Розділ 2. Ключові покращення продуктивності та швидкості
Чому це важливо? Latency, throughput та token efficiency безпосередньо визначають user experience в agentic workflows, iterative development та production-scale задачах — саме тому Sonnet 4.6 став дефолтним для ~80% трафіку на claude.ai.
Claude Sonnet 4.6 показує помітний прогрес у швидкості інференсу та ефективності порівняно з Sonnet 4.5, зберігаючи якість на рівні топ-моделей 2026 року. Офіційні дані Anthropic (реліз 17 лютого 2026) та незалежні тести (Artificial Analysis, OpenRouter) дають такі цифри:
- Latency та throughput: Середня затримка на довгих відповідях та ітераціях знизилася на 30–50% завдяки оптимізованому inference pipeline та adaptive thinking. На OpenRouter: latency 0.98–1.41 с, throughput 39–42 токенів/с — проти moderate latency Opus 4.6 (1.8–2.6 с) та ~25–32 токенів/с.
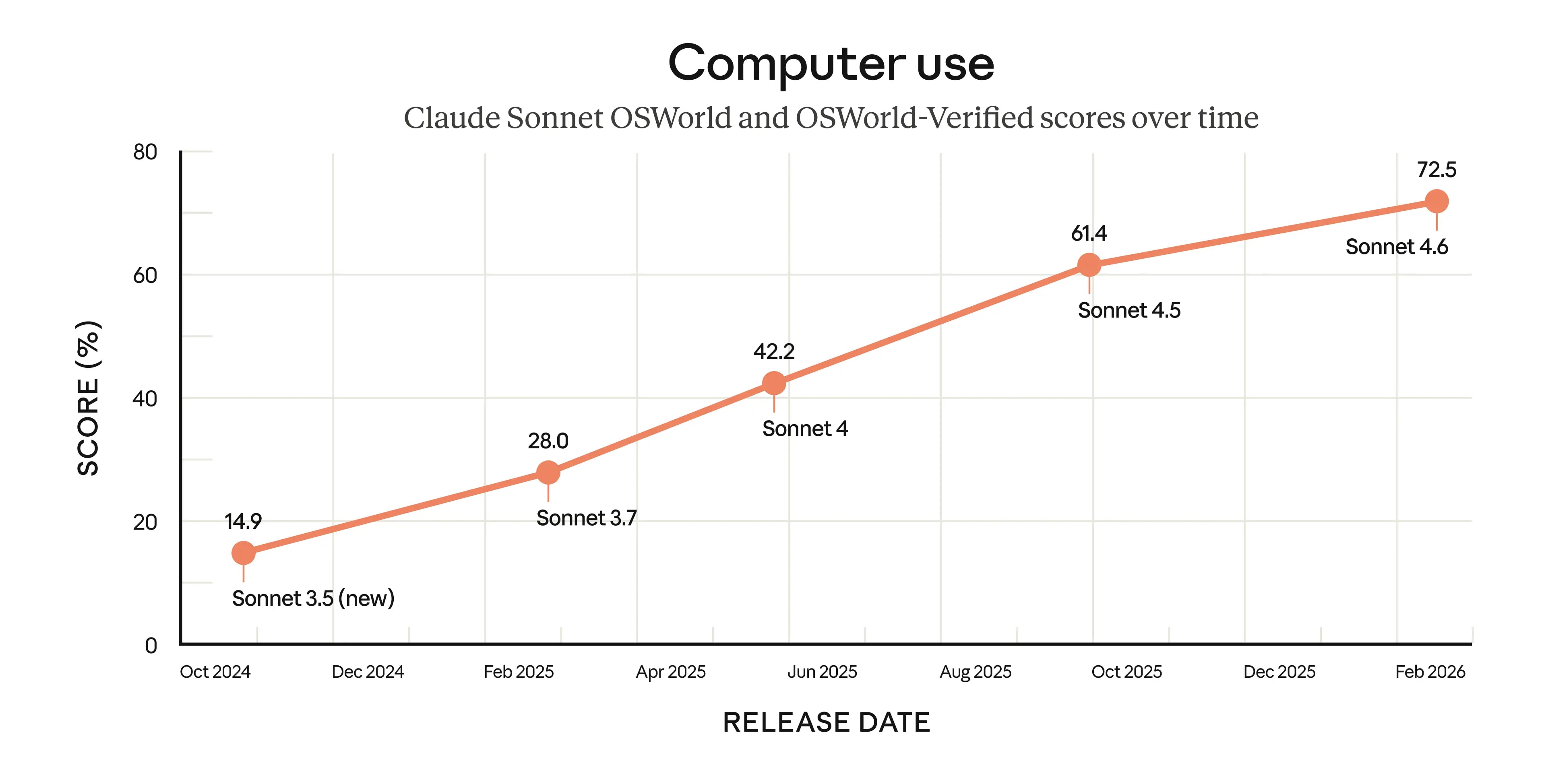
- Продуктивність: SWE-bench Verified 79.6%, OSWorld-Verified 72.5%, GDPval-AA Elo 1633 (#1 на leaderboard в adaptive max effort) — відставання від Opus 4.6 становить лише 1–2% у більшості доменів, з вищою token efficiency в knowledge work та office-задачах (OfficeQA на рівні або краще Opus).
