Claude Opus 4.7 — новий флагман Anthropic, який вийшов 16 квітня 2026 року. Головне: +10.9 пунктів на SWE-bench Pro (64.3% проти 53.4% у Opus 4.6), вища роздільна здатність vision (3.75 MP), нова memory на рівні файлової системи та новий рівень міркування xhigh. Ціна не змінилась — $5 / $25 за мільйон токенів. Але є breaking changes: новий токенайзер витрачає на 1.0–1.35× більше токенів на тому ж тексті, ручний extended thinking більше не підтримується, а модель тепер слідує інструкціям буквально — старі промпти можуть ламатись. Opus 4.7 поступається лише Claude Mythos Preview, яка недоступна публічно. Варто оновлюватись, якщо ви працюєте з coding-агентами, computer use або RAG-системами. Для простих чат-ботів виграш мінімальний.
🚀 Що таке Claude Opus 4.7 і чим відрізняється від Opus 4.6
Opus 4.7 — це не нове покоління, а ітеративне оновлення Opus 4.6 з серйозними покращеннями у coding, agentic workflows та vision. Але для розробників є кілька ламаючих змін, які треба врахувати.
Claude Opus 4.7 вийшов 16 квітня 2026 року і автоматично замінив Opus 4.6 як модель за замовчуванням у Claude API та всіх продуктах Claude (Pro, Max, Team, Enterprise). Anthropic тримає каденцію випусків приблизно раз на два місяці: Opus 4.5 вийшов у листопаді 2025, Opus 4.6 — у лютому 2026, Opus 4.7 — у квітні 2026.
Головне позиціонування від Anthropic: Opus 4.7 «слідує інструкціям точніше, верифікує власний вихід перед тим, як повідомити результат, і справляється з довгими задачами з більшою ретельністю». На практиці це означає, що модель спроектована під агентні сценарії — там, де модель працює автономно без постійного нагляду.
Важливий контекст: одночасно з Opus 4.7 Anthropic згадує про Claude Mythos Preview — свою найпотужнішу модель, яка випереджає Opus 4.7 на всіх бенчмарках. Але Mythos недоступна публічно — її отримали лише партнери в рамках програми Project Glasswing (Apple, Google, Microsoft та низка cybersecurity-компаній). Тому для нас як розробників Opus 4.7 — це фактична стеля можливостей Anthropic, доступна сьогодні.
Було / стало: Opus 4.6 vs Opus 4.7
Параметр
Opus 4.6 (лютий 2026)
Opus 4.7 (квітень 2026)
SWE-bench Verified
80.8%
87.6% (+6.8)
SWE-bench Pro
53.4%
64.3% (+10.9)
GPQA Diamond (reasoning)
91.3%
94.2% (+2.9)
OSWorld-Verified (computer use)
72.7%
78.0% (+5.3)
CursorBench
58%
70% (+12)
BrowseComp (agentic search)
83.7%
79.3% (-4.4)
Max vision resolution
1.15 MP (1568px)
3.75 MP (2576px)
Extended thinking
Ручний + адаптивний
Тільки адаптивний
Ефективність токенайзера
Базова
1.0–1.35× токенів на той же текст
Ціна
$5 / $25 за 1M токенів
$5 / $25 (без змін)
Зверніть увагу на зниження BrowseComp — це єдиний бенчмарк, де Opus 4.7 відступив. BrowseComp тестує здатність моделі шукати інформацію в інтернеті, і тут Opus 4.7 програє як Gemini 3.1 Pro (85.9%), так і GPT-5.4 Pro (89.3%). Якщо ваш агент багато працює з web research — це треба врахувати.
⚙️ Ключові технічні характеристики: context, reasoning, tool use
Висновок: 1M токенів контексту (без преміум-націнки), 128K вихід, нові рівні міркування xhigh та max, task budgets для контролю витрат. Три breaking changes, через які старий код може ламатись.
