
Is ChatGPT an LLM or RAG?, “Why do I need RAG if the model is already smart?”, “Is RAG a new model?” — these questions arise every day. The confusion exists because RAG utilizes an LLM internally, yet they represent fundamentally different architectural layers. One is the brain; the other is the access to knowledge.
Spoiler: LLM and RAG are not competitors, but different layers of a single system. An LLM generates responses based on what it learned during training. RAG supplements the LLM with relevant external data at the moment of the query. Understanding this difference determines whether your AI project will be reliable — or whether it will confidently present hallucinations as facts.
In Brief
- Key Insight 1: LLM is a generative model with "frozen" knowledge. It knows nothing after its training cutoff date and has no access to your private data.
- Key Insight 2: RAG is not a separate model, but an architectural pattern that provides the LLM with a "library" of relevant external data before generating a response.
- Key Insight 3: For 80–90% of business tasks involving internal or frequently updated data, RAG is the safest and most effective approach.
- What you will get: A clear understanding of the difference between LLM and RAG, a comparative table, a decision tree for choosing the right approach, and an analysis of common pitfalls.
Table of Contents
Section 1. What is an LLM — and Where Are Its Limits
LLM is a Generative Model
A Large Language Model (LLM) is a neural network trained on massive volumes of text that generates responses based on patterns learned during training. An LLM does not "search" for information — it "recalls" what it has learned. After the training cutoff date, the model knows nothing new and has no access to your internal data.
An LLM is like a well-read expert who has read a million books but has never seen a single one of your internal documents and hasn't read yesterday's news.
Imagine a consultant who graduated from the best university, read millions of texts, and is capable of brilliantly articulating thoughts. But there’s a catch: his knowledge stopped at the moment of "graduation" (the training date), he has never seen your internal documents, and he cannot verify facts in real-time. When he doesn't know the answer, he won't admit it; instead, he will confidently make it up. This is an LLM.
Examples of LLMs: GPT-4o (OpenAI), Claude (Anthropic), Gemini (Google DeepMind), Llama (Meta). They all operate on the same principle: they receive a prompt, "recall" the most probable sequence of words based on training data, and generate a response.
What LLMs Do Well
LLMs are powerful tools for tasks where the answer depends on general knowledge and linguistic skills: text generation (articles, emails, copywriting), summarization (compressing large texts), translation, sentiment analysis, reasoning (logic chains, mathematics), and code generation/explanation.
Where LLMs Systematically Fail
Hallucinations. LLMs confidently generate information that looks plausible but is entirely fabricated. According to the Vectara Hallucination Leaderboard (2025), even the best models have hallucination rates ranging from 0.7% (Gemini 2.0 Flash) to 29.9% (Falcon-7B). In legal tasks, the situation is significantly worse: Stanford (2025) found that LLMs hallucinate at least 75% of the time when answering about court rulings, generating over 120 fictional cases with realistic names and detailed but completely fictitious arguments. For more on the nature and dangers of AI hallucinations and practical ways to reduce them, see the article "AI Hallucinations: What They Are, Why They Are Dangerous, and How to Avoid Them" (Webscraft, 2025).
Outdated Knowledge. LLM knowledge is "frozen" at the time of training. The model is unaware of changes in legislation, new products, updated prices, or recent events. For businesses where data currency is critical (finance, law, medicine, tech support), this is a systemic limitation.
Lack of Access to Your Data. An LLM cannot see your internal documents, knowledge bases, CRM, or wikis. When you ask ChatGPT about a company's internal policy, it will provide a generic answer or invent something plausible.
No Citations or Audit. An LLM cannot specify where information was sourced from. For regulated industries (finance, law, medicine) where traceability and an audit trail are required, this is a critical shortcoming.
As AWS aptly describes: An LLM can be compared to an "over-enthusiastic new employee who refuses to stay informed about current events but always answers with absolute confidence."
Conclusion: I believe that an LLM is a powerful generative tool with broad capabilities for generalization and information synthesis. At the same time, it is limited by its training date, a tendency to hallucinate, and a lack of direct access to your data. These architectural limitations are exactly what the RAG approach is designed to compensate for by adding a retrieval layer and working with actual context.