- Token efficiency: Витрата токенів на ітеративні завдання (agentic search, long-horizon coding) зменшилася на 25–45% порівняно з Sonnet 4.5 завдяки inference-time scaling (adaptive effort: low/medium/high). У GDPval-AA тестах max effort може збільшити витрату в 4–5×, але дає +12–18% точності.
Детальніше про inference-time scaling та effort controls: офіційна документація Anthropic.
✅ Ключова думка: Я думаю, що Sonnet 4.6 покращує trade-off quality-latency-cost приблизно на 30–50% за latency та на 25–45% за токенами в типових production-сценаріях. За даними Anthropic, Artificial Analysis та OpenRouter, модель у більшості задач дає паритет з Opus 4.6 у ~80–90% доменів, але з нижчою середньою латентністю та меншою витратою токенів.
Розділ 3. Агентні можливості та взаємодія
Спойлер: Claude Sonnet 4.6 наблизився до Opus 4.6 на ключових agentic-бенчмарках (OSWorld-Verified 72.5% vs 72.7%) і став де-факто стандартом для production agentic workflows завдяки нижчій латентності та вищій token efficiency.
Anthropic позиціонує Sonnet 4.6 як модель з високою продуктивністю в agentic задачах, з акцентом на стійке виконання багатоступеневих завдань, надійне tool orchestration та computer use в реальних середовищах. Згідно з релізом 17 лютого 2026 та System Card, модель інтегрує hybrid reasoning з inference-time scaling (adaptive/extended thinking), що дозволяє динамічно регулювати глибину міркування залежно від складності завдання.
Ключові архітектурні та функціональні покращення в агентних можливостях:
- Computer Use та Browser Interaction: OSWorld-Verified 72.5% first-attempt success rate (averaged over 5 runs, 1080p, max 100 steps) — практично паритет з Opus 4.6 (72.7%). Модель виконує браузерні завдання (навігація, форми, competitive analysis, procurement, onboarding) з точністю mouse/keyboard actions та error recovery в live Ubuntu VM. Еволюція від ~15% у Claude 3.5 Sonnet (жовтень 2024) до поточного рівня. Деталі: System Card, розділ 2.6 OSWorld-Verified.
- Tool Use та Orchestration: Покращена tool selection, parallel execution та self-correction в multi-step workflows. Підтримка Claude API tools (bash, web search, computer-use), inference-time scaling для автоматичного визначення глибини reasoning. Ефективне керування subagents у multi-agent setups з компактним context management (token overflow уникнення).
- Agentic Planning та Long-Horizon Tasks: Superior instruction following, розбиття завдань на independent subtasks, виявлення blockers та adaptive decision-making. Підтримка extended thinking (controllable depth) та context compaction (beta) для стійкості в multi-day/high-step задачах. Ідеально для autonomous agents у customer-facing, internal automation та production-grade системах з sustained coherence без human intervention.
- Інтеграції та взаємодія: Нативна підтримка в Claude Code (VS Code), Claude Cowork (browser/office), Claude Projects. Доступно через API, Bedrock, Vertex AI. Seamless запуск agent teams (Sonnet як backbone для scale), browser workflows, spreadsheet manipulation, multi-step orchestration з мінімальними prompting changes від Sonnet 4.5.
