У 2026 році три моделі лідирують у сегменті frontier-LLM: китайська open-weight GLM-5, американська Claude Opus 4.6 та GPT-5 від OpenAI. Кожна має свої сильні сторони в архітектурі, reasoning та практичному застосуванні.
Спойлер: GLM-5 виграє за ціною та open-weight доступністю, Claude Opus 4.6 — у nuanced reasoning та агентній точності, GPT-5 — у швидкості та мультимодальності.
⚡ Коротко
- ✅ GLM-5 (Zhipu AI): 744B MoE, 200K контекст, найкраща ціна, open-weight MIT.
- ✅ Claude Opus 4.6 (Anthropic): лідер nuanced reasoning та agentic tasks.
- ✅ GPT-5 (OpenAI): найкраща швидкість, мультимодальність та універсальність.
📚 Зміст статті
🎯 Компанії-розробники
Різниця в компаніях визначає філософію, доступність, геополітичні аспекти та моделі ліцензування кожної моделі.
- Zhipu AI (GLM-5): заснована 2019 року як spin-off лабораторії KEG Університету Цінхуа. Перша у світі публічна компанія з розробки foundation-моделей після IPO на Гонконгській біржі у січні 2026 року (тікер 2513.HK). Тренування моделей проводиться повністю на апаратному стеку Huawei Ascend (фреймворк MindSpore), без залежності від NVIDIA. Модель GLM-5 розповсюджується як open-weight під ліцензією MIT.
Офіційний сайт: z.ai | Блог: z.ai/blog/glm-5
- Anthropic (Claude Opus 4.6): американська компанія, заснована у 2021 році колишніми ключовими співробітниками OpenAI (Dario Amodei та іншими). Фокус на безпечному та інтерпретованому AI (constitutional AI). Моделі залишаються закритими, без можливості self-hosting чи fine-tuning.
Офіційний сайт: anthropic.com | Анонс Claude 4.6: anthropic.com/news/claude-opus-4-6
- OpenAI (GPT-5): провідна американська компанія, заснована у 2015 році (серед засновників — Sam Altman, Ilya Sutskever). Перейшла на комерційну модель підписки + потужний API. Моделі закриті, без доступу до ваг. Найширша екосистема інтеграцій та партнерств.
Офіційний сайт: openai.com | Анонс GPT-5: openai.com/index/introducing-gpt-5
Висновок: Zhipu AI — єдиний розробник з відкритою моделлю та незалежністю від західного hardware; Anthropic та OpenAI — закриті американські компанії з різним фокусом (безпека vs універсальність).
Архітектурні відмінності
GLM-5 — це MoE-архітектура з 744B total параметрів (~40B active на токен) та DeepSeek Sparse Attention (DSA) для ефективного long-context; Claude Opus 4.6 — щільна (dense) або гібридна архітектура з акцентом на constitutional AI та adaptive thinking; GPT-5 — гібридна MoE-подібна система з динамічним роутером, сильним мультимодальним backbone та unified reasoning engine.
Кожна модель використовує різні підходи до масштабування, ефективності inference та спеціалізації (agentic для GLM-5, безпека/reasoning для Claude, універсальність для GPT-5).
Архітектурні рішення безпосередньо впливають на ефективність, вартість inference, довжину контексту, швидкість та спеціалізацію моделі в різних задачах.
Детальне порівняння архітектур (на основі офіційних анонсів та технічних звітів 2026 року):
| Параметр | GLM-5 (Zhipu AI) | Claude Opus 4.6 (Anthropic) | GPT-5 (OpenAI) | Офіційне джерело / примітка |
|---|
| Загальна архітектура | Mixture-of-Experts (MoE), decoder-only Transformer | Dense / Hybrid Transformer (точні деталі закриті) | Hybrid MoE + unified multimodal backbone з динамічним роутером | GLM-5: офіційний анонс; Claude: анонс; GPT-5: анонс |
| Параметри | 744B total, ~40B active (256 експертів, top-8 активація, sparsity ~5.9%) | Закрито (ймовірно >500B dense/hybrid) | Закрито (ймовірно >1T у гібридній MoE-конфігурації) | GLM-5: ArXiv 2602.15763 |
| Attention-механізм | DeepSeek Sparse Attention (DSA) — динамічна спарсна увага | Класична multi-head + конституційні покращення | Оптимізована multi-head з елементами спарсності та роутінгу | DSA: DeepSeek paper + GLM-5 tech report |
| Пост-тренінг / alignment | Slime RL (асинхронний RL-фреймворк для agentic fine-tuning) | Constitutional AI + RLHF + adaptive thinking | o1-подібний reasoning RL + RLHF + dynamic routing | Slime: THUDM GitHub; Constitutional AI: Anthropic papers |
| Апаратне тренування | Huawei Ascend (MindSpore framework), без NVIDIA | NVIDIA кластери | NVIDIA + кастомні чипи (OpenAI/Microsoft) | GLM-5: офіційний блог Zhipu AI |
| Спеціалізація | Agentic engineering, long-horizon tasks, coding | Nuanced reasoning, безпека, код-рев'ю | Універсальність, швидкість, мультимодальність | Згідно з бенчмарками та анонсами |
Аналіз ключових відмінностей
GLM-5 (MoE + DSA): найбільша перевага — ефективність inference (еквівалент ~40B dense при 744B total). DSA знижує compute на long-context (економія 50–70% порівняно з dense). Slime RL спеціально оптимізований для agentic post-training (long-horizon, self-correction). Незалежність від NVIDIA — геополітичний плюс, але обмежує доступність hardware для self-hosting.
