Claude Opus 4.7 is Anthropic's new flagship, released on April 16, 2026. Key highlights: +10.9 points on SWE-bench Pro (64.3% vs. 53.4% for Opus 4.6), higher vision resolution (3.75 MP), new file system-level memory, and a new xhigh reasoning tier. Pricing remains unchanged at $5 / $25 per million tokens. However, there are breaking changes: the new tokenizer uses 1.0–1.35x more tokens for the same text, manual extended thinking is no longer supported, and the model now follows instructions literally – old prompts may break. Opus 4.7 is only surpassed by Claude Mythos Preview, which is not publicly available. It's worth upgrading if you work with coding agents, computer use, or RAG systems. For simple chatbots, the gains are minimal.
🚀 What is Claude Opus 4.7 and how does it differ from Opus 4.6
Opus 4.7 is not a new generation but an iterative update to Opus 4.6 with significant improvements in coding, agentic workflows, and vision. However, for developers, there are several breaking changes to consider.
Claude Opus 4.7 was released on April 16, 2026, and automatically replaced Opus 4.6 as the default model in Claude API and all Claude products (Pro, Max, Team, Enterprise). Anthropic maintains a release cadence of approximately every two months: Opus 4.5 was released in November 2025, Opus 4.6 in February 2026, and Opus 4.7 in April 2026.
Anthropic's main positioning: Opus 4.7 "follows instructions more accurately, verifies its own output before reporting results, and handles long tasks with greater thoroughness." In practice, this means the model is designed for agentic scenarios – where the model operates autonomously without constant supervision.
Important context: Alongside Opus 4.7, Anthropic mentions Claude Mythos Preview – their most powerful model, which outperforms Opus 4.7 on all benchmarks. However, Mythos is not publicly available – it has only been provided to partners through the Project Glasswing program (Apple, Google, Microsoft, and several cybersecurity companies). Therefore, for us as developers, Opus 4.7 represents the current practical ceiling of Anthropic's capabilities.
Before / After: Opus 4.6 vs. Opus 4.7
Parameter
Opus 4.6 (February 2026)
Opus 4.7 (April 2026)
SWE-bench Verified
80.8%
87.6% (+6.8)
SWE-bench Pro
53.4%
64.3% (+10.9)
GPQA Diamond (reasoning)
91.3%
94.2% (+2.9)
OSWorld-Verified (computer use)
72.7%
78.0% (+5.3)
CursorBench
58%
70% (+12)
BrowseComp (agentic search)
83.7%
79.3% (-4.4)
Max vision resolution
1.15 MP (1568px)
3.75 MP (2576px)
Extended thinking
Manual + adaptive
Adaptive only
Tokenizer efficiency
Base
1.0–1.35x tokens for the same text
Price
$5 / $25 per 1M tokens
$5 / $25 (no change)
Note the decrease in BrowseComp – this is the only benchmark where Opus 4.7 regressed. BrowseComp tests the model's ability to search for information on the internet, and here Opus 4.7 loses to both Gemini 3.1 Pro (85.9%) and GPT-5.4 Pro (89.3%). If your agent performs a lot of web research, this needs to be taken into account.
⚙️ Key Technical Specifications: Context, Reasoning, Tool Use
Conclusion: 1M token context (no premium surcharge), 128K output, new xhigh and max reasoning tiers, task budgets for cost control. Three breaking changes that could break old code.
Context window and output
Opus 4.7 inherits the 1 million token context window from Opus 4.6 – included in the standard price, with no separate surcharge for "long context." The maximum output is 128K tokens. For RAG systems, where we often work with large documents, this is a critically important figure – you can fit the equivalent of 750+ pages of text into a single query.