Context window і output
Opus 4.7 успадкував від Opus 4.6 контекстне вікно у 1 мільйон токенів — включено у стандартну ціну, без окремої націнки за «довгий контекст». Максимальний вихід — 128K токенів. Для RAG-систем, де ми часто працюємо з великими документами, це принципово важлива цифра — в один запит можна вмістити еквівалент 750+ сторінок тексту.
Нові рівні reasoning
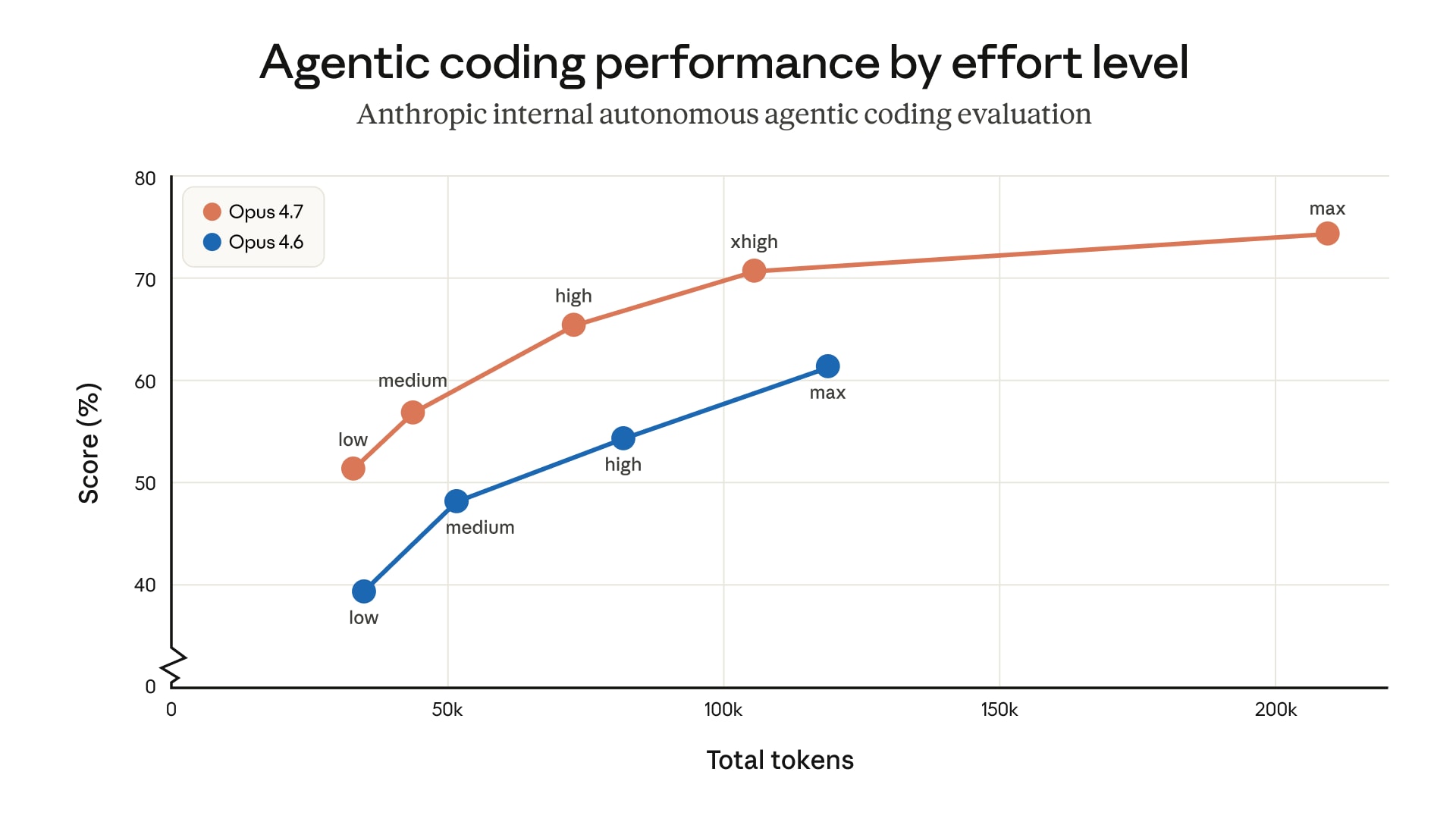
В Opus 4.7 тепер чотири рівні зусиль для reasoning: low, medium, high, xhigh, max. Новий xhigh — це компроміс між high і max. За внутрішніми даними Anthropic, max дає найвищі оцінки (близько 75% на coding-задачах), але споживає значно більше токенів. xhigh — sweet spot між продуктивністю та витратами.