Section 2. What is RAG — and How It Relates to LLM
RAG is an Architectural Pattern, Not a Model
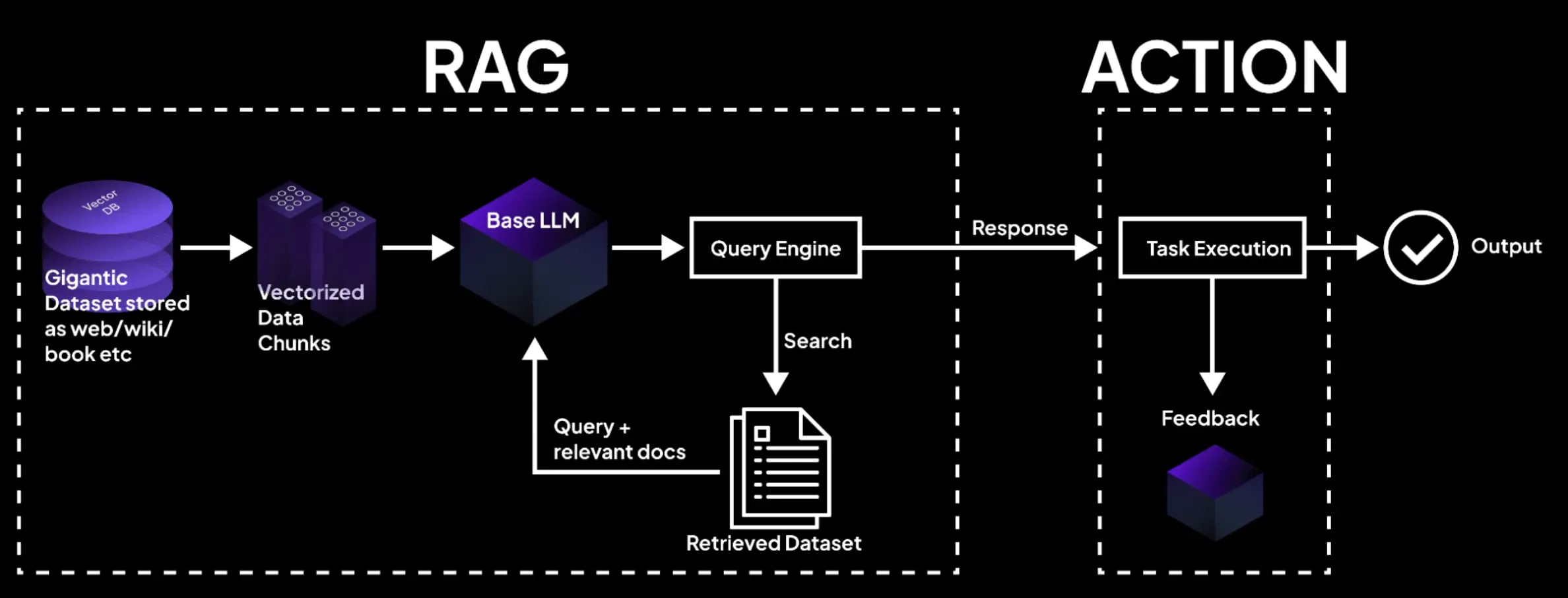
Retrieval-Augmented Generation (RAG) is an approach where the system first finds relevant information from external sources (knowledge bases, documents, databases) and then passes it to the LLM as context to generate a response. RAG does not replace the LLM — it supplements it with up-to-date data at the moment of every query.
If the LLM is the brain, then RAG is the library the brain consults before every answer.
Returning to the consultant analogy: RAG is when that same expert, before every answer, enters your corporate library, finds the most relevant documents, and formulates a response based on them. He still uses his linguistic skills and reasoning (that’s the LLM), but now his answers rely on specific, up-to-date sources.
The term RAG first appeared in Meta AI research (2020), where researchers proposed combining a retrieval component with a generative model to improve the quality of answers for knowledge-intensive tasks. Since then, RAG has evolved from a simple pattern to a full-fledged production architecture with dozens of components.
How RAG Works — In Simple Terms
The process consists of three steps. First — retrieval: when a query arrives, the system searches for the most relevant fragments in your knowledge base (documents, wikis, databases). Second — augmentation: the found fragments are added to the prompt as context. Third — generation: the LLM generates a response relying on the provided context, not just its "frozen" knowledge.
Key point: The LLM remains the "brain" of the system. RAG does not change the model — it changes the information the model receives before generation. This means RAG works with any LLM: GPT-4o, Claude, Gemini, Llama — without the need for retraining.
What This Provides in Practice
Relevance. When prices, regulations, or documentation change, you update the knowledge base, not the model. As Wikipedia notes: "Instead of retraining the model, it is sufficient to update the external knowledge base with fresh information."
