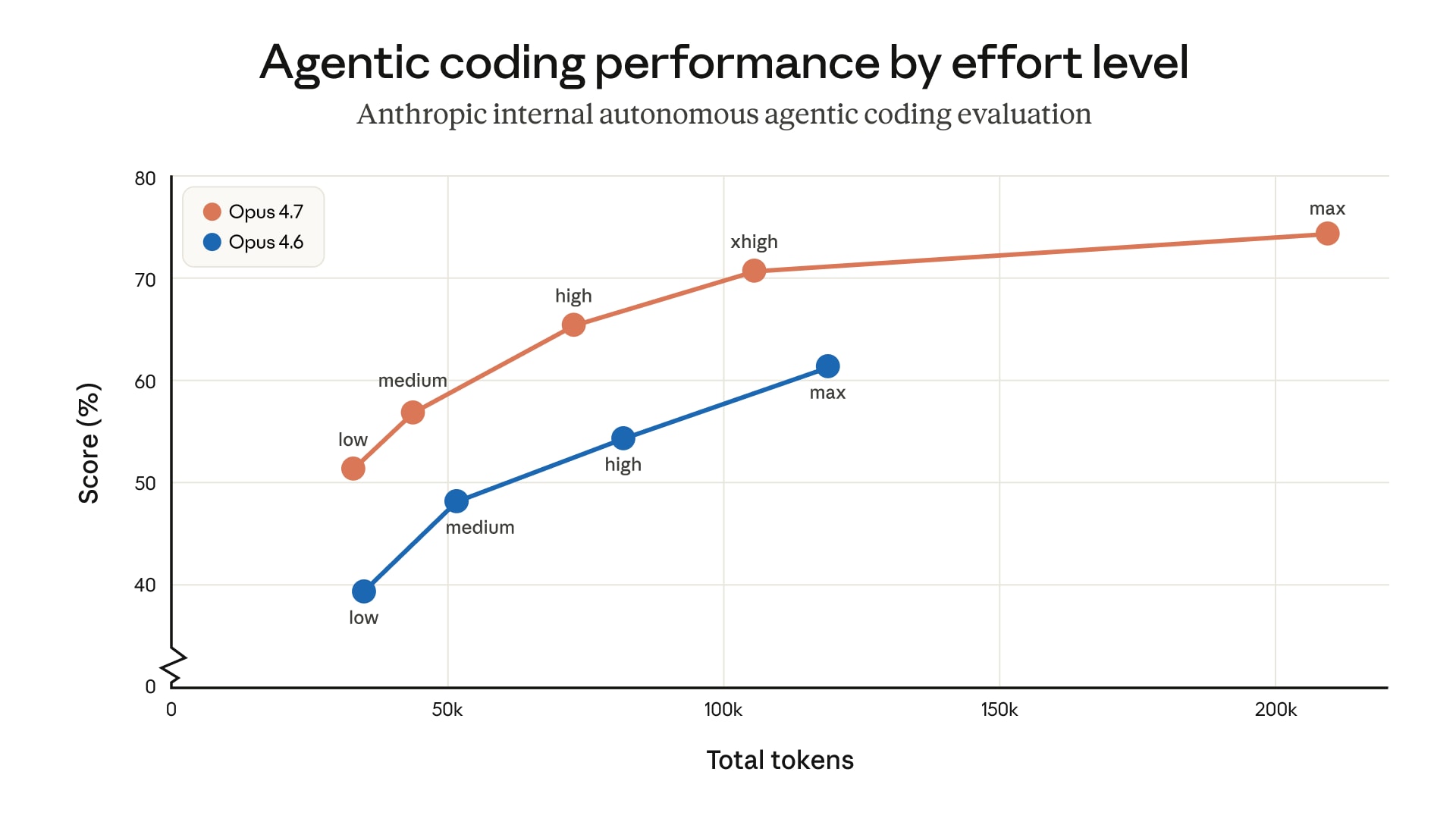
Claude Opus 4.7 ist Anthropic's neues Flaggschiff, das am 16. April 2026 veröffentlicht wurde. Highlights: +10,9 Punkte auf SWE-bench Pro (64,3 % gegenüber 53,4 % bei Opus 4.6), höhere Vision-Auflösung (3,75 MP), neues Dateisystem-basiertes Gedächtnis und ein neues Denklevel xhigh. Die Preise sind unverändert — 5 $/25 $ pro Million Tokens. Aber es gibt Breaking Changes: Der neue Tokenizer verbraucht 1,0–1,35x mehr Tokens für denselben Text, manuelles erweitertes Denken wird nicht mehr unterstützt, und das Modell folgt nun Anweisungen wörtlich — alte Prompts können kaputtgehen. Opus 4.7 ist nur Claude Mythos Preview unterlegen, die nicht öffentlich verfügbar ist. Ein Upgrade lohnt sich, wenn Sie mit Coding-Agenten, Computer-Nutzung oder RAG-Systemen arbeiten. Für einfache Chatbots ist der Gewinn minimal.