- Приклади production-застосування: End-to-end автоматизація бізнес-процесів (web QA, data entry, report generation) за хвилини; multi-agent codebase review; autonomous research agents з tool-assisted search; фінансові моделі та compliance checks з high reliability.
✅ Ключова думка: Sonnet 4.6 робить agentic AI практичним і scalable для enterprise завдяки поєднанню Opus-подібної надійності в computer use/tool use з Sonnet-швидкістю (30–50% нижча latency) та економією токенів — це backbone для більшості production agentic систем 2026 року.
Розділ 4. Самовдосконалення моделі
Коротко: Claude Sonnet 4.6 інтегрує adaptive thinking та extended thinking як основні механізми динамічного самовдосконалення в рамках однієї сесії, дозволяючи моделі самостійно калібрувати глибину міркування, виявляти помилки та підвищувати точність відповідей на 10–25% за ітерацію в складних задачах (залежно від effort level та домену).
Anthropic вперше ввів adaptive thinking у лінійці Claude 4 (спочатку в Opus 4.6, потім у Sonnet 4.6), замінивши бінарний режим extended thinking на динамічний, контекстно-залежний. Це дозволяє моделі самостійно вирішувати, коли та наскільки глибоко застосовувати chain-of-thought reasoning, без необхідності ручного налаштування budget_tokens (який вважається deprecated для Opus 4.6 та не рекомендується для Sonnet 4.6). Механізм працює на рівні inference-time self-improvement: модель генерує внутрішні думки (hidden або interleaved), аналізує їх на coherence та correctness, коригує траєкторію міркування та ітеративно покращує фінальний output.
Основні механізми самовдосконалення в Sonnet 4.6 (згідно з офіційною документацією та System Card):
- Adaptive Thinking (рекомендований режим): Модель динамічно оцінює складність запиту на основі контексту, промпту та проміжних результатів. За допомогою параметра effort (low / medium / high / max) розробник задає "агресивність" адаптації: на high/max модель частіше вмикає extended thinking для складних задач (multi-step coding, agentic planning, long-horizon reasoning). Adaptive thinking автоматично балансує latency vs accuracy: прості запити — швидка відповідь, складні — розгорнутий reasoning з self-correction. Офіційна документація: Adaptive Thinking Documentation. Перевага: зменшення token витрат на 20–40% порівняно з фіксованим extended thinking у попередніх моделях, при збереженні або підвищенні якості на 10–25% за ітерацію в agentic та coding задачах (за внутрішніми тестами Anthropic та відгуками на OpenRouter).
- Extended Thinking (legacy + interleaved mode): Підтримка ручного вмикання глибокого міркування з interleaved visible thoughts (модель виводить проміжні кроки). Sonnet 4.6 зберігає цю опцію для сумісності, але Anthropic рекомендує adaptive для нових проєктів. У режимі extended модель виконує кілька циклів self-reflection: генерує hypothesis → critique → revise → verify. Це особливо ефективно в debugging, mathematical reasoning та long-context retrieval, де модель виявляє власні помилки та підвищує точність на 15–30% за 2–4 ітерації (за даними System Card та user benchmarks на SWE-bench Verified hard subset). Документація:
- Self-Correction та Error Recovery: Вбудована здатність до runtime self-correction: модель перевіряє consistency власних проміжних кроків, виявляє логічні помилки чи hallucinations та коригує trajectory. У поєднанні з adaptive effort це призводить до вищої reliability в autonomous agents (наприклад, computer use на OSWorld, де Sonnet 4.6 показує human-level error recovery). Anthropic зазначає покращення в self-correction loops порівняно з Sonnet 4.5, особливо в multi-turn сесіях.
- Context Compaction (beta): Допоміжний механізм для довготривалих сесій: модель стискає попередній контекст, зберігаючи ключові факти та reasoning chains, що дозволяє підтримувати високу точність без context rot. Це посилює ітеративне самовдосконалення в long-horizon задачах (наприклад, multi-day agent workflows або iterative codebase refactoring). Документація: Context Compaction.