Для Claude Code за замовчуванням тепер використовується xhigh на всіх планах. Для API Anthropic рекомендує починати з high або xhigh для coding та agentic сценаріїв.
Task budgets — контроль витрат
Нова фіча в public beta — task budgets. Ви встановлюєте жорстку стелю витрат на токени для автономного агента. Це критично важливо, якщо ви запускаєте довгі debugging-сесії або багатокрокові задачі — без цього одна помилка може обнулити ваш API-баланс.
⚠️ Три breaking changes, про які треба знати
Якщо ви мігруєте з Opus 4.6 на 4.7, три речі можуть зламати ваш код:
Ручний extended thinking більше не підтримується. Тепер тільки адаптивне мислення — модель сама вирішує, скільки думати. Якщо ви в коді виставляли extended_thinking.budget_tokens, виклик поверне 400-у помилку.
Параметри sampling більше не працюють.temperature, top_p, top_k — при спробі їх задати отримаєте 400. Контролювати поведінку тепер треба промптами, а не параметрами.
Новий токенайзер — реальна вартість зросла. Один і той самий текст тепер мапиться у 1.0–1.35× більше токенів. Ціна за токен залишилась $5 / $25, але реальна вартість запиту може зрости на 35%. Плюс модель генерує більше output-токенів на високих рівнях зусиль, бо «думає довше». На практиці — переплата може бути ще більшою.
Tool use і memory
Opus 4.7 — перша модель Claude, яка проходить те, що Anthropic називає «тестами на неявну потребу» (implicit-need tests). Це задачі, де модель має сама здогадатись, які інструменти чи дії потрібні, замість того щоб отримувати явні інструкції. На бенчмарку MCP-Atlas (scaled tool use) Opus 4.7 набирає 77.3% — найкращий результат серед публічно доступних моделей, включно з GPT-5.4.
Покращено і memory на основі файлової системи — модель краще запам'ятовує важливі нотатки через довгі, багатосесійні робочі процеси. Для нашої задачі (RAG) це менш критично, бо ми зазвичай керуємо контекстом самі. Але для агентів, які живуть у терміналі або IDE — це помітне покращення.
💻 Як Opus 4.7 справляється з кодом і складними задачами
Opus 4.7 — найкраща доступна сьогодні модель для програмування. SWE-bench Pro виріс на 10.9 пунктів, CursorBench — на 12. Але є нюанс: модель тепер слідує інструкціям буквально, тому старі промпти можуть поводитись інакше.
Бенчмарки програмування
Головна історія Opus 4.7 — це саме coding. Цифри:
Бенчмарк
Opus 4.7
Opus 4.6
GPT-5.4
Gemini 3.1 Pro
SWE-bench Verified
87.6%
80.8%
78.2%
78.8%
SWE-bench Pro
64.3%
53.4%
57.7%
54.2%
CursorBench
70%
58%
—
—
SWE-bench Pro — це складніша версія SWE-bench, що тестує реальні GitHub issues у чотирьох мовах програмування. Стрибок з 53.4% до 64.3% — найбільший coding-приріст у цьому поколінні моделей.