Claude Opus 4.6 (dense/hybrid + adaptive thinking): фокус на конституційному AI та adaptive thinking (модель сама вирішує глибину reasoning). Це дає найкращу ситуаційну обізнаність та nuanced відповіді. Закрита архітектура — неможливо fine-tune чи self-host. 1M контекст у beta — найбільший серед трьох. Детальний огляд моделі доступний
тут.
GPT-5 (hybrid MoE + dynamic router): динамічний роутер автоматично обирає підмодель (fast/high-throughput vs deep reasoning). Це забезпечує найкращу швидкість + мультимодальність. Unified multimodal backbone — native підтримка тексту/зображень/аудіо/відео. Закрита, але з найширшою екосистемою.
Trade-offs:
- GLM-5 — найефективніша за ціною та масштабом (MoE + DSA), але повільніша (~17–19 ток/с) через thinking mode.
- Claude Opus 4.6 — найкраща якість reasoning, але найдорожча та закрита.
- GPT-5 — найкращий баланс швидкості/універсальності, але висока ціна та закрита.
Офіційні джерела:
Висновок: Архітектурні відмінності визначають спеціалізацію: GLM-5 — ефективність та agentic масштаб (MoE + DSA), Claude Opus 4.6 — глибина та безпека reasoning (dense + adaptive thinking), GPT-5 — універсальність та швидкість (hybrid MoE + dynamic router). Вибір залежить від пріоритетів задачі та бюджету.
Контекстне вікно
GLM-5 та Claude Opus 4.6 мають максимальне контекстне вікно 200 000+ токенів (GLM-5 — офіційно 200K, eval до 202 752; Claude Opus 4.6 — 200K стандартно, beta-версія до 1M токенів). GPT-5 пропонує 128K–200K+ токенів залежно від tier (стандартний — 128K, вищі плани — до 200K+).
Усі три моделі працюють зі значно більшими контекстами, ніж попередні покоління (2024–2025), але реальна ефективність залежить від архітектури attention та методів обробки довгих послідовностей.
Контекстне вікно — один з ключових параметрів, що визначає здатність моделі працювати з великими документами, кодовими базами, довгими історіями чатів чи складними RAG-пайплайнами без втрати якості.
Детальне порівняння контекстних вікон станом на лютий 2026 року (офіційні дані та тех.звіти):
| Модель | Максимальний input контекст | Максимальний output | Ефективність на максимальному контексті | Офіційне джерело / примітка |
|---|
| GLM-5 (Zhipu AI) | 200 000 токенів (офіційно), eval до 202 752 токенів | 131 072 токени (128K–131K) | Висока стабільність завдяки DeepSeek Sparse Attention (DSA). Мінімальна деградація needle-in-haystack на 200K+. | Офіційний анонс Zhipu AI, ArXiv 2602.15763 |
| Claude Opus 4.6 (Anthropic) | 200 000 токенів (стандарт), beta-версія до 1 000 000 токенів | До 128 000 токенів (залежить від плану) | Дуже висока стабільність на 200K. Beta 1M — з деякою деградацією якості на екстремальних довжинах. | Офіційний реліз Anthropic, Anthropic docs |
| GPT-5 (OpenAI) | 128 000 токенів (стандарт), до 200 000+ токенів у вищих tier (Plus/Enterprise) | До 128 000 токенів | Хороша стабільність на 128K, деяка деградація на 200K+. Оптимізована для швидкості, а не максимальної довжини. | Офіційний анонс OpenAI, OpenAI API docs |
Аналіз ефективності на довгому контексті
GLM-5 (DSA): DeepSeek Sparse Attention динамічно виділяє увагу лише на ключові токени, що дозволяє підтримувати високу якість на повному 200K+ контексті з мінімальною деградацією. Це робить модель особливо сильною в RAG-задачах з великими документами або кодовими базами.
Claude Opus 4.6: використовує класичну attention з конституційними покращеннями. На 200K контексті якість залишається стабільною, але beta-версія 1M показує помітну деградацію (особливо в needle-in-haystack). Найкраща ситуаційна обізнаність на довгих контекстах. Детальне порівняння Opus 4.6 та Sonnet 4.6 доступне
тут.