🚀 Was ist Claude Opus 4.7 und wie unterscheidet er sich von Opus 4.6
Opus 4.7 ist keine neue Generation, sondern ein iteratives Update von Opus 4.6 mit erheblichen Verbesserungen in den Bereichen Coding, Agenten-Workflows und Vision. Aber für Entwickler gibt es einige Breaking Changes, die berücksichtigt werden müssen.
Claude Opus 4.7 wurde am 16. April 2026 veröffentlicht und hat Opus 4.6 automatisch als Standardmodell in der Claude API und allen Claude-Produkten (Pro, Max, Team, Enterprise) abgelöst. Anthropic hält einen Veröffentlichungszyklus von etwa zwei Monaten ein: Opus 4.5 erschien im November 2025, Opus 4.6 im Februar 2026, Opus 4.7 im April 2026.
Die Hauptpositionierung von Anthropic: Opus 4.7 „folgt Anweisungen genauer, verifiziert seine eigenen Ausgaben, bevor es ein Ergebnis meldet, und bewältigt lange Aufgaben mit größerer Sorgfalt“. In der Praxis bedeutet dies, dass das Modell für Agentenszenarien konzipiert ist — dort, wo das Modell autonom ohne ständige Aufsicht arbeitet.
Wichtiger Kontext: Gleichzeitig mit Opus 4.7 erwähnt Anthropic Claude Mythos Preview — sein leistungsstärkstes Modell, das Opus 4.7 in allen Benchmarks übertrifft. Mythos ist jedoch nicht öffentlich verfügbar — es wurde nur Partnern im Rahmen des Project Glasswing Programms (Apple, Google, Microsoft und eine Reihe von Cybersicherheitsunternehmen) zur Verfügung gestellt. Daher ist Opus 4.7 für uns als Entwickler die tatsächliche Obergrenze der heute verfügbaren Möglichkeiten von Anthropic.
War / Wurde: Opus 4.6 vs Opus 4.7
Parameter
Opus 4.6 (Februar 2026)
Opus 4.7 (April 2026)
SWE-bench Verified
80,8 %
87,6 % (+6,8)
SWE-bench Pro
53,4 %
64,3 % (+10,9)
GPQA Diamond (reasoning)
91,3 %
94,2 % (+2,9)
OSWorld-Verified (computer use)
72,7 %
78,0 % (+5,3)
CursorBench
58 %
70 % (+12)
BrowseComp (agentic search)
83,7 %
79,3 % (-4,4)
Max vision resolution
1,15 MP (1568px)
3,75 MP (2576px)
Extended thinking
Manuell + adaptiv
Nur adaptiv
Tokenizer-Effizienz
Basis
1,0–1,35x Tokens für denselben Text
Preis
5 $ / 25 $ pro 1 Mio. Tokens
5 $ / 25 $ (unverändert)
Beachten Sie den Rückgang bei BrowseComp — dies ist der einzige Benchmark, bei dem Opus 4.7 zurückgefallen ist. BrowseComp testet die Fähigkeit des Modells, Informationen im Internet zu suchen, und hier verliert Opus 4.7 sowohl gegen Gemini 3.1 Pro (85,9 %) als auch gegen GPT-5.4 Pro (89,3 %). Wenn Ihr Agent viel mit Web-Recherche arbeitet — dies muss berücksichtigt werden.
⚙️ Wichtige technische Spezifikationen: Kontext, Reasoning, Tool Use
Fazit: 1 Mio. Token Kontext (ohne Premium-Aufschlag), 128K Ausgabe, neue Denklevel xhigh und max, Task Budgets zur Kostenkontrolle. Drei Breaking Changes, die alten Code kaputt machen können.