New reasoning tiers
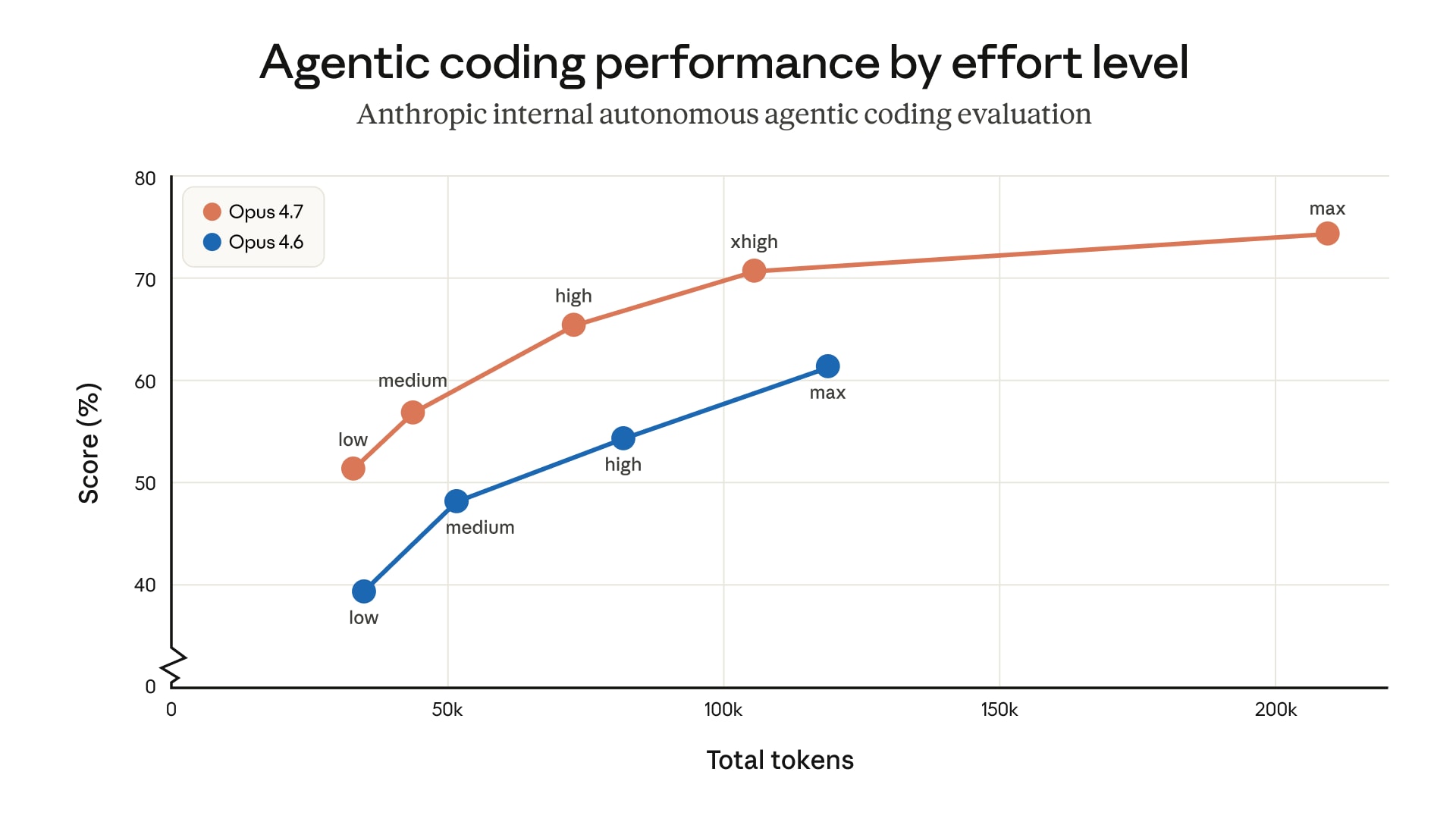
Opus 4.7 now has four effort tiers for reasoning: low, medium, high, xhigh, and max. The new xhigh is a compromise between high and max. According to Anthropic's internal data, max yields the highest scores (around 75% on coding tasks) but consumes significantly more tokens. xhigh is the sweet spot between performance and cost.
For Claude Code, xhigh is now used by default on all plans. For the API, Anthropic recommends starting with high or xhigh for coding and agentic scenarios.
Task budgets — cost control
A new feature in public beta is task budgets. You set a hard token spending limit for an autonomous agent. This is crucial if you're running long debugging sessions or multi-step tasks – without it, a single error could wipe out your API balance.
⚠️ Three breaking changes you need to know about
If you are migrating from Opus 4.6 to 4.7, three things might break your code:
Manual extended thinking is no longer supported. Now it's adaptive thinking only – the model decides how long to think. If you set extended_thinking.budget_tokens in your code, the call will return a 400 error.
Sampling parameters no longer work.temperature, top_p, top_k – attempting to set them will result in a 400 error. You now need to control behavior through prompts, not parameters.
New tokenizer – actual cost has increased. The same text now maps to 1.0–1.35x more tokens. The price per token remains $5 / $25, but the actual cost of a request can increase by 35%. Plus, the model generates more output tokens at higher effort levels because it "thinks longer." In practice, the overpayment could be even greater.
Tool use and memory
Opus 4.7 is the first Claude model to pass what Anthropic calls "implicit-need tests." These are tasks where the model has to guess the necessary tools or actions itself, rather than receiving explicit instructions. On the MCP-Atlas benchmark (scaled tool use), Opus 4.7 scores 77.3% – the best result among publicly available models, including GPT-5.4.