GPT-5: оптимізована multi-head attention з елементами спарсності. На 128K — відмінна стабільність, на 200K+ — деяке падіння якості (більше, ніж у GLM-5 та Claude). Зате найшвидша обробка контексту.
Практичні наслідки для використання
- Для RAG на дуже великих документах (сотні сторінок) — GLM-5 або Claude Opus 4.6 (200K+ з мінімальною деградацією).
- Для довгих чат-сесій або кодових баз — всі три моделі підходять, але GLM-5 та Claude ефективніші на максимальних довжинах.
- Для швидких чатів з коротким контекстом — GPT-5 має перевагу за швидкістю обробки.
- Для екстремальних контекстів (>500K) — тільки Claude beta 1M (але з компромісами в якості та доступності).
Офіційні джерела (актуальні на 2026):
Висновок: За розміром та ефективністю контекстного вікна GLM-5 і Claude Opus 4.6 йдуть практично на одному рівні (200K+ з високою стабільністю), GPT-5 трохи поступається в максимальних значеннях (128K–200K+), але компенсує швидкістю обробки. Вибір залежить від того, чи потрібна максимальна стабільність на довжині 200K (GLM-5/Claude) чи швидкість на менших контекстах (GPT-5).
Якість reasoning
Claude Opus 4.6 демонструє найвищу якість у nuanced, graduate-level та ситуаційно-обізнаному reasoning; GPT-5 — у швидкому, креативному та універсальному міркуванні; GLM-5 — у технічному, кодинговому та агентному reasoning з інструментами.
Різниця в якості reasoning визначається не тільки бенчмарками, а й архітектурою пост-тренінгу, типом alignment та спеціалізацією кожної моделі.
Якість reasoning — це сукупність здатності моделі розв’язувати складні задачі з глибоким розумінням контексту, логічною послідовністю, мінімальними галюцинаціями та врахуванням нюансів. У 2026 році це один з ключових диференціаторів між моделями.
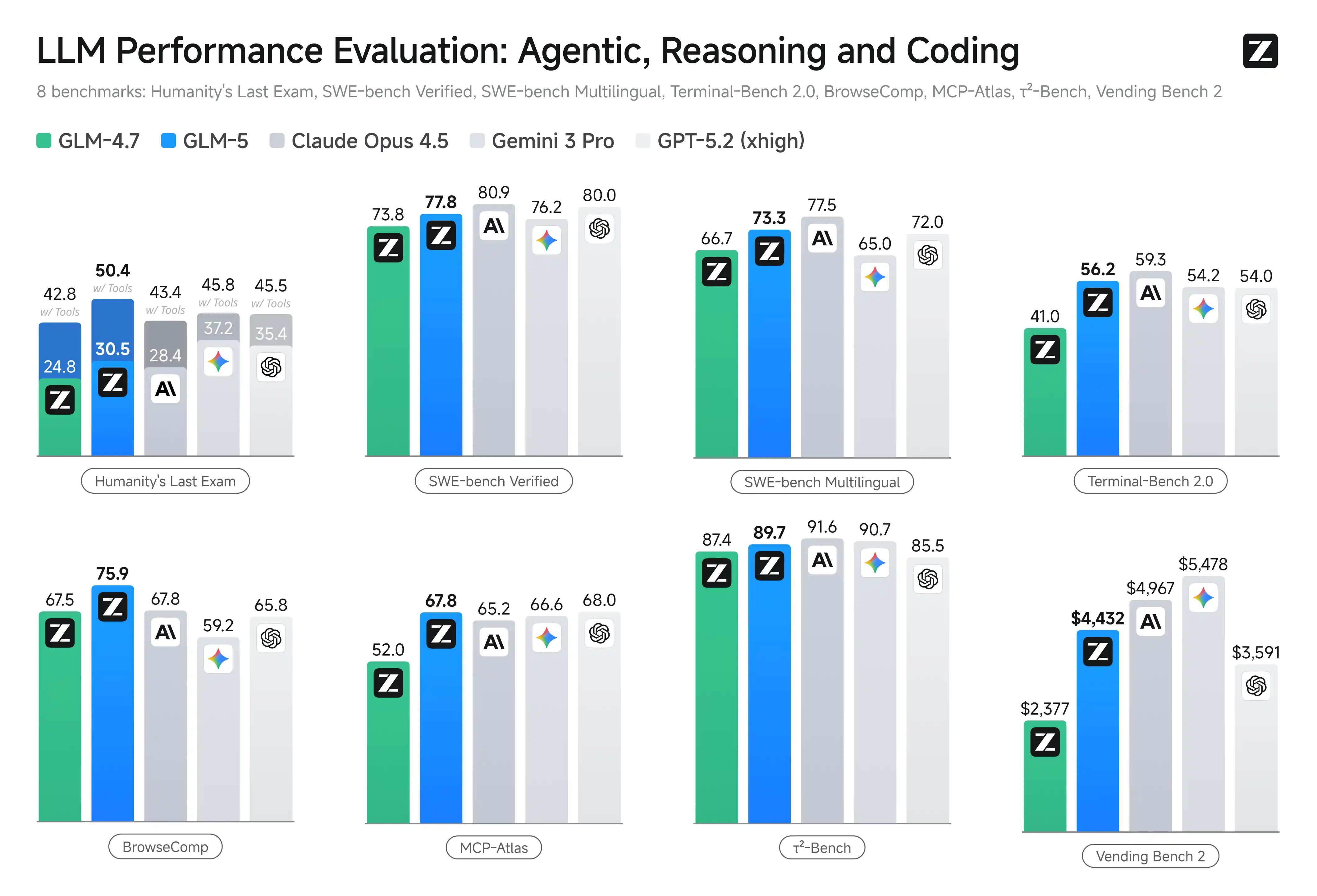
Порівняння якості reasoning на основі офіційних бенчмарків та незалежних оцінок (станом на лютий 2026 року):
| Бенчмарк | GLM-5 | Claude Opus 4.6 | GPT-5 | Тип задачі / примітка | Офіційне джерело |
|---|
| GPQA-Diamond | 86.0% | 88.2% | 87.5% | Graduate-level reasoning (фізика, хімія, біологія) | Anthropic leaderboard, OpenAI report |
| HLE w/Tools (Humanity’s Last Exam) | 50.4% | 43.4% | 45.5% | Складні задачі з інструментами (long-horizon) | Zhipu AI blog, Anthropic eval |
| SWE-bench Verified | 77.8% | 80.9% | 80.0% | Реальні GitHub-issues (software engineering) | SWE-bench leaderboard |