Kontextfenster und Ausgabe
Opus 4.7 hat das Kontextfenster von 1 Million Tokens von Opus 4.6 geerbt — im Standardpreis enthalten, ohne separaten Aufschlag für „langen Kontext“. Die maximale Ausgabe beträgt 128K Tokens. Für RAG-Systeme, in denen wir oft mit großen Dokumenten arbeiten, ist dies eine prinzipiell wichtige Zahl — eine Anfrage kann dem Äquivalent von über 750 Seiten Text entsprechen.
Neue Denklevel
Opus 4.7 hat jetzt vier Anstrengungslevel für Reasoning: low, medium, high, xhigh, max. Das neue xhigh ist ein Kompromiss zwischen high und max. Laut internen Daten von Anthropic erzielt max die höchsten Bewertungen (etwa 75 % bei Coding-Aufgaben), verbraucht aber deutlich mehr Tokens. xhigh ist der Sweet Spot zwischen Leistung und Kosten.
Für Claude Code wird standardmäßig auf allen Plänen xhigh verwendet. Für die API empfiehlt Anthropic, für Coding- und Agentenszenarien mit high oder xhigh zu beginnen.
Task Budgets — Kostenkontrolle
Eine neue Funktion in der Public Beta — task budgets. Sie legen eine harte Obergrenze für Token-Ausgaben für einen autonomen Agenten fest. Dies ist entscheidend, wenn Sie lange Debugging-Sitzungen oder mehrstufige Aufgaben ausführen — ohne dies kann ein einziger Fehler Ihr API-Guthaben auf Null setzen.
⚠️ Drei Breaking Changes, die Sie kennen sollten
Wenn Sie von Opus 4.6 auf 4.7 migrieren, können drei Dinge Ihren Code zum Absturz bringen:
Manueller erweiterter Denkprozess wird nicht mehr unterstützt. Jetzt nur noch adaptives Denken — das Modell entscheidet selbst, wie lange es nachdenkt. Wenn Sie extended_thinking.budget_tokens im Code gesetzt haben, gibt der Aufruf einen 400-Fehler zurück.
Sampling-Parameter funktionieren nicht mehr.temperature, top_p, top_k — bei dem Versuch, sie festzulegen, erhalten Sie eine 400-Fehlermeldung. Das Verhalten wird jetzt über Prompts gesteuert, nicht über Parameter.
Neuer Tokenizer — die tatsächlichen Kosten sind gestiegen. Derselbe Text wird jetzt in 1,0–1,35x mehr Tokens abgebildet. Der Preis pro Token ist mit 5 $/25 $ gleich geblieben, aber die tatsächlichen Kosten einer Anfrage können um 35 % steigen. Außerdem generiert das Modell bei hohen Anstrengungsleveln mehr Ausgabe-Tokens, da es „länger nachdenkt“. In der Praxis können die Mehrkosten noch höher sein.
Tool Use und Gedächtnis
Opus 4.7 ist das erste Claude-Modell, das die von Anthropic als „Implicit-Need-Tests“ bezeichneten Tests besteht. Dies sind Aufgaben, bei denen das Modell selbst erraten muss, welche Werkzeuge oder Aktionen benötigt werden, anstatt explizite Anweisungen zu erhalten. Im MCP-Atlas-Benchmark (skalierte Tool-Nutzung) erzielt Opus 4.7 77,3 % — das beste Ergebnis unter den öffentlich verfügbaren Modellen, einschließlich GPT-5.4.
Das Gedächtnis auf Dateisystembasis wurde ebenfalls verbessert — das Modell merkt sich wichtige Notizen über lange, mehrsitzige Arbeitsabläufe besser. Für unsere Aufgabe (RAG) ist dies weniger kritisch, da wir den Kontext normalerweise selbst verwalten. Aber für Agenten, die im Terminal oder in der IDE leben — ist dies eine spürbare Verbesserung.
💻 Wie Opus 4.7 mit Code und komplexen Aufgaben umgeht
Opus 4.7 ist das derzeit beste verfügbare Modell für die Programmierung. SWE-bench Pro stieg um 10,9 Punkte, CursorBench um 12. Aber es gibt einen Haken: Das Modell folgt nun Anweisungen wörtlich, daher können alte Prompts anders funktionieren.