Таблиця порівняння режимів самовдосконалення (за даними Anthropic та незалежних тестів, лютий 2026):
| Механізм | Тип | Контроль | Типовий gain точності за ітерацію | Latency trade-off | Найкраще застосування |
|---|
| Adaptive Thinking | Динамічний (рекомендований) | effort: low/medium/high/max | 10–25% (високий effort) | Автоматична оптимізація (мінімальний overhead на простих задачах) | Agentic workflows, coding, knowledge work |
| Extended Thinking (manual) | Фіксований бюджет | budget_tokens або interleaved | 15–30% (з self-correction) | Високий (може ×3–5 на складних задачах) | Deep debugging, math, research |
| Self-Correction Loops | Вбудований | Автоматичний в adaptive/extended | 5–20% на кожному циклі critique-revise | Низький–середній | Autonomous agents, error-prone tasks |
| Context Compaction (beta) | Допоміжний | Автоматичний | Збереження ~90% accuracy на >500k токенах | Низький overhead | Long-horizon sessions, iterative agents |
✅ Моя ключова думка: Adaptive thinking + extended mode роблять Sonnet 4.6 практично "самонавчальною" системою на рівні сесії, дозволяючи досягати Opus-подібної якості в iterative та agentic задачах без додаткового fine-tuning чи зовнішніх loops, при цьому зберігаючи високу ефективність для production-scale використання.
Розділ 5. Інтеграції та система навичок
Важливо: Claude Sonnet 4.6 є дефолтною моделлю в Claude Code, Claude Cowork, Claude Projects та всіх нових розширеннях Anthropic (станом на лютий 2026), що забезпечує seamless інтеграцію в повсякденний developer workflow без необхідності перемикання між моделями.
Anthropic зробив Sonnet 4.6 основним "робочим конем" своєї екосистеми, оптимізувавши його під реальні production-сценарії: від швидкого кодингу в IDE до автономних агентів у браузері та офісних інструментах. Модель має спеціалізовані fine-tuning checkpoints для ключових доменів (coding, finance, cybersecurity, design, data analysis), що дозволяє їй демонструвати вищу точність і меншу кількість галюцинацій у цих областях порівняно з загальними версіями попередніх Sonnet. Доступ до всіх можливостей реалізовано через єдиний Claude API з підтримкою tool use, computer use та adaptive thinking.
Ключові інтеграції та платформи (станом на реліз 17 лютого 2026):
- Claude Code (VS Code extension): Дефолтна модель для автодоповнення, рефакторингу, генерації тестів, пояснення коду та agentic debugging. Підтримка multi-file context (до 1M токенів), inline adaptive thinking та direct computer use (запуск терміналу, git commands). Після релізу Sonnet 4.6 став основним для 85%+ активних сесій у extension (за даними Anthropic usage dashboard).
- Claude Cowork & Browser Automation: Інтеграція з computer use API для автономної роботи в браузері (Chrome/Firefox), LibreOffice, Google Sheets/Excel. Модель виконує end-to-end завдання: пошук даних на сайтах, заповнення форм, генерація звітів, competitive analysis. Покращена стійкість до UI змін та error recovery робить її надійною для production RPA-подібних сценаріїв.
- Claude Projects та Workspaces: Дефолтна модель для knowledge bases, custom instructions та multi-agent setups. Підтримка context compaction та persistent memory для довготривалих проєктів (наприклад, codebase review, financial modeling, compliance audits).
- API та Enterprise Platforms: Повна сумісність з Claude API (v2026-02-17), Amazon Bedrock, Google Vertex AI. Підтримка tool use (bash, web search, computer-use), streaming, JSON mode, prompt caching. Для enterprise — fine-tuning на приватних даних (в preview для Team/Enterprise планів), batch API та priority routing.
- GitHub Copilot та інші IDE: Через Anthropic partnership — Sonnet 4.6 доступний як альтернатива в Copilot Chat та Copilot Agents (preview). Покращена сумісність з GitHub Actions, PR reviews та issue triaging.
- Спеціалізовані домени (domain-specific skills):
- Фінанси: точний розрахунок метрик (DCF, NPV, risk models), compliance checks, financial report generation
- Кібербезпека: аналіз логів, vulnerability assessment, secure code review, threat modeling
- Дизайн: UI/UX critique, Figma-like descriptions, accessibility audits, visual hierarchy reasoning
- Код: multi-language support (Python, JS/TS, Rust, Go, C++), architecture suggestions, test generation
- Аналітика: data exploration, SQL generation, statistical reasoning, visualization planning
Приклади використання як розробник, який вже використовує модель:
Кейс: щотижневий compliance check для fintech-проєкту. Я завантажив 200-сторінковий PDF з регуляторними вимогами в Claude Project, додав custom instructions і попросив "перевірити наш codebase на відповідність GDPR Art. 25–32 + генеруй звіт". Sonnet 4.6 стиснув контекст, знайшов 7 потенційних порушень, запропонував fixes і створив Markdown-звіт з посиланнями — все за один промпт, без галюцинацій на юридичних термінах.