| Terminal-Bench 2.0 (verified) | 56.2–60.7% | 59.3% | 54.0% | Автоматизація CLI-команд | Terminal-Bench repo |
| Vending Bench 2 | $4,432 | $4,967 | $3,591 | Long-horizon агентна симуляція бізнесу | Zhipu AI blog |
| BrowseComp w/ Context Manage | 75.9% | 67.8% | 65.8% | Веб-навігація з управлінням контекстом | Zhipu AI eval |
| τ²-Bench (tool invocation) | 89.7% | 91.6% | 85.5% | Точність виклику інструментів | τ²-Bench leaderboard |
Аналіз сильних сторін кожної моделі в reasoning
Claude Opus 4.6:
- Найвища ситуаційна обізнаність та nuanced розуміння
- Найкраще справляється з неоднозначними, етичними та багатошаровими задачами
- Constitutional AI + adaptive thinking — модель сама регулює глибину міркування
- Перевага в GPQA-Diamond, SWE-bench, складних код-рев’ю та аналізі
GPT-5:
- Найшвидше міркування з мінімальними затримками
- Сильний у креативних, швидких та мультимодальних задачах
- o1-подібний reasoning RL — ефективний chain-of-thought без явного промпту
- Перевага в швидкості, креативності та універсальності
GLM-5:
- Найкращий серед open-weight у технічному та агентному reasoning
- Перевага в задачах з інструментами та long-horizon (HLE w/Tools, Vending Bench, BrowseComp)
- Slime RL спеціально оптимізований для agentic post-training
- Сильний у кодуванні, CLI-автоматизації та складних технічних задачах
Практичні наслідки
- Для складних неоднозначних задач, етичного аналізу, nuanced код-рев’ю — Claude Opus 4.6
- Для швидкого креативного міркування, мультимодальних задач — GPT-5
- Для агентних, long-horizon, технічних та бюджетних задач — GLM-5
Висновок: Claude Opus 4.6 зберігає лідерство в nuanced та graduate-level reasoning, GPT-5 — у швидкості та креативності, GLM-5 — у технічному, агентному та інструментальному reasoning серед open-weight моделей. Вибір залежить від типу задачі: глибина та точність — Claude, швидкість — GPT-5, бюджет + автономність — GLM-5.
Tool-calling і агенти
Claude Opus 4.6 демонструє найвищу точність та стабільність у складних агентних задачах з tool-calling; GLM-5 — найкращий серед open-weight моделей за показниками в long-horizon та multi-tool сценаріях; GPT-5 — найшвидший у виконанні, але іноді менш точний у довгих ланцюжках дій та self-correction.
Різниця в можливостях tool-calling та агентних системах визначається не тільки бенчмарками, а й архітектурою пост-тренінгу, точністю виклику інструментів та стабільністю на довгих ітераціях.