Партнери, які мали ранній доступ, підтверджують результати на власних бенчмарках:
Hex — 13% приросту на 93-task benchmark. Низький effort Opus 4.7 приблизно дорівнює середньому effort Opus 4.6.
CodeRabbit — recall виріс на 10%+ на code review, precision залишився стабільним.
Warp — Terminal-Bench задачі, які попередні Claude не вирішували, пройшли успішно.
Rakuten-SWE-Bench — 3× більше вирішених production-задач порівняно з Opus 4.6.
Нова команда /ultrareview у Claude Code
У Claude Code з'явилась команда /ultrareview — multi-agent code review. Замість одного інстансу Claude, який сканує код, /ultrareview запускає кілька спеціалізованих агентів (один на безпеку, один на логіку, один на продуктивність, один на стиль) і синтезує їхні результати у єдиний звіт. За описом Anthropic — «як чотири senior-інженери ревʼюють ваш PR одночасно».
⚠️ Нюанс: літеральне слідування інструкціям
Важливе попередження від Anthropic: Opus 4.7 слідує інструкціям буквально. Opus 4.6 часто «читав між рядків» — міг пом'якшити інструкції або пропустити частини, які вважав неважливими. Opus 4.7 виконує саме те, що написано.
На практиці це означає: якщо у вашому промпті є нечіткі або суперечливі формулювання, Opus 4.7 може повестись несподівано. Anthropic рекомендує переглянути промпти після міграції — особливо якщо вони писались під 4.5 або 4.6.
🎯 Чи зменшились галюцинації порівняно з попередньою версією
На питаннях, що базуються на вигаданих фактах, Opus 4.7 на рівні з 4.6. Під тиском (коли користувач або system prompt штовхає модель суперечити власній оцінці) — 4.7 більш чесний, але менш твердий за Mythos Preview. Prompt injection resistance — покращено.
За System Card Anthropic, Opus 4.7 має схожий safety profile до Opus 4.6. На питаннях про вигадані факти точність збереглась — без деградації, але й без значного покращення.
Важливі зміни:
Prompt injection resistance — помітно покращено. Це критично для RAG-систем та публічних чат-ботів.
Honesty under pressure — Opus 4.7 частіше тримає свою позицію, коли користувач тисне. Але менш твердо за Mythos.
Self-verification — нова поведінкова особливість: модель створює внутрішні тести, щоб перевірити власну відповідь перед тим, як віддати її. Це частково пояснює приріст на SWE-bench.
AI safety research — модель все ще в 33% випадків відмовляється допомогти з легітимними safety research задачами. Це значне покращення від 88% в Opus 4.6, але проблема залишається.
Цікавий feedback від партнера Hex: «Opus 4.7 коректно повідомляє, коли дані відсутні, замість того, щоб надавати правдоподібні-але-неправильні відповіді, і опирається пасткам з суперечливими даними, в які навіть Opus 4.6 потрапляв». Для RAG-систем це ключова властивість — відповідь «я не знаю» часто цінніша за впевнену галюцинацію.
💰 Скільки коштує використання Opus 4.7 через API
Короткий висновок: ціна за токен та ж сама — $5 input / $25 output за 1M токенів. Але реальна вартість запиту зросла через новий токенайзер (1.0–1.35× токенів) та тенденцію моделі довше думати на високих рівнях зусиль.
Базова ціна
Модель
Input (за 1M токенів)
Output (за 1M токенів)
Claude Opus 4.7
$5
$25
Claude Opus 4.6
$5
$25
GPT-5.4
Вищий (точні цифри залежать від конфігурації)
Вищий
Gemini 3.1 Pro
$2
$12
Коли я порівнював ціни для своїх клієнтів, Gemini 3.1 Pro одразу привернув увагу — він майже втричі дешевший за Opus 4.7. Якщо у вас базова генерація без строгих вимог до coding чи agentic workflows, Gemini може бути економічно вигіднішим вибором, і я сам рекомендую його в таких сценаріях. Але на ключових для бізнесу бенчмарках (SWE-bench, MCP-Atlas) Opus 4.7 лідирує з помітним відривом — і в моїх реальних тестах на RAG-задачах різниця у якості відповідей виправдовує преміум.