Memory based on the file system has also been improved – the model better remembers important notes through long, multi-session workflows. For our task (RAG), this is less critical as we usually manage context ourselves. But for agents that live in the terminal or IDE, this is a noticeable improvement.
💻 How Opus 4.7 Handles Code and Complex Tasks
Opus 4.7 is the best model available for programming today. SWE-bench Pro has improved by 10.9 points, CursorBench by 12. But there's a nuance: the model now follows instructions literally, so old prompts might behave differently.
Programming Benchmarks
The main story for Opus 4.7 is coding. The numbers:
Benchmark
Opus 4.7
Opus 4.6
GPT-5.4
Gemini 3.1 Pro
SWE-bench Verified
87.6%
80.8%
78.2%
78.8%
SWE-bench Pro
64.3%
53.4%
57.7%
54.2%
CursorBench
70%
58%
—
—
SWE-bench Pro is a more complex version of SWE-bench, testing real GitHub issues across four programming languages. The jump from 53.4% to 64.3% is the largest coding gain in this generation of models.
Partners who had early access confirm the results on their own benchmarks:
Hex – 13% gain on a 93-task benchmark. Opus 4.7's low effort is roughly equivalent to Opus 4.6's medium effort.
CodeRabbit – recall increased by 10%+ on code review, precision remained stable.
Warp – Terminal-Bench tasks that previous Claudes couldn't solve were completed successfully.
Rakuten-SWE-Bench – 3x more production tasks solved compared to Opus 4.6.
New /ultrareview command in Claude Code
A new command, /ultrareview, has been added to Claude Code – multi-agent code review. Instead of a single Claude instance scanning the code, /ultrareview launches several specialized agents (one for security, one for logic, one for performance, one for style) and synthesizes their results into a single report. According to Anthropic's description – "like four senior engineers reviewing your PR simultaneously."
⚠️ Nuance: Literal instruction following
An important warning from Anthropic: Opus 4.7 follows instructions literally. Opus 4.6 often "read between the lines" – it might soften instructions or skip parts it deemed unimportant. Opus 4.7 executes exactly what is written.
In practice, this means: if your prompt contains vague or contradictory phrasing, Opus 4.7 might behave unexpectedly. Anthropic recommends reviewing prompts after migration – especially if they were written for 4.5 or 4.6.
🎯 Did hallucinations decrease compared to the previous version
On questions based on fictional facts, Opus 4.7 is on par with 4.6. Under pressure (when the user or system prompt pushes the model to contradict its own assessment) — 4.7 is more honest, but less firm than Mythos Preview. Prompt injection resistance — improved.
According to Anthropic's System Card, Opus 4.7 has a similar safety profile to Opus 4.6. On questions about fictional facts, accuracy has been maintained — without degradation, but also without significant improvement.
Important changes:
Prompt injection resistance — noticeably improved. This is critical for RAG systems and public chatbots.
Honesty under pressure — Opus 4.7 more often holds its ground when the user pressures it. But less firmly than Mythos.
Self-verification — a new behavioral feature: the model creates internal tests to verify its own answer before delivering it. This partially explains the gain on SWE-bench.
AI safety research — the model still refuses to help with legitimate safety research tasks in 33% of cases. This is a significant improvement from 88% in Opus 4.6, but the problem remains.
Interesting feedback from partner Hex: "Opus 4.7 correctly reports when data is missing, instead of providing plausible-but-incorrect answers, and resists traps with contradictory data that even Opus 4.6 fell into." For RAG systems, this is a key feature — an "I don't know" answer is often more valuable than a confident hallucination.
💰 How much does it cost to use Opus 4.7 via API
Quick summary: the price per token is the same — $5 input / $25 output per 1M tokens. However, the actual cost of a request has increased due to the new tokenizer (1.0–1.35× tokens) and the model's tendency to think longer at high effort levels.
Base Price
Model
Input (per 1M tokens)
Output (per 1M tokens)
Claude Opus 4.7
$5
$25
Claude Opus 4.6
$5
$25
GPT-5.4
Higher (exact figures depend on configuration)
Higher
Gemini 3.1 Pro
$2
$12
When I compared prices for my clients, Gemini 3.1 Pro immediately caught my attention — it's almost three times cheaper than Opus 4.7. If you have basic generation without strict requirements for coding or agentic workflows, Gemini can be a more cost-effective choice, and I personally recommend it in such scenarios. However, on key business benchmarks (SWE-bench, MCP-Atlas), Opus 4.7 leads by a significant margin — and in my real-world tests on RAG tasks, the difference in response quality justifies the premium.