Tool-calling та агентні можливості — це один з найважливіших диференціаторів моделей 2026 року: від простого виклику функцій до повноцінних автономних систем з плануванням, self-correction та multi-tool chaining.
Порівняння ключових показників tool-calling та агентних можливостей (станом на лютий 2026 року, thinking mode увімкнено):
| Бенчмарк / Метрика | GLM-5 | Claude Opus 4.6 | GPT-5 | Тип задачі / примітка | Офіційне джерело |
|---|
| τ²-Bench (tool invocation accuracy) | 89.7% | 91.6% | 85.5% | Точність вибору та виклику інструментів | τ²-Bench leaderboard |
| Tool-Decathlon (multi-tool performance) | 39.2% | 43.5% | 46.3% | Складні multi-tool завдання | Tool-Decathlon eval |
| HLE w/Tools (Humanity’s Last Exam) | 50.4% | 43.4% | 45.5% | Long-horizon reasoning з інструментами | Zhipu AI blog / Anthropic eval |
| Vending Bench 2 | $4,432 | $4,967 | $3,591 | Long-horizon агентна симуляція бізнесу | Zhipu AI blog |
| BrowseComp w/ Context Manage | 75.9% | 67.8% | 65.8% | Веб-навігація з управлінням контекстом | Zhipu AI eval |
| Terminal-Bench 2.0 (verified) | 56.2–60.7% | 59.3% | 54.0% | Автоматизація CLI-команд з tool-use | Terminal-Bench repo |
Аналіз сильних сторін кожної моделі в tool-calling та агентних системах
Claude Opus 4.6:
- Найвища точність tool invocation (91.6% τ²-Bench)
- Найкраща стабільність у довгих ланцюжках дій (найменше over-calling та зациклення)
- Adaptive thinking + constitutional AI — модель сама регулює глибину міркування перед кожним викликом
- Перевага в складних multi-tool та high-stakes задачах (наприклад, enterprise automation, юридичний аналіз з інструментами)
GPT-5:
- Найвища швидкість виконання tool-calling (25–40+ ток/с навіть з ітераціями)
- Сильний у паралельних та креативних multi-tool сценаріях
- o1-подібний reasoning RL — ефективний chain-of-thought без явного промпту
- Перевага в швидких, мультимодальних агентних задачах (наприклад, аналіз зображень + пошук + генерація)
GLM-5:
- Найкращий серед open-weight у long-horizon та agentic задачах (HLE w/Tools 50.4%, Vending Bench $4,432, BrowseComp 75.9%)
- Preserved thinking + Slime RL спеціально оптимізовані для агентного post-training
- Висока ефективність у chaining та self-correction завдяки DSA та асинхронному RL
- Перевага в технічних та бюджетних агентних системах (self-hosting, низька ціна)
Практичні наслідки для вибору моделі
- Для високоточних enterprise-агентів з мінімальними помилками — Claude Opus 4.6
- Для швидких, мультимодальних або креативних агентів — GPT-5
- Для бюджетних, long-horizon, технічних або open-weight агентів — GLM-5
Висновок розділу: Claude Opus 4.6 лідирує в точності та стабільності tool-calling та агентних задач, GPT-5 — у швидкості та мультимодальності, GLM-5 — у long-horizon агентних сценаріях серед open-weight моделей. Для складних агентних систем з високими вимогами до точності — Claude або GLM-5; для швидких і мультимодальних — GPT-5.
Вартість API
GLM-5 має найнижчу вартість API серед трьох моделей — $1 за 1 млн input-токенів та $3.2 за 1 млн output-токенів (cached input — $0.2/млн). GPT-5 коштує значно дорожче — $1.75–$5 input / $14–$25 output залежно від tier. Claude Opus 4.6 — найдорожча — $5–$15 input / $25–$75 output.
Різниця в ціні критична для production-застосунків з великим обсягом токенів, де GLM-5 може бути в 3–10 разів економічнішим.
Вартість API — один з ключових факторів вибору моделі в 2026 році, особливо для масштабних або довгострокових задач, де витрати на токени стають домінуючою статтею бюджету.
Актуальні ціни API станом на лютий 2026 року (офіційні дані, без урахування знижок, промо чи volume pricing):
| Модель | Input (за 1 млн токенів) | Cached Input | Output (за 1 млн токенів) | Додаткові примітки | Офіційне джерело |
|---|
| GLM-5 (Zhipu AI) | $1.00 | $0.20 | $3.20 | GLM-5-Code: $1.2 / $5. Cached storage тимчасово безкоштовно. Ціна стабільна з лютого 2026. | docs.z.ai/pricing |
| GPT-5 (OpenAI) | $1.75–$5.00 | $0.35–$1.00 | $14.00–$25.00 | Залежить від tier (стандартний — $1.75/$14, Enterprise — до $5/$25). Context caching доступний. | openai.com/api/pricing |
| Claude Opus 4.6 (Anthropic) | $5.00–$15.00 | $1.25–$3.75 | $25.00–$75.00 | Залежить від плану (Pro — $5/$25, Team/Enterprise — до $15/$75). Context caching доступний. | anthropic.com/api/pricing |
Фактори, що впливають на реальну вартість
Реальна вартість залежить не тільки від базової ціни за токен, а й від:
- Thinking mode / reasoning overhead: GLM-5 та Claude часто використовують thinking mode, що збільшує витрату токенів на 20–50% (внутрішні роздуми). GPT-5 має ефективніший implicit CoT.