Способи зекономити
Prompt caching — до 90% знижка на повторювані частини контексту. Для RAG-систем, де system prompt великий, це must-have.
Batch API — 50% знижка на input і output для задач, які не потребують реального часу.
Task budgets — жорсткий ліміт на витрати агента, захист від несподіваних рахунків.
⚠️ Реальна вартість: я зіткнувся з +23% витрат після міграції
Ось де найважливіше і про що я хочу попередити. Офіційна ціна за токен не змінилась, але новий токенайзер мапить той же текст у 1.0–1.35× більше токенів. Плюс модель на високих рівнях зусиль думає довше і генерує більше output. Для production-застосувань з тонкою маржею це може стати неприємним сюрпризом — я сам це відчув відразу після релізу.
Я протестував Opus 4.7 на реальному навантаженні AskYourDocs наступного дня після виходу моделі. Без жодних змін у логіці системи — просто підмінив model ID з claude-opus-4-6 на claude-opus-4-7. Вартість обробки тих самих запитів зросла приблизно на 23% через нову токенізацію. Довелось одразу переглянути system prompt, скоротити дублювання і підключити prompt caching.
Мій практичний пресет, який я тепер закладаю для клієнтів: при міграції з 4.6 додавайте +20-25% до бюджету на API на початок, а потім оптимізуйте на основі фактичних даних. Через кілька днів активного використання ви знайдете способи скоротити ці витрати — через кешування та переписаний промпт.
Opus 4.7 доступний через Claude API (ID моделі claude-opus-4-7), Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry та OpenRouter — я особисто використовую OpenRouter для AskYourDocs (це дозволяє клієнтам легко перемикатись між моделями без зміни коду), прямий Claude API для тестів, а Bedrock раджу клієнтам, яким важлива AWS-інфраструктура.
🎯 Де Opus 4.7 показує себе найкраще: 3 реальні сценарії
Opus 4.7 — модель для задач, де ціна помилки висока, а автономність критична. Не завжди найкращий вибір для simple use cases.
Сценарій 1: Автономні coding-агенти
Це найсильніша сторона Opus 4.7. Приріст у 12 пунктів на CursorBench і 10.9 на SWE-bench Pro — не маркетинг, а реальна різниця у продакшені. Якщо ви запускаєте агента, який має сам знайти баг, написати патч і пройти тести — Opus 4.7 робить це надійніше за всі попередні моделі. Партнер Warp підтвердив: passes Terminal-Bench задачі, які попередні Claude не проходили.
Коли варто: розробка, де модель працює довго без нагляду, багатокрокові рефакторинги, code review, інтеграційні задачі в Claude Code.
Сценарій 2: Computer use та візуальні агенти
Максимальна роздільна здатність зображення зросла в 3× — до 3.75 MP. Координати тепер мапляться 1:1 з піксельними, що усуває потребу в scale-factor математиці. На OSWorld-Verified — 78.0% проти 72.7% у 4.6.
Коли варто: агенти, які читають скріншоти, дашборди, технічні схеми, PDF зі складним форматуванням. Для document analysis — можливість читати дрібний текст у сканованих документах це game changer.
Сценарій 3: Agentic RAG з перевіркою власних відповідей
Це сценарій, який мене цікавить найбільше і в якому я використовую Opus 4.7. Нова self-verification поведінка — модель створює внутрішні тести для перевірки своїх відповідей — помітно знижує рівень упевнених галюцинацій у RAG. Для питань, де відповіді у документах немає, Opus 4.7 частіше говорить «я не знаю» замість того, щоб вигадувати.