Reduction of Hallucinations. According to AllAboutAI (2025), RAG is the most effective technique for reducing hallucinations, cutting them by 71% when correctly implemented. A clinical study by the National Cancer Center Japan (2025) confirmed: RAG with reliable sources reduced GPT-4's hallucination rate from ~40% (without RAG) to 0% (with RAG on verified medical data).
Citations and Audit. RAG allows every statement to be linked to a specific document and page. This is critical for compliance, legal, and financial applications.
Privacy. Your data does not go into the model for training — it is processed locally and provided as context. This allows for working with sensitive data (medical, financial, legal) without the risk of leakage.
Conclusion: RAG is not a replacement for LLM, but an extension of it. The LLM is responsible for language skills and reasoning. RAG is responsible for ensuring those skills rely on current, relevant, and verified data.
Core Distinctions — Comparative Table
LLM and RAG differ across 7 key criteria
LLM and RAG represent different layers of AI system architecture. An LLM is a generative model with fixed knowledge. RAG is a pattern that supplements the LLM with external data in real-time. They are not competitors — they work in tandem.
| Criterion |
LLM (Standalone) |
RAG (LLM + Retrieval) |
| Knowledge Source |
Training data (frozen at training cutoff) |
External documents + knowledge bases (updated in real-time) |
| Information Currency |
Becomes outdated without retraining (months, millions of $) |
Updated without retraining — just update the index |
| Hallucinations |
High risk (0.7–30% depending on model and domain) |
Significantly reduced (up to 71% reduction if properly implemented) |
| Citations/Sources |
Impossible — the model doesn't know where it got the info |
Yes — every claim is linked to a specific document |
| Knowledge Update Cost |
Model retraining (weeks, GPU-hours, $10,000–$1,000,000+) |
Index update (minutes to hours, minimal cost) |
| Data Privacy |
Data may end up in the training set |
Data remains local, provided only as context |
| Latency (Response Speed) |
Fast (~0.5–2s) |
Slightly slower (~1–3s due to the retrieval step) |
| Access to Your Data |
No — the model only sees what is in the prompt |
Yes — the system searches your specific knowledge base |
Conclusion: LLM and RAG are not alternatives, but complements. RAG always includes an LLM as a component. The question is not "LLM or RAG," but "Is a standalone LLM sufficient for my task?"
When "Pure" LLM is Sufficient
LLM without RAG is suitable for tasks where the answer does not depend on your specific or fresh data
If the task requires general knowledge, linguistic skills, or reasoning — and does not rely on specific internal documents or real-time data — an LLM works effectively without additional retrieval.
Not every task requires RAG. In many scenarios, a "pure" LLM is the optimal and sufficient tool. These are tasks where response quality is determined by the model's linguistic capabilities and general knowledge rather than access to specific sources.
Specific Scenarios Where LLM Suffices
Text Generation and Copywriting: Writing articles, emails, marketing copy, social media posts. The model works with its internal language patterns — external data is not required.
Public Information Summarization: Compressing articles, reports, or books. The LLM processes the text provided in the prompt — retrieval adds no value here.
Translation: The language model already possesses knowledge of grammar and vocabulary — external documents are usually unnecessary for translation.
Reasoning and Analysis: Logic puzzles, mathematics, code generation and explanation, brainstorming ideas. The model utilizes its inherent reasoning capabilities.
Creative Tasks: Scripts, poems, game narratives where factual accuracy is not critical.
Section Conclusion: If the response does not depend on your specific, confidential, or frequently updated data — a standalone LLM is perfectly sufficient. Do not overcomplicate the architecture needlessly.
When RAG is Required
RAG is required when the response depends on specific, up-to-date, or confidential data
For 80–90% of enterprise tasks where AI interacts with internal documents, dynamic data, or requires citations, RAG is the standard and recommended approach. It ensures relevance, traceability, and data control without model retraining.
RAG becomes essential when the task extends beyond the model's general knowledge. Below are five key scenarios where RAG is the right choice.
Scenario 1: Internal Company Data
Documentation, knowledge bases, regulations, wikis, CRM data — an LLM sees none of this. RAG allows an AI assistant to answer queries based on your specific documents: "What is our return policy?", "What do the regulations say about vacations?", "What are the steps to escalate a ticket?"
Scenario 2: Frequently Updated Data
Price lists, legal norms, technical documentation, financial reports — anything that changes more often than a model can be retrained. With RAG, you update the index in minutes, rather than retraining the model over weeks.
Scenario 3: Citations and Auditing Required
In compliance, legal, and financial scenarios, every response must reference a specific source. RAG provides traceability: "This answer is based on document X, page Y, section Z." Without this, an AI system will not pass an audit review.