Programmier-Benchmarks
Die Hauptgeschichte von Opus 4.7 ist genau das Coding. Die Zahlen:
Benchmark
Opus 4.7
Opus 4.6
GPT-5.4
Gemini 3.1 Pro
SWE-bench Verified
87,6 %
80,8 %
78,2 %
78,8 %
SWE-bench Pro
64,3 %
53,4 %
57,7 %
54,2 %
CursorBench
70 %
58 %
—
—
SWE-bench Pro ist eine komplexere Version von SWE-bench, die reale GitHub-Issues in vier Programmiersprachen testet. Der Sprung von 53,4 % auf 64,3 % ist der größte Coding-Gewinn in dieser Generation von Modellen.
Partner, die frühen Zugang hatten, bestätigen die Ergebnisse in ihren eigenen Benchmarks:
Hex — 13 % Gewinn auf einem 93-Task-Benchmark. Der geringe Aufwand von Opus 4.7 entspricht ungefähr dem mittleren Aufwand von Opus 4.6.
CodeRabbit — Recall stieg um 10 %+ beim Code-Review, Präzision blieb stabil.
Warp — Terminal-Bench-Aufgaben, die frühere Claude-Modelle nicht lösen konnten, wurden erfolgreich abgeschlossen.
Rakuten-SWE-Bench — 3x mehr gelöste Produktionsaufgaben im Vergleich zu Opus 4.6.
Neuer Befehl /ultrareview in Claude Code
In Claude Code gibt es den Befehl /ultrareview — Multi-Agent Code Review. Anstatt einer einzelnen Claude-Instanz, die den Code scannt, startet /ultrareview mehrere spezialisierte Agenten (einer für Sicherheit, einer für Logik, einer für Leistung, einer für Stil) und fasst deren Ergebnisse in einem einzigen Bericht zusammen. Laut Anthropic-Beschreibung — „als würden vier Senior-Entwickler gleichzeitig Ihren PR überprüfen“.
⚠️ Haken: Wörtliche Befolgung von Anweisungen
Wichtige Warnung von Anthropic: Opus 4.7 folgt Anweisungen wörtlich. Opus 4.6 hat oft „zwischen den Zeilen gelesen“ — er konnte Anweisungen abschwächen oder Teile überspringen, die er für unwichtig hielt. Opus 4.7 führt genau das aus, was geschrieben steht.
In der Praxis bedeutet dies: Wenn Ihr Prompt unklare oder widersprüchliche Formulierungen enthält, kann Opus 4.7 unerwartet reagieren. Anthropic empfiehlt, die Prompts nach der Migration zu überprüfen — insbesondere wenn sie für 4.5 oder 4.6 geschrieben wurden.
🎯 Haben sich Halluzinationen im Vergleich zur Vorgängerversion verringert?
Bei Fragen, die auf fiktiven Fakten basieren, ist Opus 4.7 auf dem Niveau von 4.6. Unter Druck (wenn der Benutzer oder der System-Prompt das Modell dazu bringt, seiner eigenen Einschätzung zu widersprechen) ist 4.7 ehrlicher, aber weniger hartnäckig als Mythos Preview. Die Resistenz gegen Prompt-Injection wurde verbessert.
Laut der System Card von Anthropic hat Opus 4.7 ein ähnliches Sicherheitsprofil wie Opus 4.6. Bei Fragen zu fiktiven Fakten blieb die Genauigkeit erhalten – ohne Verschlechterung, aber auch ohne signifikante Verbesserung.
Wichtige Änderungen:
Prompt-Injection-Resistenz – spürbar verbessert. Dies ist entscheidend für RAG-Systeme und öffentliche Chatbots.
Ehrlichkeit unter Druck – Opus 4.7 behält seine Position häufiger bei, wenn der Benutzer Druck ausübt. Aber weniger hartnäckig als Mythos.
Selbstüberprüfung – ein neues Verhaltensmerkmal: Das Modell erstellt interne Tests, um seine eigene Antwort zu überprüfen, bevor es sie ausgibt. Dies erklärt teilweise den Zuwachs bei SWE-bench.