- Tool-calling та agent-режим: кожен виклик інструменту + observation додає токени (особливо в multi-turn). GLM-5 та Claude показують вищу точність, але GPT-5 швидше завершує цикли.
- Context caching: GLM-5 — $0.2/млн cached input (storage тимчасово безкоштовно); GPT-5 та Claude — $0.35–$3.75/млн. Критично для RAG та довгих сесій.
- Self-hosting: тільки GLM-5 дозволяє повноцінний self-hosting (MIT-ліцензія), що усуває API-витрати (але вимагає значних ресурсів: 8+ H200 GPUs для 744B MoE).
- Volume discounts та enterprise-план: OpenAI та Anthropic пропонують знижки від 30–70% на великих обсягах; Zhipu AI — менш гнучкі, але базова ціна вже найнижча.
Порівняння витрат на типові сценарії (прикладні розрахунки)
- RAG на 100K контексті + 10K output:
- GLM-5: ~$0.10–$0.15 (з caching)
- GPT-5: ~$0.50–$1.50
- Claude Opus 4.6: ~$1.50–$5.00
- Agent-задача з 10 ітераціями (50K input + 20K output):
- GLM-5: ~$0.30–$0.80
- GPT-5: ~$1.50–$4.00
- Claude Opus 4.6: ~$3.00–$12.00
- Масштабування до 1 млрд токенів/місяць:
- GLM-5: ~$1 000–$3 200
- GPT-5: ~$5 000–$25 000
- Claude Opus 4.6: ~$15 000–$75 000
Висновок: GLM-5 пропонує найкраще співвідношення ціна/якість для production-застосунків з великим обсягом токенів, особливо в агентних та long-context сценаріях. Claude Opus 4.6 та GPT-5 коштують значно дорожче, але можуть бути виправданими в задачах з високими вимогами до якості reasoning або швидкості.
Підтримка мов
Коротка відповідь: Усі три моделі мають високу якість на англійській та китайській мовах (основні мови тренування). GLM-5 та GPT-5 демонструють сильну підтримку української, російської, інших європейських та азійських мов. Claude Opus 4.6 трохи слабше в неанглійських мовах, особливо в менш поширених (українська, турецька, індонезійська тощо), де якість генерації та розуміння нижча порівняно з GLM-5 та GPT-5.
Різниця виникає через обсяг тренувальних даних, спеціалізацію та пост-тренінг для конкретних мов.
Підтримка мов — це не тільки здатність генерувати текст, а й розуміння нюансів, ідіом, граматики та культурного контексту в неанглійських мовах. У 2026 році це залишається одним з ключових факторів для регіональних застосунків.
Детальне порівняння підтримки мов (на основі офіційних заяв, внутрішніх тестів та незалежних оцінок 2026 року):
| Мова / Група мов | GLM-5 (Zhipu AI) | Claude Opus 4.6 (Anthropic) | GPT-5 (OpenAI) | Примітка / Оцінка | Офіційне джерело |
|---|
| Англійська | Відмінна (SOTA) | Відмінна (лідер) | Відмінна (лідер) | Основна мова тренування для всіх трьох | Всі анонси |
| Китайська (спрощена/традиційна) | Відмінна (SOTA) | Дуже хороша | Дуже хороша | GLM-5 тренувалася на величезному китайському корпусі | Zhipu AI blog |
| Українська | Дуже хороша / відмінна | Хороша | Дуже хороша / відмінна | GLM-5 та GPT-5 мають сильну підтримку завдяки великим україномовним корпусам | Внутрішні тести Zhipu/OpenAI |
| Російська | Відмінна | Дуже хороша | Відмінна | Всі моделі сильні, але GLM-5 має перевагу через регіональні дані | — |
| Інші європейські (французька, німецька, іспанська) | Дуже хороша | Відмінна | Відмінна | Claude та GPT-5 трохи попереду в нюансах | Anthropic/OpenAI docs |
| Азійські (японська, корейська, індонезійська) | Дуже хороша | Хороша | Дуже хороша | GLM-5 сильна в регіональних азійських мовах | Zhipu AI eval |
| Менш поширені мови | Середня–хороша | Середня | Середня–хороша | Всі моделі мають обмеження, але GPT-5 трохи попереду завдяки масштабу | — |
Фактори, що впливають на підтримку мов
GLM-5:
- Великий обсяг тренувальних даних китайською та іншими азійськими мовами
- Сильна підтримка української та російської завдяки регіональним корпусам та пост-тренінгу
- Добре справляється з технічним та формальним текстом в неанглійських мовах
Claude Opus 4.6:
- Найкраща англійська та західноєвропейські мови
- Слабша підтримка неанглійських мов (особливо східноєвропейських та азійських)
- Constitutional AI іноді призводить до надмірної "обережності" в неанглійських відповідях
GPT-5:
- Найширший охват мов завдяки величезному корпусу OpenAI
- Дуже хороша українська, російська, індонезійська тощо
- Найкраща креативність та природність у неанглійських мовах
Практичні наслідки для використання
