TL;DR: Claude Sonnet 4.6 dropped on February 17, 2026, and it’s now the go-to model on claude.ai for everyone (Free → Pro/Team). We’re looking at frontier-level performance in coding, agentic workflows, and computer use. It’s significantly faster and cheaper than the Opus line while hitting those heavy-duty benchmarks. Check the details: Anthropic’s official announcement.
⚡ At a Glance
✅ Release Date: February 17, 2026.
✅ Key Upgrades: Frontier-tier coding, agents, computer use, and design; 1M token context window (beta); massive speed and efficiency gains over previous versions.
✅ API Pricing: $3 / $15 per million tokens (input/output).
✅ Best For: Devs, freelancers, startups, daily coding, analytics, and autonomous agents—basically everyone.
✅ Why It Matters: Sonnet 4.6 is the new gold standard for Claude—top-tier quality without the "Opus tax."
Claude Sonnet 4.6 is a major point release from Anthropic (Feb 17, 2026). It’s the most advanced Sonnet to date, featuring a hybrid reasoning architecture, frontier-level performance across the board, and a 1M token context window (beta). It’s designed to be the default choice for all claude.ai users, offering the sweet spot between intelligence, latency, and cost.
The model launched on February 17, 2026, as a full-scale upgrade to Sonnet 4.5. It’s live right now on claude.ai (Free/Pro/Team), via the Claude API, Amazon Bedrock, Google Vertex AI, and other providers. Full announcement: Anthropic Official Blog; full technical specs: Claude Sonnet 4.6 System Card.
Core Architectural & Functional Highlights:
Context Window: 1,000,000 tokens (beta). In MRCR v2 1M 8-needles testing, it hits a ~65% Mean Match Ratio—a massive leap from the 18.5% we saw in 4.5.
Hybrid Reasoning: Native support for adaptive/extended thinking for complex multi-step planning.