KI-Sicherheitsforschung – das Modell weigert sich immer noch in 33% der Fälle, bei legitimen Sicherheitsforschungsaufgaben zu helfen. Dies ist eine deutliche Verbesserung gegenüber 88% bei Opus 4.6, aber das Problem bleibt bestehen.
Interessantes Feedback von Partner Hex: „Opus 4.7 meldet korrekt, wenn Daten fehlen, anstatt plausible, aber falsche Antworten zu geben, und widersteht Fallen mit widersprüchlichen Daten, in die selbst Opus 4.6 tappte.“ Für RAG-Systeme ist dies eine Schlüssel eigenschaft – die Antwort „Ich weiß es nicht“ ist oft wertvoller als eine selbstbewusste Halluzination.
💰 Wie viel kostet die Nutzung von Opus 4.7 über die API?
Kurzes Fazit: Der Preis pro Token ist derselbe – 5 $ Input / 25 $ Output pro 1 Mio. Token. Die tatsächlichen Kosten pro Anfrage sind jedoch aufgrund des neuen Tokenizers (1,0–1,35-fache Token) und der Tendenz des Modells, bei hohen Anstrengungsstufen länger nachzudenken, gestiegen.
Grundpreis
Modell
Input (pro 1 Mio. Token)
Output (pro 1 Mio. Token)
Claude Opus 4.7
$5
$25
Claude Opus 4.6
$5
$25
GPT-5.4
Höher (genaue Zahlen hängen von der Konfiguration ab)
Höher
Gemini 3.1 Pro
$2
$12
Als ich die Preise für meine Kunden verglich, fiel Gemini 3.1 Pro sofort auf – er ist fast dreimal günstiger als Opus 4.7. Wenn Sie eine grundlegende Generierung ohne strenge Anforderungen an Coding oder Agenten-Workflows haben, kann Gemini eine kostengünstigere Wahl sein, und ich empfehle ihn selbst in solchen Szenarien. Aber bei geschäftskritischen Benchmarks (SWE-bench, MCP-Atlas) führt Opus 4.7 mit deutlichem Vorsprung – und in meinen realen Tests für RAG-Aufgaben rechtfertigt der Unterschied in der Antwortqualität den Premium-Preis.
Möglichkeiten zum Sparen
Prompt-Caching – bis zu 90 % Rabatt auf wiederkehrende Kontextteile. Für RAG-Systeme, bei denen der System-Prompt groß ist, ist dies ein Muss.
Batch-API – 50 % Rabatt auf Input und Output für Aufgaben, die keine Echtzeitverarbeitung erfordern.
Task-Budgets – ein festes Ausgabenlimit für Agenten, Schutz vor unerwarteten Rechnungen.
⚠️ Tatsächliche Kosten: Ich sah nach der Migration +23 % Kosten
Hier liegt das Wichtigste, und wovor ich warnen möchte. Der offizielle Preis pro Token hat sich nicht geändert, aber der neue Tokenizer ordnet denselben Text 1,0–1,35-mal mehr Token zu. Außerdem denkt das Modell bei hohen Anstrengungsstufen länger nach und generiert mehr Output. Für Produktionsanwendungen mit geringer Marge kann dies eine unangenehme Überraschung sein – ich habe es unmittelbar nach der Veröffentlichung selbst erlebt.
Ich habe Opus 4.7 am Tag nach der Veröffentlichung des Modells unter realer Last von AskYourDocs getestet. Ohne jegliche Änderungen an der Systemlogik – ich habe lediglich die Model-ID von claude-opus-4-6 auf claude-opus-4-7 umgestellt. Die Kosten für die Verarbeitung derselben Anfragen stiegen aufgrund der neuen Tokenisierung um etwa 23 %. Ich musste sofort den System-Prompt überarbeiten, Duplizierungen reduzieren und Prompt-Caching aktivieren.
Mein praktischer Ansatz, den ich jetzt für Kunden festlege: Fügen Sie bei der Migration von 4.6 zunächst +20-25 % zum API-Budget hinzu und optimieren Sie dann basierend auf tatsächlichen Daten. Nach einigen Tagen aktiver Nutzung werden Sie Wege finden, diese Kosten zu senken – durch Caching und überarbeitete Prompts.