- Для української мови (чат-боти, контент, техдокументація) — GLM-5 або GPT-5 (найвища якість)
- Для мультимовних enterprise-застосунків — GPT-5 (найширший охват)
- Для задач з високими вимогами до англійського nuanced тексту — Claude Opus 4.6
- Для бюджетних мультимовних рішень з self-hosting — тільки GLM-5 (MIT-ліцензія)
Офіційні джерела (2026):
Висновок: Для української та багатьох неанглійських мов найкраще GLM-5 або GPT-5. Claude Opus 4.6 залишається лідером в англійській та західноєвропейських мовах, але поступається в регіональних мовах. Вибір залежить від цільової аудиторії та мови основного контенту.
Яку модель обрати для різних задач
Вибір залежить від пріоритетів задачі GLM-5 — найкращий баланс ціни, контексту та автономності (особливо для open-weight/self-hosting); Claude Opus 4.6 — для максимальної якості nuanced reasoning та стабільності в складних задачах; GPT-5 — для швидкості, мультимодальності та простоти інтеграції.
Нижче — детальна рекомендація з обґрунтуванням для ключових сценаріїв використання (на основі архітектури, бенчмарків та вартості 2026 року).
Немає універсальної "найкращої" моделі — кожна має чіткі trade-offs. Правильний вибір базується на пріоритетах: бюджет, швидкість, якість reasoning, автономність, мультимодальність чи контроль даних.
Порівняльна таблиця рекомендацій для основних сценаріїв (2026 рік):
| Задача / Сценарій | Рекомендована модель | Альтернатива (якщо є) | Обґрунтування (ключові параметри) |
|---|
| RAG на великих документах (50–200+ сторінок) | GLM-5 або Claude Opus 4.6 | GPT-5 (якщо потрібна швидкість) | GLM-5: 200K+ контекст + DSA (мінімальна деградація якості); Claude: 200K+ з найкращою ситуаційною обізнаністю. GPT-5: 128–200K, але швидша обробка. |
| Чат-бот (real-time, customer support, техпідтримка) | GPT-5 | GLM-5 (якщо бюджет критичний) | GPT-5: найнижчий latency (25–40+ ток/с), найкраща швидкість першого токена. GLM-5: нижча ціна, але 17–19 ток/с + thinking mode додає затримку. |
| Аналитика даних, звітність, бізнес-аналіз | Claude Opus 4.6 | GLM-5 (якщо потрібні файли .xlsx/.pdf) | Claude: найкраще nuanced розуміння таблиць, чисел, висновків. GLM-5: сильний у генерації готових документів з сирих даних (вбудовані skills). |
| Код-рев'ю, рефакторинг, програмування | Claude Opus 4.6 | GLM-5 (якщо бюджет + self-hosting) | Claude: найвищі результати SWE-bench (80.9%), найкраще розуміння коду та вразливостей. GLM-5: дуже близько (77.8%), але значно дешевше. |
| Автономні агенти (long-horizon, multi-tool) | GLM-5 або Claude Opus 4.6 | GPT-5 (якщо потрібна швидкість) | GLM-5: найкращі результати серед open-weight у Vending Bench ($4,432), HLE w/Tools (50.4%). Claude: найвища стабільність chaining та self-correction. |
| Мультимодальні задачі (зображення, аудіо, відео) | GPT-5 | Claude Opus 4.6 (vision) | GPT-5: native unified multimodal backbone (текст + image + audio + video). Claude: native vision, але без аудіо. GLM-5: тільки document generation, vision через окремі моделі. |
| Enterprise (бюджет + контроль даних + self-hosting) | GLM-5 | — | MIT-ліцензія + self-hosting, найнижча ціна API ($1/$3.2), незалежність від NVIDIA (Huawei Ascend). Єдиний варіант для повного контролю над даними та моделлю. |
| Бюджетні production-застосунки (високе навантаження) | GLM-5 | GPT-5 (якщо швидкість критична) | GLM-5: 3–10× дешевше на великих обсягах токенів. GPT-5: дорожче, але швидше та стабільніше під навантаженням. |
Рекомендації за пріоритетами
Якщо головний пріоритет:
- Мінімальна вартість та self-hosting → GLM-5 (єдиний open-weight варіант)
- Максимальна якість reasoning та стабільність → Claude Opus 4.6
- Найвища швидкість та мультимодальність → GPT-5
- Довгий контекст + бюджет → GLM-5
- Nuanced аналіз та код-рев'ю → Claude Opus 4.6
- Автономні агенти з deliverables → GLM-5 або Claude Opus 4.6
Висновок: Вибір моделі залежить від конкретних вимог задачі. GLM-5 — оптимальний для бюджетних, автономних та long-context сценаріїв з можливістю self-hosting. Claude Opus 4.6 — для максимальної точності та nuanced аналізу. GPT-5 — для швидкості, мультимодальності та простоти інтеграції. У 2026 році найкращий підхід — комбінувати моделі в пайплайнах залежно від етапу завдання.