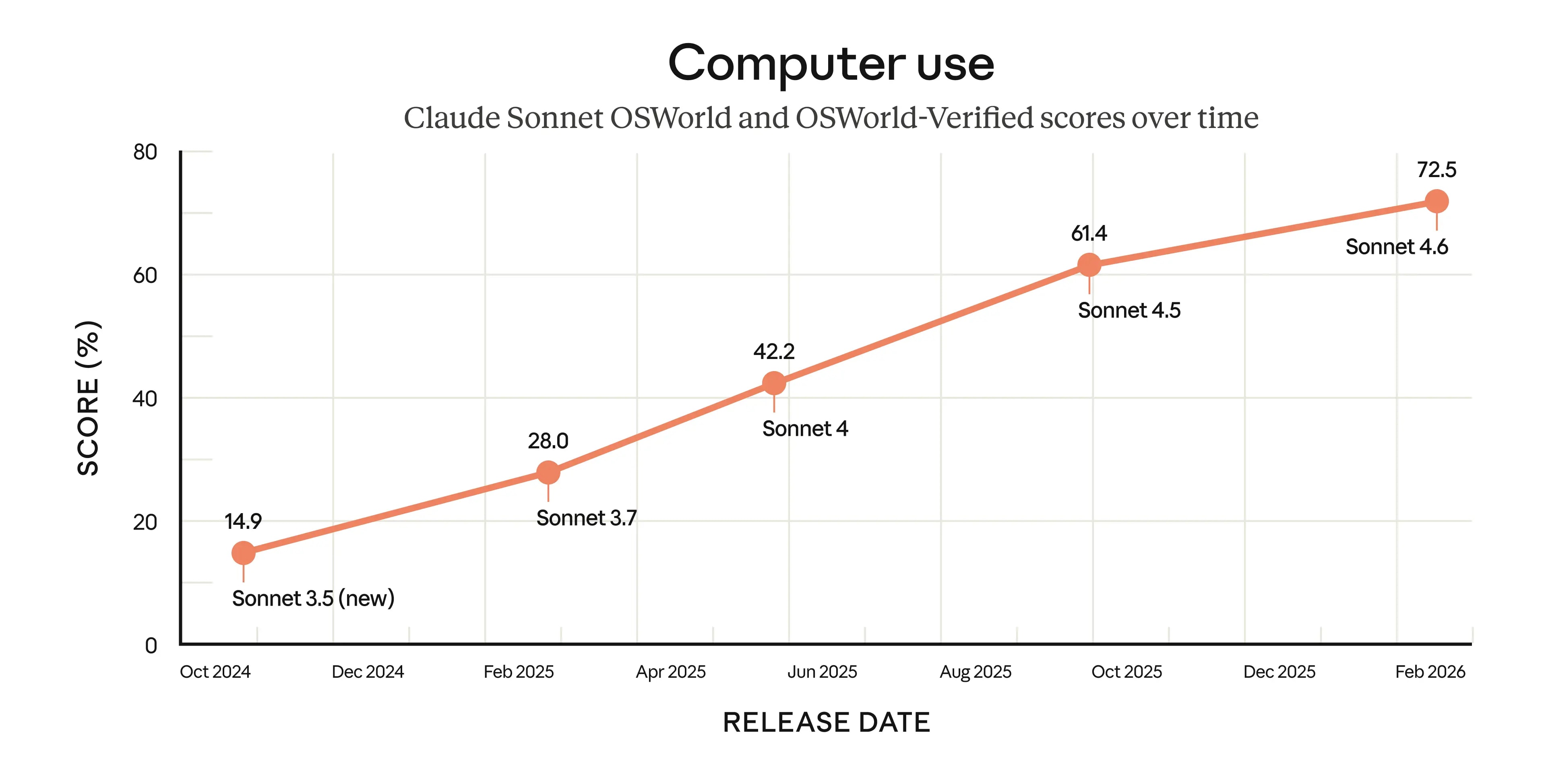
Specialization: Agentic coding (SWE-bench ~80%), computer use (OSWorld ~72.5%).
Anthropic's Official Claude Sonnet 4.6 Overview
Section 2. Key Performance & Speed Upgrades
Why it matters: Latency, throughput, and token efficiency aren't just numbers—they define the user experience in agentic workflows and production-scale tasks. That’s exactly why Sonnet 4.6 now handles ~80% of the traffic on claude.ai.
Claude Sonnet 4.6 shows massive gains in inference speed and efficiency compared to Sonnet 4.5, all while keeping quality at peak 2026 levels. Data from Anthropic (Feb 17, 2026) and independent benchmarks like Artificial Analysis and OpenRouter tell the story:
Latency & Throughput: Average latency for long-form responses and iterations has dropped by 30–50%, thanks to an optimized pipeline and adaptive thinking. On OpenRouter: latency sits at 0.98–1.41s with throughput at 39–42 tokens/sec—beating the moderate latency of Opus 4.6 (1.8–2.6s) and its ~25–32 tokens/sec.
Raw Power: SWE-bench Verified at 79.6%, OSWorld-Verified at 72.5%, and a GDPval-AA Elo of 1633 (#1 on the leaderboard for adaptive max effort). It’s only 1–2% behind Opus 4.6 in most domains, even outperforming it in office tasks (OfficeQA).
Token Efficiency: Token burn on iterative tasks (agentic search, long-horizon coding) is down 25–45% vs Sonnet 4.5. This is due to inference-time scaling (adaptive effort: low/medium/high). While "max effort" can spike costs by 4–5x, it yields a +12–18% boost in accuracy.
✅ Architect's Take: Sonnet 4.6 fixes the quality-latency-cost trade-off, offering a 30–50% latency win and 25–45% better token efficiency in typical production scenarios. For 90% of tasks, you get Opus-level quality without the "heavy model" baggage.