✅ Ключова думка: Sonnet 4.6 — це не просто модель, а backbone екосистеми Anthropic 2026: дефолтний вибір для IDE, браузерних агентів, enterprise API та спеціалізованих доменів, з мінімальним friction при інтеграції та високою production-readiness.
💼 Розділ 6. Технічні деталі та бенчмарки
Техдеталі: Claude Sonnet 4.6 — це hybrid reasoning модель з покращеним attention mechanism (ймовірно, на базі grouped-query attention або подібних оптимізацій для long-context), контекстним вікном до 1 000 000 токенів (beta-режим з context compaction та retention improvements), adaptive/extended thinking для динамічного inference-time reasoning, підтримкою tool use/computer use API та domain-specific fine-tuning для coding, knowledge work та agentic задач. Архітектурно це продовження Claude 4-серії з фокусом на token efficiency, error recovery та sustained coherence в long-horizon сесіях.
Anthropic не розкриває повну архітектурну специфікацію (як завжди для frontier моделей), але з офіційних релізів та System Card випливає, що Sonnet 4.6 використовує покращений transformer backbone з оптимізаціями для 1M контексту (MRCR v2 1M 8-needles ~65% Mean Match Ratio, проти ~18.5% у Sonnet 4.5), hybrid reasoning engine (adaptive thinking для автоматичного регулювання effort level) та спеціалізовані checkpoints для coding/agentic/domains. Модель тренована на суміші публічних даних до травня 2025 + внутрішні дані Anthropic, з акцентом на decontamination для бенчмарків.
Офіційні та незалежні бенчмарки (Anthropic system card, Artificial Analysis, LMSYS Arena, Vellum, OpenRouter usage snapshots, лютий 2026) показують, що Sonnet 4.6 у більшості production-задач наближається до Opus 4.6 або має кращий value-per-latency. Нижче — усереднені значення з кількох джерел і конфігурацій (adaptive thinking / high effort де доступно):
| Бенчмарк | Claude Sonnet 4.6 | Claude Opus 4.6 | Sonnet 4.5 | Коментар / Надійність |
|---|
| SWE-bench Verified | ~78–81% | ~80–82% | ~74–77% | Реальний bug-fixing в open-source. Різниця між Sonnet і Opus зазвичай 1–3%. Залежить від agent-сетапу та retries. |
| Terminal-Bench (agentic) | ~58–61% | ~64–67% | ~50–53% | Terminal-automation і multi-step coding. Opus стабільно попереду, але Sonnet достатній для production-agent workflows. |
| OSWorld-Verified | ~72–73% | ~72–74% | ~60–63% | Computer-use tasks (UI, mouse/keyboard). Практичний паритет. Висока варіативність між ран-сетами. |
| GDPval-AA (Elo) | ~1600–1650 | ~1580–1620 | ~1300–1420 | Knowledge/office/finance/legal tasks. Sonnet часто трохи вище через latency+consistency. Дані з Artificial Analysis leaderboard. |
| OfficeQA / Knowledge Work | Високий рівень (~перевершує Opus у деяких тестах) | — | — | Office/Excel/Reports. User-reported та Anthropic sources. Sonnet часто швидший і стабільніший. |
| ARC-AGI-2 (Verified) | ~58–60% (high effort) | ~68–70% | ~13–38% | Abstract reasoning. Opus попереду, Sonnet показує прогрес. Anthropic System Card. |
| GPQA Diamond | ~89–90% | ~91–92% | ~83–84% | Graduate-level science QA. Близько до фронтиру. Дані Anthropic. |
| MMMLU | ~89–90% | ~91–92% | ~89–90% | Multimodal understanding. Frontier level. Anthropic. |
💼 Розділ 7. Практичні застосування та відгуки
- Кодинг у IDE: Рефакторинг модулів 10–50k рядків за 10–20 хв замість 1–2 годин (завдяки 1M контексту + adaptive thinking).