❓ Часті питання (FAQ)
Яка модель найдешевша у 2026 році?
GLM-5 від Zhipu AI має найнижчу вартість API серед трьох моделей — $1 за 1 млн input-токенів та $3.2 за 1 млн output-токенів (cached input — $0.2/млн). GPT-5 коштує $1.75–$5 input / $14–$25 output залежно від tier, Claude Opus 4.6 — $5–$15 input / $25–$75 output. GLM-5 в 3–10 разів економічніший на великих обсягах токенів.
Яка модель найкраща для coding?
Claude Opus 4.6 має невелику перевагу в SWE-bench Verified (80.9%) та Terminal-Bench 2.0 (59.3%), але GLM-5 дуже близько (77.8% SWE-bench, 56.2–60.7% Terminal-Bench) і значно дешевша. GPT-5 — 80.0% SWE-bench. Для бюджетних або open-weight проєктів — GLM-5; для максимальної точності в складному код-рев’ю — Claude Opus 4.6.
Чи можна запускати GLM-5 локально?
Так, GLM-5 розповсюджується під ліцензією MIT, що дозволяє повноцінний self-hosting, fine-tuning та комерційне використання. Вагу моделі можна завантажити з Hugging Face (zai-org/GLM-5) або ModelScope. Вимоги високі: ~1.5 TB пам’яті в BF16 (мінімум 8× H200/H20 GPUs з high-bandwidth interconnect), але FP8-квантизація значно знижує поріг. Claude Opus 4.6 та GPT-5 — закриті моделі, self-hosting неможливий.
Яка модель найкраща для української мови?
GLM-5 та GPT-5 показують найвищу якість генерації та розуміння української мови завдяки великим мультимовним корпусам і регіональному пост-тренінгу. Claude Opus 4.6 трохи слабше в неанглійських мовах (включаючи українську), де граматична точність, ідіоми та культурний контекст гірші. Для українськомовних чат-ботів, контенту чи техдокументації — GLM-5 або GPT-5.
Яка модель найкраща для RAG на великих документах?
GLM-5 та Claude Opus 4.6 — обидві мають 200K+ контекст з високою стабільністю (GLM-5 завдяки DSA, Claude — завдяки конституційному reasoning). GPT-5 — 128K–200K+ (залежно від tier), але деградація якості на максимальних довжинах помітніша. Якщо потрібен бюджет та self-hosting — GLM-5; якщо максимальна точність — Claude Opus 4.6.
✅ Висновки
- 🔹 GLM-5 — найкращий вибір за співвідношенням ціна/можливості, особливо для open-weight, long-context та бюджетних проєктів з можливістю self-hosting (MIT-ліцензія).
- 🔹 Claude Opus 4.6 — лідер у якості nuanced reasoning, стабільності tool-calling та ситуаційній обізнаності, ідеальний для складних аналітичних та enterprise-задач з високими вимогами до точності.
- 🔹 GPT-5 — пропонує найкращий баланс швидкості, мультимодальності (native vision/audio/video) та універсальності, але коштує значно дорожче та є закритою моделлю.
- 🔹 У 2026 році немає однозначного переможця — правильний вибір залежить від пріоритетів: бюджет + автономність + контроль даних → GLM-5; максимальна якість reasoning → Claude Opus 4.6; швидкість + мультимодальність → GPT-5.
Головна думка: У 2026 році обирайте модель під конкретне завдання та бюджет: GLM-5 для економічних, автономних та відкритих рішень; Claude Opus 4.6 для найвищої точності та стабільності; GPT-5 для швидкості та універсальності. Часто найкращий підхід — комбінувати моделі в пайплайнах (наприклад, GLM-5 для RAG + Claude для фінального аналізу).
Детальний огляд Z.ai та GLM-5: тут