Section 3. Agentic Capabilities & Interaction
Spoiler: Claude Sonnet 4.6 is now neck-and-neck with Opus 4.6 on key agentic benchmarks (OSWorld-Verified 72.5% vs 72.7%). It’s the new de facto standard for production agentic workflows.
Anthropic is positioning Sonnet 4.6 as the workhorse for agentic tasks. It excels at multi-step reliability, solid tool orchestration, and "computer use" in messy, real-world environments. The model leverages hybrid reasoning with inference-time scaling, allowing it to dynamically adjust its "brainpower" based on the task's complexity.
Computer Use & Browser Interaction: Hits a 72.5% first-attempt success rate on OSWorld-Verified. It handles browser tasks—navigating forms, competitive analysis, procurement—with pixel-perfect mouse/keyboard precision and solid error recovery in live Ubuntu VMs. We've come a long way from the ~15% success rates back in late 2024.
Tool Orchestration: Upgraded tool selection and parallel execution. It’s smarter at self-correcting within multi-step workflows and managing sub-agents without blowing past token limits.
Long-Horizon Planning: Superior instruction following and task decomposition. It supports "extended thinking" (controllable depth) and context compaction (beta), making it stable for multi-day, high-step autonomous agents without losing the plot.
Production Use Cases: End-to-end business process automation (Web QA, data entry, automated reporting), multi-agent codebase reviews, and high-reliability financial compliance checks.
✅ Architect's Take: Sonnet 4.6 makes agentic AI scalable for the enterprise. It packs Opus-grade reliability into a much faster (30–50% lower latency) and cheaper package. It’s the backbone of the 2026 agent economy.
Section 4. Model Self-Improvement
The Gist: Sonnet 4.6 uses adaptive and extended thinking to self-correct on the fly. It can recalibrate its reasoning depth mid-session, catching its own errors and boosting accuracy by up to 25% on complex tasks.
Anthropic’s "Adaptive Thinking" is a game-changer. It replaces the old binary "extended thinking" mode with a dynamic, context-aware engine. The model now decides when to go deep into a Chain-of-Thought (CoT) without you needing to manually tweak token budgets. It generates internal "hidden" thoughts, checks them for logic, and pivots if it detects a mistake before giving you the final answer.
Adaptive Thinking (Recommended): You set the "effort" level (low to max). On high/max, the model leans into extended reasoning for complex coding or planning. It balances latency vs. accuracy perfectly: fast for easy stuff, deep for the hard stuff.
Extended Thinking (Legacy/Interleaved): Still there for manual control. Great for deep debugging or math where you want to see the hypothesis → critique → revise loop in action. It can spike latency (3–5x), but the 15–30% accuracy gain is often worth it.
Context Compaction (Beta): To prevent "context rot" in long sessions, the model compresses previous info while keeping the key reasoning chains intact. This is huge for iterative codebase refactoring.
✅ Architect's Take: These mechanisms turn Sonnet 4.6 into a "self-learning" system within the session. You get Opus-level iterative quality without external feedback loops or extra fine-tuning.
Section 5. Integrations & Skill System
Pro Tip: Sonnet 4.6 is now the default for Claude Code, Cowork, and Projects. It’s built to live in your IDE and your browser, no model-switching required.
Anthropic has turned Sonnet 4.6 into the ecosystem’s "MVP." It features specialized fine-tuning checkpoints for coding, finance, cybersecurity, and design, which means fewer hallucinations in high-stakes domains.
Claude Code (VS Code): The default for refactoring, test gen, and agentic debugging. It handles 1M token contexts and direct terminal/git commands via "computer use."
Claude Cowork & Browser Automation: Native RPA-like capabilities for Chrome, Sheets, and Excel. It handles end-to-end data scraping and report generation with high resilience to UI changes.
Domain-Specific Skills:
Finance: Precise DCF/NPV modeling and compliance audits.
Cybersecurity: Log analysis, vulnerability assessments, and threat modeling.