Opus 4.7 ist über die Claude API (Modell-ID claude-opus-4-7), Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry und OpenRouter verfügbar – ich persönlich nutze OpenRouter für AskYourDocs (dies ermöglicht es Kunden, einfach zwischen Modellen zu wechseln, ohne den Code zu ändern), die direkte Claude API für Tests und empfehle Bedrock Kunden, denen die AWS-Infrastruktur wichtig ist.
🎯 Wo Opus 4.7 am besten abschneidet: 3 reale Szenarien
Opus 4.7 ist ein Modell für Aufgaben, bei denen die Kosten eines Fehlers hoch sind und die Autonomie entscheidend ist. Nicht immer die beste Wahl für einfache Anwendungsfälle.
Szenario 1: Autonome Coding-Agenten
Dies ist die größte Stärke von Opus 4.7. Ein Zuwachs von 12 Punkten bei CursorBench und 10,9 bei SWE-bench Pro ist kein Marketing, sondern ein realer Unterschied in der Produktion. Wenn Sie einen Agenten starten, der selbst einen Fehler finden, einen Patch schreiben und Tests bestehen soll – Opus 4.7 erledigt dies zuverlässiger als alle bisherigen Modelle. Partner Warp bestätigte: Besteht Terminal-Bench-Aufgaben, die frühere Claude-Modelle nicht bestanden haben.
Wann es sich lohnt: Entwicklung, bei der das Modell lange ohne Aufsicht läuft, mehrstufige Refactorings, Code-Reviews, Integrationsaufgaben in Claude Code.
Szenario 2: Computer-Nutzung und visuelle Agenten
Die maximale Bildauflösung wurde um das 3-fache erhöht – auf 3,75 MP. Koordinaten werden nun 1:1 mit Pixeln abgebildet, was die Notwendigkeit von Skalierungsfaktor-Mathematik eliminiert. Bei OSWorld-Verified – 78,0 % gegenüber 72,7 % bei 4.6.
Wann es sich lohnt: Agenten, die Screenshots, Dashboards, technische Diagramme, PDFs mit komplexer Formatierung lesen. Für die Dokumentenanalyse ist die Möglichkeit, kleinen Text in gescannten Dokumenten zu lesen, ein Game Changer.
Szenario 3: Agenten-RAG mit Überprüfung eigener Antworten
Dies ist das Szenario, das mich am meisten interessiert und in dem ich Opus 4.7 verwende. Das neue Selbstüberprüfungsverhalten – das Modell erstellt interne Tests, um seine Antworten zu überprüfen – reduziert die Anzahl selbstbewusster Halluzinationen in RAG spürbar. Bei Fragen, bei denen die Antwort nicht in den Dokumenten vorhanden ist, sagt Opus 4.7 häufiger „Ich weiß es nicht“, anstatt sich etwas auszudenken.
Wann es sich lohnt: Unternehmens-KI-Assistenten, bei denen Genauigkeit wichtiger ist als Geschwindigkeit, Antwortsysteme basierend auf juristischen oder medizinischen Dokumenten, komplexe Enterprise-Wissensdatenbanken.
❌ Für wen Claude Opus 4.7 NICHT geeignet ist
Opus 4.7 ist ein Premium-Tool für komplexe Aufgaben. Für einfache Szenarien kann es übertrieben sein und Sie zahlen zu viel.
Seien Sie ehrlich zu sich selbst – Opus 4.7 ist nicht immer die richtige Wahl. Nehmen Sie es nicht, wenn:
Sie einen einfachen Chatbot mit FAQs haben. Für 30-50 typische Fragen ist selbst Sonnet übertrieben, ganz zu schweigen von Opus. Sie zahlen das 5-10-fache, ohne Qualitätssteigerung.
Sie einen möglichst günstigen Output benötigen. Gemini 3.1 Pro ist beim Input 2,5-mal und beim Output doppelt so günstig. Für Massenaufgaben einfacher Klassifizierung kann dies wirtschaftlich sinnvoll sein.
Ihre Hauptaufgabe ist die Web-Recherche. Opus 4.7 hat bei BrowseComp nachgelassen (79,3 % gegenüber 89,3 % bei GPT-5.4 Pro). Wenn ein Agent auf dem Durchsuchen von Websites basiert, schauen Sie sich GPT-5.4 Pro oder Gemini an.