Ways to Save
Prompt caching — up to 90% discount on repeated parts of the context. For RAG systems with large system prompts, this is a must-have.
Batch API — 50% discount on input and output for tasks that don't require real-time processing.
Task budgets — a hard limit on agent expenses, protecting against unexpected bills.
⚠️ Real Cost: I encountered +23% expenses after migration
This is the most important part, and what I want to warn you about. The official price per token hasn't changed, but the new tokenizer maps the same text to 1.0–1.35× more tokens. Plus, the model thinks longer at high effort levels and generates more output. For production applications with thin margins, this can be an unpleasant surprise — I experienced it myself immediately after the release.
I tested Opus 4.7 on the real load of AskYourDocs the day after the model was released. Without any changes to the system logic — I simply swapped the model ID from claude-opus-4-6 to claude-opus-4-7. The cost of processing the same requests increased by approximately 23% due to the new tokenization. I had to immediately review the system prompt, reduce duplication, and enable prompt caching.
My practical preset, which I now set for clients: when migrating from 4.6, add +20-25% to the API budget initially, and then optimize based on actual data. After a few days of active use, you will find ways to reduce these costs — through caching and a rewritten prompt.
Opus 4.7 is available through the Claude API (model ID claude-opus-4-7), Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry, and OpenRouter — I personally use OpenRouter for AskYourDocs (this allows clients to easily switch between models without changing code), the direct Claude API for testing, and I recommend Bedrock to clients for whom AWS infrastructure is important.
🎯 Where Opus 4.7 performs best: 3 real-world scenarios
Opus 4.7 is a model for tasks where the cost of error is high and autonomy is critical. Not always the best choice for simple use cases.
Scenario 1: Autonomous coding agents
This is Opus 4.7's strongest suit. A 12-point gain on CursorBench and 10.9 on SWE-bench Pro is not marketing, but a real difference in production. If you are running an agent that needs to find a bug, write a patch, and pass tests on its own — Opus 4.7 does it more reliably than all previous models. Partner Warp confirmed: it passes Terminal-Bench tasks that previous Claudes did not.
When to use: development where the model runs for a long time without supervision, multi-step refactorings, code review, integration tasks in Claude Code.
Scenario 2: Computer use and visual agents
Maximum image resolution has increased by 3× — to 3.75 MP. Coordinates now map 1:1 with pixels, eliminating the need for scale-factor math. On OSWorld-Verified — 78.0% compared to 72.7% for 4.6.
When to use: agents that read screenshots, dashboards, technical diagrams, PDFs with complex formatting. For document analysis — the ability to read small text in scanned documents is a game changer.
Scenario 3: Agentic RAG with self-verification
This is the scenario that interests me the most and where I use Opus 4.7. The new self-verification behavior — the model creates internal tests to verify its answers — noticeably reduces the level of confident hallucinations in RAG. For questions where the answer is not in the documents, Opus 4.7 more often says "I don't know" instead of making things up.
When to use: corporate AI assistants where accuracy is more important than speed, response systems based on legal or medical documents, complex enterprise knowledge bases.
❌ Who Claude Opus 4.7 is NOT for
Opus 4.7 is a premium tool for complex tasks. For simple scenarios, it can be overkill and you'll overpay.
Be honest with yourself — Opus 4.7 isn't always the right choice. Don't get it if:
You have a simple FAQ chatbot. For 30-50 typical questions, even Sonnet is excessive, let alone Opus. You'll overpay 5-10 times without any quality improvement.
You need the cheapest possible output. Gemini 3.1 Pro is 2.5 times cheaper on input and twice as cheap on output. For mass simple classification tasks, this can be economically justified.
Your main task is web research. Opus 4.7 has dropped on BrowseComp (79.3% vs. 89.3% for GPT-5.4 Pro). If your agent lives on browsing websites, look at GPT-5.4 Pro or Gemini.
You need a self-hosted solution. Anthropic does not provide on-premise access. If you work with medical data, legal documents, or simply have strict GDPR requirements, you need an open-source model on your own server (Llama 3.3 70B, Qwen, Mistral, etc.).
You have many old prompts that you are not ready to review. Literal adherence to instructions can break behavior that worked in 4.6. If you don't have resources for testing, stick with 4.6 while it's available.
Your API code actively uses temperature/top_p or manual extended thinking. You will get 400 errors. Migration requires work.
👨💻 My Experience with Opus 4.7 in the AskYourDocs RAG System
My stack: Spring Boot, PostgreSQL, pgvector, Ollama for local dev, OpenRouter for production. The main production model is Llama 3.3 70B. I tested Opus 4.7 as a premium option for clients who need maximum response quality.