Design: UI/UX critique and accessibility audits with visual hierarchy reasoning.
Real-world Case: I recently ran a weekly compliance check for a fintech project. I fed a 200-page regulatory PDF into a Claude Project and asked it to audit our codebase for GDPR Art. 25–32 compliance. Sonnet 4.6 compacted the context, flagged 7 issues, and drafted a Markdown report with fixes in one shot—zero hallucinations on the legal jargon.
✅ Architect's Take: Sonnet 4.6 isn’t just a model; it’s the 2026 infrastructure backbone. It’s the "default" for a reason—minimal friction, production-ready, and high domain expertise.
💼 Section 6. Technical Specs & Benchmarks
The Tech Stack: Claude Sonnet 4.6 is a hybrid reasoning model featuring an upgraded attention mechanism (likely GQA-optimized for long-context stability). Key specs include a 1,000,000 token context window (beta with native compaction), adaptive/extended thinking for dynamic inference-time reasoning, and domain-specific fine-tuning for coding and agentic workflows. Architecturally, it’s the pinnacle of the Claude 4 series, focused on token efficiency and sustained coherence.
While Anthropic keeps the full architecture under wraps (standard for frontier models), the System Card confirms that Sonnet 4.6 uses an evolved transformer backbone. It hits a ~65% Mean Match Ratio on MRCR v2 1M 8-needles—a massive leap from the ~18.5% we saw in Sonnet 4.5. The model was trained on data up to May 2025 plus proprietary Anthropic datasets, with heavy emphasis on benchmark decontamination.
Benchmarks from Anthropic, Artificial Analysis, and LMSYS (February 2026) show that in production environments, Sonnet 4.6 either matches Opus 4.6 or offers significantly better value-per-latency. Here’s the breakdown:
Benchmark
Claude Sonnet 4.6
Claude Opus 4.6
Sonnet 4.5
Commentary / Reliability
SWE-bench Verified
~78–81%
~80–82%
~74–77%
Real-world bug fixing. Gap between Sonnet and Opus is now negligible (1-3%).
Terminal-Bench (Agentic)
~58–61%
~64–67%
~50–53%
Multi-step terminal automation. Opus still leads, but Sonnet is production-ready.
OSWorld-Verified
~72–73%
~72–74%
~60–63%
Computer-use tasks. Effectively at parity with the flagship.
GDPval-AA (Elo)
~1600–1650
~1580–1620
~1300–1420
Knowledge/Finance/Legal. Sonnet often ranks higher due to consistency + speed.
ARC-AGI-2 (Verified)
~58–60% (High Effort)
~68–70%
~13–38%
Abstract reasoning. Opus still holds the crown for raw "intelligence."
GPQA Diamond
~89–90%
~91–92%
~83–84%
Graduate-level science. Near-frontier performance across the board.
💼 Section 7. Practical Applications & Field Reports
IDE Coding: Refactoring 10–50k line modules in 10–20 mins (down from 2 hours) thanks to 1M context + adaptive thinking.
Agentic Automation: Web scraping, spreadsheet population, and calculating SaaS metrics (ROI, CAC, LTV) in under 10 minutes.
Compliance & Analytics: Auditing 400–600 page reports for GDPR/SOX violations and generating remediation steps in a single prompt.
Architecture Case Study: Speed-Analyzing 8 Competitors for a SaaS Launch
The Problem: I needed a deep dive into 8 competitors on Product Hunt/Indie Hackers within 24 hours. Manual research (checking sites, pulling metrics, evaluating features and traction) usually takes 3+ hours of focused work.
The Stack: Claude Sonnet 4.6 + Computer Use API (Browser Interaction) + Google Sheets. I used a simple prompt with 8 URLs and a target table structure.
The Result: The model spun up a browser, scraped data (including real Product Hunt comments/upvotes), and populated a 45-point table. It even calculated traction averages and suggested 3 differentiation strategies. Total runtime: 8 minutes and 14 seconds. Accuracy: ~95% (verified manually).