Коли варто: корпоративні AI-асистенти, де точність важливіша за швидкість, системи відповідей на основі юридичних або медичних документів, складні enterprise knowledge bases.
❌ Кому Claude Opus 4.7 НЕ підходить
Opus 4.7 — преміум-інструмент для складних задач. Для простих сценаріїв він може бути overkill і ви переплатите.
Будьте чесними з собою — Opus 4.7 не завжди правильний вибір. Не беріть його, якщо:
У вас простий чат-бот з FAQ. Для 30-50 типових питань надлишково навіть Sonnet, не кажучи про Opus. Ви переплатите у 5-10 разів без приросту якості.
Вам потрібен максимально дешевий вихід. Gemini 3.1 Pro дешевший у 2.5 рази на input і вдвічі на output. Для масових задач простого класифікації це може бути економічно виправдано.
Ваша основна задача — web research. Opus 4.7 просів на BrowseComp (79.3% проти 89.3% у GPT-5.4 Pro). Якщо агент живе на перегляді сайтів — подивіться на GPT-5.4 Pro або Gemini.
Вам треба self-hosted рішення. Anthropic не дає on-premise доступу. Якщо ви працюєте з медичними даними, юридичними документами, або просто маєте жорсткі GDPR-вимоги — вам потрібна open-source модель на власному сервері (Llama 3.3 70B, Qwen, Mistral тощо).
У вас багато старих промптів, які ви не готові переглядати. Літеральне слідування інструкціям може зламати поведінку, яка працювала у 4.6. Якщо у вас немає ресурсів на тестування — залишайтесь на 4.6, поки є.
Ваш API-код активно використовує temperature/top_p або ручний extended thinking. Ви отримаєте 400-ті помилки. Міграція потребує роботи.
👨💻 Мій досвід роботи з Opus 4.7 у RAG-системі AskYourDocs
Мій стек: Spring Boot, PostgreSQL, pgvector, Ollama для local dev, OpenRouter для production. Основна production модель — Llama 3.3 70B. Opus 4.7 я тестував як преміум-варіант для клієнтів, яким потрібна максимальна якість відповідей.
AskYourDocs — це RAG-система, яку я будую як B2B SaaS: корпоративна база знань на основі клієнтських документів з self-hosted-підходом. Ми мультивендорні — клієнт може вибрати LLM під свою задачу та бюджет. Тому Opus 4.7 я інтегрував як одну з опцій, а не як єдиний варіант.
Що я побачив під час тестування Opus 4.7 проти Llama 3.3 70B на документах (~400 PDF з юридичної сфери):
«Я не знаю» замість галюцинації. Найпомітніше спостереження. На питаннях, де відповіді в базі не було, Llama 3.3 70B у частині випадків видавала правдоподібну вигадку. Opus 4.7 чесно каже «у документах немає інформації». Для юридичної ніші це критично важлива різниця — я одразу відмітив це як ключову перевагу для клієнтів, які бояться помилок у відповідях на запити клієнтів.
Кращий retrieval quality через tool use. Коли я дав моделі інструменти для self-querying (шукати по метаданих, фільтрувати по датах), Opus 4.7 робить це значно точніше. Llama часто задає неоптимальні запити — доводиться багато чого пояснювати у system prompt. З Opus 4.7 цей промпт можна суттєво скоротити.
Вартість — серйозна. За моїми розрахунками на типовому клієнтському профілі (~1000 запитів на день, середній контекст 8-12K токенів), Opus 4.7 виходить у 10-15× дорожче за Llama 3.3 70B через OpenRouter. Для клієнтів з 20-30 співробітниками це нормально, для enterprise з тисячами — треба рахувати.
Літеральне слідування інструкціям — виграш для RAG. Коли я пишу у промпті «відповідай тільки на основі контексту, не використовуй загальні знання» — Opus 4.7 справді це робить. 4.6 іноді «додавав від себе», що у RAG критично неприпустимо.