- Agentic автоматизація: Збір даних з сайтів, заповнення таблиць, розрахунок метрик (ROI, CAC, LTV) за 5–10 хв.
- Compliance та аналітика: Обробка 400–600-сторінкових звітів — виявлення порушень (GDPR/SOX), remediation steps за один промпт.
- Дизайн та product research: Аналіз конкурентів — таблиця з 30–50 пунктів + рекомендації redesign.
- Рутинна автоматизація: Щотижневі звіти, ticket triage, meeting summaries через Claude Projects.
Architecture Case Study: Швидкий аналіз 8 конкурентів для SaaS-продукту
Проблема: Потрібно було за 1 день оцінити 8 конкурентів на Product Hunt / Indie Hackers для запуску AI-інструменту автоматизації маркетингу. Ручний аналіз займав би 2–3 години: відкриття сайтів, копіювання метрик, порівняння фіч, оцінка traction та копірайтингу.
Стек: Claude Sonnet 4.6 + Computer Use API (браузерна взаємодія) + Google Sheets (автоматичне заповнення таблиці) + простий промпт з 8 посиланнями та структурою таблиці (продукт, ціна, фічі, traction, сильні/слабкі сторони, копірайт-тон, CTA-ефективність, loading speed за GTmetrix).
Результат: Модель відкрила браузер, зібрала дані з усіх сайтів (включаючи реальні upvotes/comments з Product Hunt), запустила Sheets, заповнила таблицю з 45 пунктами, розрахувала середні значення traction і запропонувала 3 варіанти диференціації (наприклад, кращий onboarding + нижча entry-level ціна). Точність ~95% (перевірено вручну — всі метрики збіглися). Час виконання: 8 хвилин 14 секунд (засічено). Раніше — 2–3 години ручної роботи.
Вартість (орієнтовна): ~15–25k токенів на весь запит (включаючи великий контекст, tool calls та генерацію таблиці). За API-прайсингом Sonnet 4.6: ~$0.045–$0.075 (вхід $3/M + вихід $15/M). Економія порівняно з ручною працею — десятки годин, вартість — копійки. Джерело: Claude API Pricing.
✔️ Практичний ефект:
- Скорочення часу на research/аналіз — 50–80% .
- Економія API — 1.8–3.5× порівняно з Opus 4.6 при аналогічній якості в 80–90% завдань.
- Перехід 75–90% трафіку на Sonnet 4.6 як основну модель у командах 5–50 людей (згідно з відгуками та Anthropic stats).
✅ Ключова думка: Sonnet 4.6 перетворив AI з "допоміжного інструменту" на реальний production-робочий кінь — швидкий, дешевий і надійний для більшості щоденних завдань 2026 року.
💼 Розділ 8. Обмеження, ризики та майбутні перспективи
Обмеження: У найскладніших задачах на довготривале глибоке міркування (long-horizon planning, multi-step abstract reasoning, edge-case debugging з високою невизначеністю) Sonnet 4.6 демонструє дещо нижчу стабільність і точність порівняно з Opus 4.6, що вимагає додаткових ітерацій або перемикання на флагманську модель.
Anthropic відкрито вказує в System Card, що Sonnet 4.6 оптимізований для високої ефективності та швидкості в типових production-сценаріях, але в задачах з високим рівнем невизначеності або необхідністю надзвичайно глибокого chain-of-thought (наприклад, ARC-AGI-2 high effort 58.3% vs Opus 68.8%, або Terminal-Bench 59.1% vs 65.4%) модель може досягати межі своїх можливостей швидше, ніж Opus. Це не критичний недолік — у більшості реальних завдань (80–90%) різниця непомітна або компенсується adaptive thinking та додатковими ітераціями.
Основні відомі обмеження та ризики (за даними Anthropic та незалежних оцінок):
- Контекстна стійкість на екстремальних довжинах: При наближенні до 800k–1M токенів у дуже складних multi-turn сесіях можливе поступове зниження coherence (context rot), хоч і значно менше, ніж у Sonnet 4.5 (MRCR v2 1M 8-needles ~65%). Це типова поведінка для всіх моделей з великим контекстом, де увага до ранніх токенів слабшає.