Scenario 4: Privacy and Confidentiality
Medical, financial, and legal data should not be included in a model's training set. RAG allows you to store data locally and provide it as context — the model sees the data only at the moment of the request and does not store it.
Scenario 5: Large Document Corpora
Hundreds of thousands of documents cannot fit into the context window of any model. RAG solves this through retrieval: instead of "feeding" everything, the system finds the 5–10 most relevant fragments and provides only those.
Section Conclusion: If even one of these five scenarios describes your task — you need RAG. Not because the LLM is "bad," but because an LLM without access to your data cannot answer accurately.
What About Fine-tuning and Long-context?
Fine-tuning and long-context supplement RAG, they do not replace it
Fine-tuning adapts the model's style and terminology but does not solve the currency problem. Long-context allows "feeding" a lot of text without retrieval, but it is expensive and slow on large corpora. In 2026, hybrid approaches (RAG + long-context, RAG + fine-tuning) dominate the landscape.
Besides RAG, there are two other approaches for working with specific data. Both have their niches, but neither replaces RAG in the majority of enterprise scenarios.
Fine-tuning: Teaching the Model to "Speak Your Language"
Fine-tuning is additional training of the model on your dataset. The model adopts the style, terminology, and response format of your domain (medical language, legal style, corporate tone of voice). However, there is a fundamental limitation: knowledge is "frozen" at the moment of training. If the data changes, you must retrain. This involves weeks of work and significant GPU costs.
Fine-tuning is suitable when you need to adapt format and style for relatively static knowledge. It is not suitable for dynamic data.
Long-context: "Feeding" Everything into the Prompt
Modern models support massive context windows: Gemini (Google) — up to 2M+ tokens, Claude (Anthropic) — ~1M. Theoretically, you can "upload" hundreds of documents directly into the prompt. In practice, this is expensive (cost per query scales with tokens), slow (2–45+ seconds vs 1–3 seconds for RAG), and inaccurate at scale: research shows a 25–45% degradation in recall for information located in the middle of the context (the "Lost in the Middle" effect).
Long-context wins in narrow scenarios: a small static corpus (up to 50 documents) where global understanding of the entire context is required simultaneously.
Hybrids — The 2026 Trend
In practice, these approaches are combined. RAG + long-context: RAG finds 20–50 relevant documents, which are then fed into a long-context LLM for deep analysis. RAFT (Microsoft, 2024): a hybrid of RAG + fine-tuning where the model is trained to work effectively with retrieved context and ignore noise. The trend in 2026 is to use each approach where it is most efficient. For a deeper understanding of how large language models work in a business context, their strengths and weaknesses, and how to choose the right approach (LLM, RAG, or hybrid), see the article "LLM Overview: How to Use Large Language Models in Business and Content."
Conclusion: Fine-tuning adapts the style; long-context works for small static corpora. For dynamic, large, or confidential data, RAG remains the standard — with fine-tuning and long-context complementing it as upper layers.
Common Pitfalls When Choosing Between LLM and RAG
The Five Most Frequent Errors
Most mistakes stem from a fundamental misunderstanding of the difference between a model (LLM) and an architecture (RAG). These misconceptions lead to costly deployments that either hallucinate or require constant, expensive retraining.
Mistake 1: "We connected ChatGPT — why do we need RAG?"
ChatGPT (or any other standalone LLM) has no access to your internal data. It will answer based on general knowledge or simply hallucinate. Connecting an LLM is only the first step. For a system to work with your proprietary data, you need a retrieval layer — which is RAG.
Mistake 2: "RAG will replace our LLM"
RAG cannot function without an LLM — it is an augmentation, not a replacement. RAG is responsible for finding relevant information; the LLM is responsible for articulating a response based on what was found. One without the other is useless in this context.
Mistake 3: "It's enough to just paste the document into the prompt"
This works for one or two short documents. For a corpus of thousands, the prompt simply cannot hold everything. Even long-context models with 1M+ tokens face accuracy issues on large volumes and cost significantly more. RAG solves this elegantly: instead of "everything in the prompt," it performs a surgical search for only what is relevant.
Mistake 4: "Fine-tuning will solve the currency problem"
Fine-tuning "freezes" knowledge at the moment of training. If prices change, regulations update, or a new product is launched, you must retrain. RAG updates knowledge in minutes by refreshing the index. Fine-tuning is for style adaptation, not for solving the data freshness problem.
