критична — autocomplete у редакторі, live summarization, real-time translation — 1000+ токенів на секунду при локальному запуску відкривають можливості, недоступні раніше.
Для RAG-пайплайнів і агентних систем наслідки ще потрібно оцінити на практиці. Але сам факт появи альтернативної архітектури у production — з відкритими вагами, реальною інфраструктурою та підтримкою від Google — є значущим незалежно від поточних обмежень якості.
Що буде далі
Autoregressive-моделі у 2017 році також не були ідеальними. GPT-1 генерував зв'язний текст, але якість була далека від сучасних стандартів. За 8 років масштабування, покращення даних і нові архітектурні рішення перетворили трансформер на фундамент усієї індустрії.
Diffusion-підхід для тексту зараз — приблизно там, де autoregressive був у 2018–2019 роках. Є перший великий відкритий зразок. Є реальна перевага в конкретних сценаріях. Є структурні обмеження, які ще не подолані. І є відкрите питання: скільки часу і ресурсів потрібно, щоб diffusion-моделі наздогнали autoregressive за якістю?
Google не відповідає на це питання прямо. Але сам факт того, що DiffusionGemma вийшла під Apache 2.0 з повною інфраструктурною підтримкою — це не академічна публікація. Це заявка на те, що напрямок вартий серйозної уваги.
Що це означає для майбутнього LLM
Поки що DiffusionGemma — це експериментальна модель. Google не приховує, що за загальною якістю вона поступається стандартній Gemma 4. Для продакшн-задач, де важлива точність, autoregressive-моделі залишаються кращим вибором.
Але є кілька сигналів, що варто відстежувати:
Швидкість розвитку дифузійних моделей. Autoregressive-моделі масштабувалися роками, перш ніж досягли поточного рівня якості. Diffusion-підхід лише починає цей шлях.
Сценарії, де diffusion вже виграє. Локальний запуск, code infilling, interactive editing, завдання з низькою затримкою — тут перевага вже реальна.
Вплив на інфраструктуру. DiffusionGemma є першою нативно підтримуваною diffusion-моделлю у vLLM. Це означає, що інфраструктурний екосистем починає адаптуватися.
Конкуренти спостерігають. Inception Labs уже в цьому просторі. Якщо diffusion-підхід покаже стійке покращення якості — інші великі гравці почнуть вкладатися активніше.
DiffusionGemma — не революція, яка завтра замінить GPT і Llama. Але це перший серйозний публічний доказ того, що альтернативна архітектура для генерації тексту може працювати у реальних умовах. І це вже достатньо важливо.
Читайте далі в серії
Це перша стаття серії про DiffusionGemma та нову архітектуру мовних моделей.