Sie eine Self-Hosted-Lösung benötigen. Anthropic bietet keinen On-Premise-Zugriff. Wenn Sie mit medizinischen Daten, juristischen Dokumenten arbeiten oder einfach strenge DSGVO-Anforderungen haben, benötigen Sie ein Open-Source-Modell auf Ihrem eigenen Server (Llama 3.3 70B, Qwen, Mistral usw.).
Sie viele alte Prompts haben, die Sie nicht überarbeiten möchten. Wörtliche Befolgung von Anweisungen kann das Verhalten, das in 4.6 funktionierte, beeinträchtigen. Wenn Sie keine Ressourcen für Tests haben, bleiben Sie bei 4.6, solange es verfügbar ist.
Ihr API-Code aktiv temperature/top_p oder manuelles extended thinking verwendet. Sie erhalten 400er-Fehler. Die Migration erfordert Arbeit.
👨💻 Meine Erfahrung mit Opus 4.7 im RAG-System AskYourDocs
Mein Stack: Spring Boot, PostgreSQL, pgvector, Ollama für lokale Entwicklung, OpenRouter für Produktion. Das Hauptproduktionsmodell ist Llama 3.3 70B. Ich habe Opus 4.7 als Premium-Option für Kunden getestet, die maximale Antwortqualität benötigen.
AskYourDocs ist ein RAG-System, das ich als B2B-SaaS aufbaue: ein unternehmensweites Wissensmanagement basierend auf Kundendokumenten mit einem Self-Hosted-Ansatz. Wir sind Multi-Vendor – der Kunde kann die LLM für seine Aufgabe und sein Budget wählen. Deshalb habe ich Opus 4.7 als eine der Optionen integriert, nicht als einzige Option.
Was ich beim Testen von Opus 4.7 im Vergleich zu Llama 3.3 70B auf Dokumenten (~400 PDFs aus dem juristischen Bereich) festgestellt habe:
„Ich weiß nicht“ statt Halluzinationen. Die auffälligste Beobachtung. Bei Fragen, auf die die Antwort in der Datenbank nicht vorhanden war, gab Llama 3.3 70B in einigen Fällen eine plausible Erfindung aus. Opus 4.7 sagt ehrlich: „Die Dokumente enthalten keine Informationen“. Für die juristische Nische ist dies ein kritisch wichtiger Unterschied – ich habe dies sofort als Hauptvorteil für Kunden hervorgehoben, die Angst vor Fehlern in den Antworten auf Kundenanfragen haben.
Bessere Retrieval-Qualität durch Tool-Nutzung. Wenn ich dem Modell Werkzeuge für Self-Querying gebe (Suche nach Metadaten, Filterung nach Datum), macht Opus 4.7 dies deutlich genauer. Llama stellt oft suboptimale Anfragen – man muss im System-Prompt viel erklären. Mit Opus 4.7 kann dieser Prompt erheblich gekürzt werden.
Kosten – ernsthaft. Nach meinen Berechnungen für ein typisches Kundenprofil (~1000 Anfragen pro Tag, durchschnittlicher Kontext 8-12K Token) ist Opus 4.7 über OpenRouter 10-15x teurer als Llama 3.3 70B. Für Kunden mit 20-30 Mitarbeitern ist das in Ordnung, für Unternehmen mit Tausenden muss man rechnen.
Wörtliche Befolgung von Anweisungen – ein Gewinn für RAG. Wenn ich im Prompt schreibe „Antworte nur basierend auf dem Kontext, verwende kein allgemeines Wissen“ – Opus 4.7 tut dies tatsächlich. 4.6 fügte manchmal „etwas von sich aus hinzu“, was bei RAG kritisch inakzeptabel ist.
Der neue Tokenizer schlug sofort auf das Budget. In meinem ersten Testlauf nach der Migration stiegen die Kosten für die Verarbeitung desselben Satzes von Anfragen um etwa 23 % – genau wegen der neuen Tokenisierung. Ich musste sofort den System-Prompt überarbeiten, Duplizierungen entfernen und Prompt-Caching aktivieren.
Mein heutiger Arbeitskompromiss: Llama 3.3 70B als Standard für die meisten Kunden, Opus 4.7 als „Premium“ für Nischen, in denen die Kosten eines Fehlers hoch sind (Anwälte, Finanzen, Medizin). Die Wahl wird in einer einzigen Konfigurationszeile eingestellt – der Kunde kann selbst wechseln.