Mistake 5: "RAG completely eliminates hallucinations"
RAG significantly reduces hallucinations (up to 71% when properly implemented), but it does not eliminate them entirely. If the retrieval step finds irrelevant documents or the model ignores the provided context, hallucinations can still occur. Stanford (2025) showed that even enterprise RAG systems in the legal sector hallucinate 17–33% of the time. Production-grade RAG requires rigorous evaluation and observability — it is not a "set it and forget it" solution.
Section Conclusion: Most errors arise from a simplified view of "LLM = AI, RAG = a different AI." In reality, they are different layers of the same system, each solving a specific architectural challenge.
Choosing the Right Approach — Decision Tree
Five Questions to Determine Your Path
The choice between "pure" LLM, RAG, fine-tuning, or long-context depends on the nature of your data: its specificity, update frequency, need for citations, and corpus size. The five questions below provide a clear roadmap.
Instead of abstract recommendations, here is a concrete selection algorithm:
Question 1: Does the answer depend on your specific, proprietary data?
No → Standalone LLM is sufficient. Use ChatGPT, Claude, or Gemini directly.
Question 2: Does the data update more often than once a quarter?
No → Fine-tuning might be suitable (if style/terminology adaptation is the goal).
Yes → RAG (index updates instead of retraining).
Question 3: Are citations, auditing, or compliance required?
Yes → RAG (traceability down to the specific document).
Question 4: Is the corpus small and static (fewer than 50 documents)?
Yes → Long-context might be simpler (provide the entire context in the prompt).
No → RAG (retrieval scales to millions of documents).
Question 5: Is high privacy required (medical, financial, or legal data)?
Yes → RAG with local embeddings and ACL (Access Control List) filters.
For most enterprise tasks, the answer to Question 1 is "yes," leading straight to RAG. This doesn't mean other approaches are obsolete — often, RAG serves as the foundation, while fine-tuning and long-context supplement it for specific sub-tasks.
Conclusion: If your data is specific, dynamic, or confidential — start with RAG. It is the safest and most flexible starting point for the majority of business scenarios.
Frequently Asked Questions (FAQ)
Is RAG a separate model?
No. RAG is an architectural pattern (an approach) that combines a retrieval component (knowledge base search) with a generative model (LLM). RAG always uses an LLM internally — it’s an extension, not a replacement.
Can I use RAG with any LLM?
Yes. RAG works with any generative model: GPT-4o, Claude, Gemini, Llama, Mistral, and others. RAG doesn't change the model itself; it adds external context before the generation happens.
Does RAG completely eliminate hallucinations?
No, but it reduces them significantly. According to AllAboutAI (2025), RAG cuts hallucinations by 71% when correctly implemented. However, if the retrieval finds irrelevant docs or the model ignores the context, errors remain. Production RAG requires continuous monitoring.
How much does it cost to implement RAG?
A basic PoC (Proof of Concept) can be assembled in 1–2 days using open-source tools (LlamaIndex, LangChain, Qdrant) almost for free. Production-grade systems require 2–12 weeks of engineering. TCO for 1M requests/month with semantic caching is approximately $500–$2,000 (compared to $5,000–$50,000+ for a long-context approach at the same volume).
Will long-context (1M+ tokens) replace RAG?
No. Long-context is great for small, static datasets but is more expensive, slower (2–45+ seconds vs 1–3 seconds), and less accurate at scale (recall degradation of 25–45% for "middle" info). In 2026, long-context is becoming the upper layer in hybrid architectures where RAG acts as a noise filter.
What’s better for a small company — RAG or fine-tuning?
In most cases, RAG. It doesn't require GPU training costs, works with any LLM via API, and updates in minutes. Fine-tuning is only justified when you need deep domain adaptation of style with static knowledge.
Conclusions
LLM and RAG are not competitors; they are different layers of the same system. The LLM is the brain that generates responses. RAG is the access to knowledge that provides that brain with relevant, verified information before every answer.
If your task is text generation, summarization, translation, or reasoning based on general knowledge — a standalone LLM is sufficient. If your task depends on specific, updated, or confidential data, or requires citations — RAG is the standard recommended approach.
Three key takeaways: RAG is an architecture, not a model, that supplements any LLM with external data. RAG reduces hallucinations by 71% but requires evaluation for production. For 80–90% of enterprise tasks with internal data, RAG is the most reliable and flexible choice.
If RAG is your choice, the next step is understanding production architecture: building a system that isn't just functional, but reliable, fast, and measurable. Full guide: RAG in 2026: From PoC to Production.