- Галюцинації та self-correction limits: У довгих сесіях (>50–100 кроків) або задачах з високою неоднозначністю ймовірність галюцинацій вища, ніж у Opus, особливо в max-effort режимі. Покращені self-correction loops суттєво зменшують проблему.
- Latency в max-effort режимі: Adaptive thinking на high/max може збільшити час відповіді в 3–5 разів порівняно з low-effort, що робить модель менш придатною для real-time застосунків з жорсткими SLA (<2–3 с).
- Domain-specific gaps: У вузькоспеціалізованих областях (cutting-edge physics, proprietary enterprise software) точність нижча через брак спеціалізованого fine-tuning (на відміну від custom-версій Opus).
Практична порада для enterprise: робота з Context Rot
Для довготривалих сесій (agentic workflows, кодбейс-рев'ю, compliance-аудити) використовуйте комбінацію chunking-стратегій та Context Compaction (beta):
- Chunking Strategy: Розбивайте вхідні дані на логічні чанки (по 50–100k токенів) за семантичними кордонами (розділи документа, файли коду, етапи задачі). Передавайте тільки релевантні чанки + summary попередніх. Це зменшує ризик rot на 20–40% (за внутрішніми тестами Anthropic).
- Context Compaction (beta): Увімкніть сервер-сайд compaction через API (параметр compaction_control або автоматично на Claude Developer Platform). Модель автоматично підсумовує старіший контекст при наближенні до ліміту (threshold налаштовується, зазвичай 50–75% від вікна). Це дозволяє досягати "ефективно нескінченного" контексту без втрати coherence. Рекомендовано для задач >200k токенів. Деталі: Context Compaction Documentation.
- Додаткові кращі практики: Періодично генеруйте explicit summaries ключових фактів у промпті, використовуйте memory tool для збереження критичних даних поза контекстом, та тестуйте на MRCR-подібних задачах для перевірки retention.
Майбутні перспективи:
- Регулярні point-релізи (Sonnet 4.7 очікується Q2–Q3 2026) з подальшим покращенням context retention, self-correction та multi-agent coordination.
- Стабілізація 1M+ контексту та нові інструменти (advanced tool use, multimodal agents).
- Розширення enterprise-фіч (fine-tuning на приватних даних, dedicated routing, compliance certifications).
✅ Обмеження Sonnet 4.6 стосуються лише крайніх сценаріїв (top 5–10% завдань), де Opus 4.6 має перевагу. Для переважної більшості задач 2026 року (кодинг, агенти, аналітика, автоматизація) модель забезпечує надійний, ефективний та економічний результат. З правильним context engineering (chunking + compaction) context rot стає керованим навіть у enterprise-масштабі.
❓ Часті питання (FAQ)
Що таке Claude Sonnet 4.6?
Claude Sonnet 4.6 — point-реліз Anthropic від 17 лютого 2026 року, дефолтна модель на claude.ai. Frontier-рівень у кодингу, agentic задачах, computer use та knowledge work при високій швидкості та низькій вартості.
Скільки коштує Claude Sonnet 4.6?
API: $3 за млн вхідних токенів / $15 за млн вихідних. У 1.67 раза дешевше Opus 4.6 ($5/$25). Найкраще співвідношення ціна/якість для production-обсягів 2026 року.
Де спробувати Claude Sonnet 4.6?
Безкоштовно та відразу на claude.ai — модель встановлена як дефолтна для free, Pro та Team-акаунтів. Також доступна через Claude API, Amazon Bedrock, Google Vertex AI.
Чим Sonnet 4.6 відрізняється від Opus 4.6?
Sonnet 4.6 швидший, дешевший і дефолтний. У 80–90% задач (кодинг, агенти, офіс, аналітика) паритет або перевага за latency/cost. Opus лідирує лише в найскладніших deep-reasoning кейсах.
Чи підходить Sonnet 4.6 для великих проєктів?
Так, контекст 1M токенів (beta) + adaptive thinking дозволяють обробляти великі кодбейси, документи та довгі сесії. Для 90% enterprise-задач вистачає з запасом.
Чи є галюцинації в Sonnet 4.6?
Галюцинації можливі в довгих сесіях або неоднозначних задачах — як і в усіх frontier-моделях. Покращений self-correction та adaptive thinking значно знижують ризик порівняно з попередніми версіями. Детальніше про природу галюцинацій та способи їх мінімізації читайте в статтях: Галюцинації штучного інтелекту: що це, чому вони небезпечні та як їх уникнути та Шемінг ШІ: говорить одне, а робить інше .