Новий токенайзер одразу вдарив по бюджету. У моєму першому ж тестовому прогоні після міграції вартість обробки того самого набору запитів виросла приблизно на 23% — саме через нову токенізацію. Довелось одразу переглянути system prompt, видалити дублювання, підключити prompt caching.
Мій робочий компроміс сьогодні: Llama 3.3 70B як дефолт для більшості клієнтів, Opus 4.7 як «преміум» для ніш, де ціна помилки висока (юристи, фінанси, медицина). Вибір налаштовується в одному рядку конфігурації — клієнт може перемикнутись сам.
Для свого Mac M1 я продовжую використовувати Ollama з локальними моделями для розробки (детальніше про вибір між 8GB і 16GB RAM — у окремій статті). Opus 4.7 через API — лише для production або складного тестування.
❓ FAQ: Claude Opus 4.7
Коли вийшов Claude Opus 4.7?
16 квітня 2026 року. Це четверте оновлення Opus за пів року (4.1, 4.5, 4.6, 4.7), Anthropic тримає каденцію випусків приблизно раз на 2 місяці.
Чим Opus 4.7 відрізняється від Opus 4.6?
Головне — coding та agentic workflows. SWE-bench Pro виріс з 53.4% до 64.3%, CursorBench — з 58% до 70%. Покращено vision (3× вища роздільна здатність), tool use та memory. Є breaking changes: новий токенайзер, тільки адаптивний extended thinking, параметри sampling більше не працюють.
Скільки коштує Claude Opus 4.7 через API?
$5 за 1M input-токенів і $25 за 1M output-токенів — така ж ціна, як у Opus 4.6. Але реальна вартість запиту зросла через новий токенайзер (на 1.0–1.35× більше токенів на тому ж тексті) та тенденцію моделі довше думати на високих рівнях зусиль.
Чи замінить Claude Opus 4.7 GPT-5.4 або Gemini 3.1 Pro?
На coding-задачах — так, Opus 4.7 лідирує. На GPQA Diamond (графічне reasoning) моделі практично однакові — різниця у межах похибки. На web research (BrowseComp) Opus 4.7 програє. Вибір залежить від конкретного use case.
Чи можна використовувати Claude Opus 4.7 для RAG?
Так, і він працює добре — особливо там, де критична чесність моделі («я не знаю» замість галюцинації) і prompt injection resistance. Але для більшості RAG-задач достатньо дешевших open-source моделей типу Llama 3.3 70B. Opus 4.7 виправданий у нішах з високою ціною помилки.
Чи є Claude Opus 4.7 найкращою моделлю Anthropic?
Серед публічно доступних — так. Але Anthropic має ще Mythos Preview, яка випереджає Opus 4.7 на всіх бенчмарках. Mythos доступна лише партнерам у рамках Project Glasswing (Apple, Google, Microsoft) і не буде generally available найближчим часом.
Яке контекстне вікно у Claude Opus 4.7?
1 мільйон токенів на вході (без додаткової націнки за long context), до 128K токенів на виході.
Що робити, якщо мій код використовує temperature або extended thinking budgets?
Ці параметри більше не підтримуються у Opus 4.7 — виклики поверне 400-у помилку. Треба переключитись на адаптивний thinking та контролювати поведінку через промпти. Якщо не готові до міграції — можете поки використовувати Opus 4.6, але вона буде deprecated.
Чи варто одразу мігрувати на Opus 4.7?
Якщо ваша основна задача — coding або agentic workflows з мінімальним наглядом, тоді так, варто. Якщо ви будуєте простий чат-бот або класифікатор — Sonnet або навіть Haiku може бути достатньо. Перед міграцією обов'язково протестуйте існуючі промпти — літеральне слідування інструкціям може зламати поведінку.