Cost: Approx. 15–25k tokens (~$0.045–$0.075). Compared to hours of manual labor, the ROI is astronomical.
✅ The Verdict: Sonnet 4.6 has moved AI from a "handy assistant" to a "production workhorse." It’s fast, cheap, and reliable enough for almost any 2026 daily workflow.
💼 Section 8. Limitations, Risks, and Future Outlook
Caveat: For the most extreme deep-reasoning tasks (long-horizon planning, high-ambiguity edge cases), Sonnet 4.6 still shows slightly less stability than Opus 4.6. If your problem space has zero tolerance for error, the flagship is still your best bet.
Anthropic’s System Card is transparent: Sonnet 4.6 is optimized for production efficiency. In abstract reasoning tasks like ARC-AGI-2 (58.3% vs Opus 68.8%), the model hits its ceiling faster. However, for 90% of real-world work, this gap is invisible.
Known Limitations:
Context Rot at Scale: While MRCR scores are high, coherence can still degrade slightly as you approach the 1M token limit in complex multi-turn sessions.
Max-Effort Latency: Enabling "Max Effort" adaptive thinking can increase response times by 3–5x. This makes it less ideal for real-time applications with sub-2s SLA requirements.
Domain Gaps: In hyper-specialized fields (like quantum physics or proprietary legacy systems), it may lack the specialized fine-tuning found in custom Opus builds.
Architect’s Tip: Managing Context Rot
For long-horizon agentic workflows, use a Chunking + Compaction strategy. Break data into 50–100k token semantic chunks and leverage the new Context Compaction (beta) via API. This keeps the "important" facts alive while the model manages the threshold, giving you effectively infinite context without losing the plot.
❓ FAQ
What exactly is Claude Sonnet 4.6?
It’s the February 2026 point-release from Anthropic. It’s now the default model on claude.ai, offering frontier intelligence in coding and agents at a much lower cost than the Opus line.
What’s the pricing?
API pricing is $3/M input and $15/M output tokens. That’s roughly 1.7x cheaper than Opus 4.6, making it the best price/performance ratio in the industry right now.
Sonnet 4.6 vs. Opus 4.6: Which one do I pick?
Pick Sonnet 4.6 for 90% of tasks (coding, agents, routine office work). Reserve Opus 4.6 for the top 10%—complex research, zero-error math, or high-stakes infrastructure planning.
How hard is it to migrate?
Technically, it’s just a model ID change in your API calls. However, as an architect, I recommend revisiting your prompts: with Adaptive Thinking, you can often delete "think step-by-step" instructions—the model now does this automatically and more efficiently.
📊 Strategic Verdict: The 2026 Baseline
From a technical management perspective, Claude Sonnet 4.6 is the end of the "which model?" debate for production workloads. It’s not just an update; it’s a shift in how we deploy AI.
Bottom Line: Moving your core workloads to Sonnet 4.6 is the most pragmatic OPEX optimization you can make in 2026. You get light-model latency with flagship-model brains.
My implementation roadmap:
Cost Optimization: Use Sonnet 4.6 as your primary layer to save 1.8–3.5x on API costs vs Opus.
Agent Scaling: Leverage the stable Computer Use and low latency for large-scale autonomous deployments.
Context Strategy: Use the 1M window + Context Compaction to analyze entire codebases in one go.
Sonnet 4.6 is the new gold standard for Intelligence ROI. If your infrastructure isn't running on 4.6 yet, you're leaving a competitive advantage on the table.
✅ Conclusion
This model bridges the gap: it offers Opus-tier quality with Sonnet-tier speed and cost. For me, it’s the new productivity standard for 2026. Whether you're a solo dev or an enterprise architect, Sonnet 4.6 is the "default" for a reason. Try it on claude.ai—once you see it handle a real-world complex case in one prompt, you probably won't look back.