Für meinen Mac M1 verwende ich weiterhin Ollama mit lokalen Modellen für die Entwicklung (mehr über die Wahl zwischen 8 GB und 16 GB RAM – in einem separaten Artikel). Opus 4.7 über API – nur für Produktion oder komplexes Testen.
❓ FAQ: Claude Opus 4.7
Wann wurde Claude Opus 4.7 veröffentlicht?
Am 16. April 2026. Dies ist das vierte Opus-Update in einem halben Jahr (4.1, 4.5, 4.6, 4.7), Anthropic hält die Veröffentlichungsfrequenz von etwa alle 2 Monate ein.
Was unterscheidet Opus 4.7 von Opus 4.6?
Hauptsächlich Coding und Agentic Workflows. SWE-bench Pro stieg von 53,4 % auf 64,3 %, CursorBench – von 58 % auf 70 %. Vision (3x höhere Auflösung), Tool-Nutzung und Speicher wurden verbessert. Es gibt Breaking Changes: neuer Tokenizer, nur adaptives extended thinking, sampling-Parameter funktionieren nicht mehr.
Wie viel kostet Claude Opus 4.7 über API?
5 $ pro 1 Mio. Input-Token und 25 $ pro 1 Mio. Output-Token – derselbe Preis wie bei Opus 4.6. Die tatsächlichen Kosten pro Anfrage sind jedoch aufgrund des neuen Tokenizers (1,0–1,35x mehr Token bei gleichem Text) und der Tendenz des Modells, bei hohen Anstrengungsstufen länger nachzudenken, gestiegen.
Wird Claude Opus 4.7 GPT-5.4 oder Gemini 3.1 Pro ersetzen?
Bei Coding-Aufgaben – ja, Opus 4.7 führt. Bei GPQA Diamond (grafisches Reasoning) sind die Modelle praktisch gleich – der Unterschied liegt innerhalb der Fehlertoleranz. Bei Web-Recherche (BrowseComp) verliert Opus 4.7. Die Wahl hängt vom spezifischen Anwendungsfall ab.
Kann Claude Opus 4.7 für RAG verwendet werden?
Ja, und es funktioniert gut – besonders dort, wo die Ehrlichkeit des Modells („Ich weiß nicht“ statt Halluzinationen) und die Resistenz gegen Prompt Injection kritisch sind. Für die meisten RAG-Aufgaben reichen jedoch günstigere Open-Source-Modelle wie Llama 3.3 70B aus. Opus 4.7 ist in Nischen mit hohen Fehlerkosten gerechtfertigt.
Ist Claude Opus 4.7 das beste Modell von Anthropic?
Unter den öffentlich verfügbaren – ja. Aber Anthropic hat auch Mythos Preview, das Opus 4.7 bei allen Benchmarks übertrifft. Mythos ist nur für Partner im Rahmen von Project Glasswing (Apple, Google, Microsoft) verfügbar und wird in naher Zukunft nicht allgemein verfügbar sein.
Welches Kontextfenster hat Claude Opus 4.7?
1 Million Token für den Input (ohne zusätzliche Gebühr für langen Kontext), bis zu 128K Token für den Output.
Was tun, wenn mein Code temperature oder extended thinking budgets verwendet?
Diese Parameter werden in Opus 4.7 nicht mehr unterstützt – Aufrufe geben einen 400er-Fehler zurück. Sie müssen auf adaptives Denken umsteigen und das Verhalten über Prompts steuern. Wenn Sie nicht bereit für die Migration sind, können Sie Opus 4.6 vorerst weiter verwenden, aber es wird veraltet sein.
Lohnt sich die sofortige Migration auf Opus 4.7?
Wenn Ihre Hauptaufgabe Coding oder Agentic Workflows mit minimaler Überwachung ist, dann ja, es lohnt sich. Wenn Sie einen einfachen Chatbot oder Klassifikator erstellen, kann Sonnet oder sogar Haiku ausreichend sein. Testen Sie unbedingt Ihre bestehenden Prompts vor der Migration – wörtliche Befolgung von Anweisungen kann das Verhalten beeinträchtigen.