AskYourDocs is a RAG system that I am building as a B2B SaaS: a corporate knowledge base based on client documents with a self-hosted approach. We are multi-vendor — clients can choose an LLM for their task and budget. Therefore, I integrated Opus 4.7 as one of the options, not the only one.
What I observed during testing Opus 4.7 against Llama 3.3 70B on documents (~400 PDFs from the legal field):
"I don't know" instead of hallucination. The most noticeable observation. For questions where there was no answer in the database, Llama 3.3 70B in some cases provided plausible fabrications. Opus 4.7 honestly states "there is no information in the documents." For the legal niche, this is a critically important difference — I immediately noted this as a key advantage for clients who fear errors in responses to customer inquiries.
Better retrieval quality through tool use. When I gave the model tools for self-querying (search by metadata, filter by dates), Opus 4.7 does it much more accurately. Llama often makes suboptimal queries — you have to explain a lot in the system prompt. With Opus 4.7, this prompt can be significantly shortened.
Cost is serious. According to my calculations for a typical client profile (~1000 requests per day, average context 8-12K tokens), Opus 4.7 is 10-15× more expensive than Llama 3.3 70B via OpenRouter. For clients with 20-30 employees, this is acceptable; for enterprises with thousands, it needs to be calculated.
Literal adherence to instructions is a win for RAG. When I write in the prompt "answer only based on the context, do not use general knowledge" — Opus 4.7 truly does it. 4.6 sometimes "added its own," which is critically unacceptable in RAG.
The new tokenizer immediately hit the budget. In my very first test run after migration, the cost of processing the same set of requests increased by approximately 23% — precisely because of the new tokenization. I had to immediately review the system prompt, remove duplication, and enable prompt caching.
My current working compromise: Llama 3.3 70B as the default for most clients, Opus 4.7 as a "premium" option for niches where the cost of error is high (lawyers, finance, medicine). The choice is configured in a single line of code — the client can switch themselves.
For my Mac M1, I continue to use Ollama with local models for development (more details on the choice between 8GB and 16GB RAM in a separate article). Opus 4.7 via API is only for production or complex testing.
❓ FAQ: Claude Opus 4.7
When was Claude Opus 4.7 released?
April 16, 2026. This is the fourth Opus update in six months (4.1, 4.5, 4.6, 4.7); Anthropic maintains a release cadence of approximately once every 2 months.
How does Opus 4.7 differ from Opus 4.6?
The main differences are in coding and agentic workflows. SWE-bench Pro improved from 53.4% to 64.3%, CursorBench from 58% to 70%. Vision has been improved (3× higher resolution), as well as tool use and memory. There are breaking changes: a new tokenizer, only adaptive extended thinking, and sampling parameters no longer work.
How much does Claude Opus 4.7 cost via API?
$5 per 1M input tokens and $25 per 1M output tokens — the same price as Opus 4.6. However, the actual cost per request has increased due to the new tokenizer (1.0–1.35× more tokens for the same text) and the model's tendency to think longer at high effort levels.
Will Claude Opus 4.7 replace GPT-5.4 or Gemini 3.1 Pro?
For coding tasks, yes, Opus 4.7 leads. On GPQA Diamond (graphical reasoning), the models are practically identical — the difference is within the margin of error. On web research (BrowseComp), Opus 4.7 loses. The choice depends on the specific use case.
Can Claude Opus 4.7 be used for RAG?
Yes, and it works well — especially where model honesty ("I don't know" instead of hallucination) and prompt injection resistance are critical. However, for most RAG tasks, cheaper open-source models like Llama 3.3 70B are sufficient. Opus 4.7 is justified in niches with a high cost of error.
Is Claude Opus 4.7 the best Anthropic model?
Among publicly available models, yes. However, Anthropic also has Mythos Preview, which outperforms Opus 4.7 on all benchmarks. Mythos is only available to partners within Project Glasswing (Apple, Google, Microsoft) and will not be generally available in the near future.
What is the context window for Claude Opus 4.7?
1 million tokens for input (no additional charge for long context), up to 128K tokens for output.
What should I do if my code uses temperature or extended thinking budgets?
These parameters are no longer supported in Opus 4.7 — calls will return a 400 error. You need to switch to adaptive thinking and control behavior through prompts. If you are not ready for migration, you can use Opus 4.6 for now, but it will be deprecated.
Is it worth migrating to Opus 4.7 immediately?
If your main task is coding or agentic workflows with minimal supervision, then yes, it's worth it. If you are building a simple chatbot or classifier, Sonnet or even Haiku might be sufficient. Before migrating, be sure to test your existing prompts — literal adherence to instructions can break behavior.