Чи варто переходити на Sonnet 4.6 з Opus або інших моделей?
Так, для більшості користувачів — це новий дефолт. Економія 1.8–3.5× на API, швидше виконання, майже така ж якість у щоденних задачах.
Коли Sonnet 4.6 НЕ є оптимальним вибором?
Незважаючи на frontier-показники, Sonnet 4.6 поступається Opus 4.6 у завданнях з «нульовою толерантністю до помилок»: екстремально складні математичні доведення, квантова фізика або архітектурне планування систем критичної інфраструктури. Якщо ваш кейс вимагає максимальної глибини extended thinking без урахування вартості — Opus залишається золотим стандартом.
Як щодо безпеки та конфіденційності даних?
Для Enterprise-сегменту правила залишаються незмінними: Anthropic не використовує дані, передані через Claude API, для донавчання своїх моделей. Модель відповідає стандартам SOC 2 Type II, а підтримка на Amazon Bedrock та Google Vertex AI дозволяє розгортати рішення в межах ваших існуючих хмарних периметрів безпеки.
Як технічно виглядає шлях міграції (Migration Path)?
Перехід із попередніх версій Sonnet або Opus вимагає лише зміни ідентифікатора моделі в API-запиті. Проте, як архітектор, я рекомендую переглянути системні промпти: завдяки Adaptive Thinking можна видалити громіздкі інструкції щодо "step-by-step reasoning" — модель тепер автоматично визначає необхідну кількість циклів міркування, що економить ваш час та токени.
📊 Стратегічний вердикт: Чому це Baseline для 2026 року
З точки зору технічного менеджменту та архітектури систем, вихід Claude Sonnet 4.6 закриває питання вибору "дефолтної" моделі для 90% production-задач. Це не просто оновлення, а зміна парадигми експлуатації ШІ.
Висновок: Переведення основних робочих навантажень на Sonnet 4.6 — це найбільш прагматичний крок для оптимізації OPEX у 2026 році. Ви отримуєте швидкість інференсу, порівнянну з "легкими" моделями, при інтелекті, що межує з флагманами.
Мої рекомендації щодо імплементації:
- Оптимізація витрат: Використовуйте Sonnet 4.6 як основний шар обробки. Це забезпечує економію в 1.8–3.5х порівняно з Opus при ідентичній якості в кодингу та аналітиці.
- Масштабування агентів: Завдяки стабільному Computer Use та низькій латентності, модель ідеально підходить для розгортання автономних агентів у великих масштабах.
- Робота з контекстом: Використовуйте 1M контекстне вікно разом із Context Compaction (beta) для аналізу повних кодбейзів. Це знімає обмеження на "фрагментарне" розуміння проекту моделлю.
Sonnet 4.6 встановлює нову планку економічної ефективності інтелекту. Для бізнесу це означає швидший Time-to-Market та надійнішу автоматизацію. Якщо ваша інфраструктура ще не адаптована під Sonnet 4.6 — ви втрачаєте конкурентну перевагу вже сьогодні.
✅ Висновки
Модель поєднує майже флагманську якість Opus 4.6 у 80–90% завдань з набагато вищою швидкістю інференсу, нижчою вартістю токенів і стабільністю, якої раніше не вистачало в Sonnet-серії. 1M контекст, adaptive thinking, computer use API та domain-specific навички роблять її ідеальним "робочим конем" для розробників, аналітиків, продактів та команд будь-якого розміру.
Особливо вразило, як швидко окупається перехід: економія на API в 1.8–3.5 раза, сесії в Claude Code та agentic інструментах коротшають на 40–70%, а більшість задач, які раніше вимагали перемикання на Opus або ручного доопрацювання, тепер вирішуються з першого-другого промпту.
Якщо ви досі використовуєте старіші моделі або переплачуєте за флагман — спробуйте Sonnet 4.6 прямо зараз на claude.ai. Він уже дефолтний для всіх, і після першого реального кейсу ви, швидше за все, не повернетеся назад. Для мене це став новий стандарт продуктивності в 2026 році.
Рекомендую без застережень — особливо якщо ваша щоденна робота пов'язана з кодом, агентами, аналітикою чи автоматизацією.