
„Ist ChatGPT ein LLM oder RAG?“, „Wozu brauche ich RAG, wenn das Modell doch so intelligent ist?“, „Ist RAG ein neues Modell?“ – diese Fragen hört man täglich. Die Verwirrung entsteht, weil RAG intern LLM verwendet, aber es sich um grundlegend unterschiedliche Architekturebenen handelt. Das eine ist das Gehirn, das andere der Zugang zu Wissen.
Spoiler: LLM und RAG sind keine Konkurrenten, sondern verschiedene Schichten eines Systems. LLM generiert Antworten basierend auf dem, was es während des Trainings gelernt hat. RAG ergänzt LLM im Moment der Anfrage mit aktuellen externen Daten. Das Verständnis dieses Unterschieds entscheidet darüber, ob Ihr KI-Projekt zuverlässig sein wird – oder ob es selbstbewusst Fiktionen als Fakten ausgeben wird.
Kurz gesagt
- Kernbotschaft 1: LLM ist ein generatives Modell mit „eingefrorenem“ Wissen. Es weiß nichts nach dem Trainingsdatum und hat keinen Zugriff auf Ihre Daten.
- Kernbotschaft 2: RAG ist kein eigenständiges Modell, sondern ein Architekturmuster, das dem LLM vor der Antwortgenerierung eine „Bibliothek“ mit aktuellen externen Daten hinzufügt.
- Kernbotschaft 3: Für 80–90 % der Geschäftsaufgaben mit internen oder aktualisierbaren Daten ist RAG der sicherste und effektivste Ansatz.
- Sie erhalten: ein klares Verständnis des Unterschieds zwischen LLM und RAG, eine Vergleichstabelle, einen Entscheidungsbaum zur Auswahl des Ansatzes und eine Analyse typischer Fehler.
Inhalt
Abschnitt 1. Was ist LLM – und wo liegen seine Grenzen
LLM – das ist ein generatives Modell
Ein Large Language Model (LLM) ist ein neuronales Netzwerk, das auf riesigen Textmengen trainiert wurde und Antworten auf der Grundlage von Mustern generiert, die es während des Trainings gelernt hat. Ein LLM sucht keine Informationen – es „erinnert“ sich an das, was es gelernt hat. Nach dem Trainingsdatum weiß das Modell nichts Neues und hat keinen Zugriff auf Ihre internen Daten.
Ein LLM ist ein belesener Experte, der eine Million Bücher gelesen hat, aber keines Ihrer internen Dokumente gesehen und die gestrigen Nachrichten nicht gelesen hat.
Stellen Sie sich einen Berater vor, der die beste Universität abgeschlossen, Millionen von Texten gelesen hat und brillante Gedanken formulieren kann. Aber es gibt einen Haken: Sein Wissen ist zum Zeitpunkt seines „Abschlusses“ (Trainingsdatum) stehen geblieben, er hat nie Ihre internen Dokumente gesehen und kann Fakten nicht in Echtzeit überprüfen. Wenn er die Antwort nicht weiß, gibt er es nicht zu, sondern erfindet selbstbewusst etwas. Das ist ein LLM.
Beispiele für LLMs: GPT-4o (OpenAI), Claude (Anthropic), Gemini (Google DeepMind), Llama (Meta). Sie alle arbeiten nach dem gleichen Prinzip: Sie erhalten eine Anfrage, „erinnern“ sich an die wahrscheinlichste Wortfolge basierend auf den Trainingsdaten und generieren eine Antwort.
Was LLM gut kann
LLM ist ein leistungsstarkes Werkzeug für Aufgaben, bei denen die Antwort von allgemeinem Wissen und Sprachkenntnissen abhängt: Textgenerierung (Artikel, E-Mails, Copywriting), Summarization (Zusammenfassung großer Texte), Übersetzung, Stimmungsanalyse, Reasoning (logische Ketten, Mathematik), Codegenerierung und -erklärung.
Wo LLM systematisch versagt
Halluzinationen. LLMs generieren selbstbewusst Informationen, die plausibel erscheinen, aber erfunden sind. Laut dem Vectara Hallucination Leaderboard (2025) weisen selbst die besten Modelle eine Halluzinationsrate von 0,7 % (Gemini 2.0 Flash) bis 29,9 % (Falcon-7B) auf. Bei juristischen Aufgaben ist die Situation deutlich schlimmer: Stanford (2025) stellte fest, dass LLMs bei Antworten zu Gerichtsentscheidungen mindestens 75 % der Zeit halluzinieren und über 120 erfundene Fälle mit realistischen Namen und detaillierter, aber völlig fiktiver Argumentation generieren. Mehr über die Natur und Gefahren von KI-Halluzinationen sowie praktische Wege zu deren Reduzierung finden Sie im Artikel „KI-Halluzinationen: Was sie sind, warum sie gefährlich sind und wie man sie vermeidet“ (Webscraft, 2025).
Veraltetes Wissen. Das Wissen von LLMs ist zum Zeitpunkt des Trainings „eingefroren“. Das Modell weiß nichts über Gesetzesänderungen, neue Produkte, aktualisierte Preise oder aktuelle Ereignisse. Für Unternehmen, bei denen die Aktualität der Daten entscheidend ist (Finanzen, Recht, Medizin, technischer Support), ist dies eine systemische Einschränkung.
Kein Zugriff auf Ihre Daten. Ein LLM sieht Ihre internen Dokumente, Wissensdatenbanken, CRMs, Wikis nicht. Wenn Sie ChatGPT nach der internen Unternehmenspolitik fragen, wird es eine allgemeine Antwort geben oder etwas Plausibles erfinden.
Keine Zitate und kein Audit. Ein LLM kann nicht angeben, woher die Informationen stammen. Für regulierte Branchen (Finanzen, Recht, Medizin), in denen Rückverfolgbarkeit und Audit-Trail erforderlich sind, ist dies ein kritischer Mangel.
Wie AWS treffend beschreibt: Ein LLM lässt sich mit einem „übertrieben enthusiastischen neuen Mitarbeiter vergleichen, der sich weigert, aktuelle Ereignisse zu verfolgen, aber immer mit absoluter Sicherheit antwortet“.
Fazit: Ich bin der Meinung, dass LLM ein leistungsstarkes generatives Werkzeug mit weitreichenden Möglichkeiten zur Verallgemeinerung und Synthese von Informationen ist. Gleichzeitig ist es durch das Trainingsdatum, die Neigung zu Halluzinationen und das Fehlen eines direkten Zugriffs auf Ihre Daten begrenzt. Genau diese architektonischen Einschränkungen soll der RAG-Ansatz kompensieren, indem er eine Retrieval-Schicht und die Arbeit mit aktuellem Kontext hinzufügt.
Was ist RAG – und wie hängt es mit LLM zusammen
RAG ist ein Architekturmuster, kein Modell
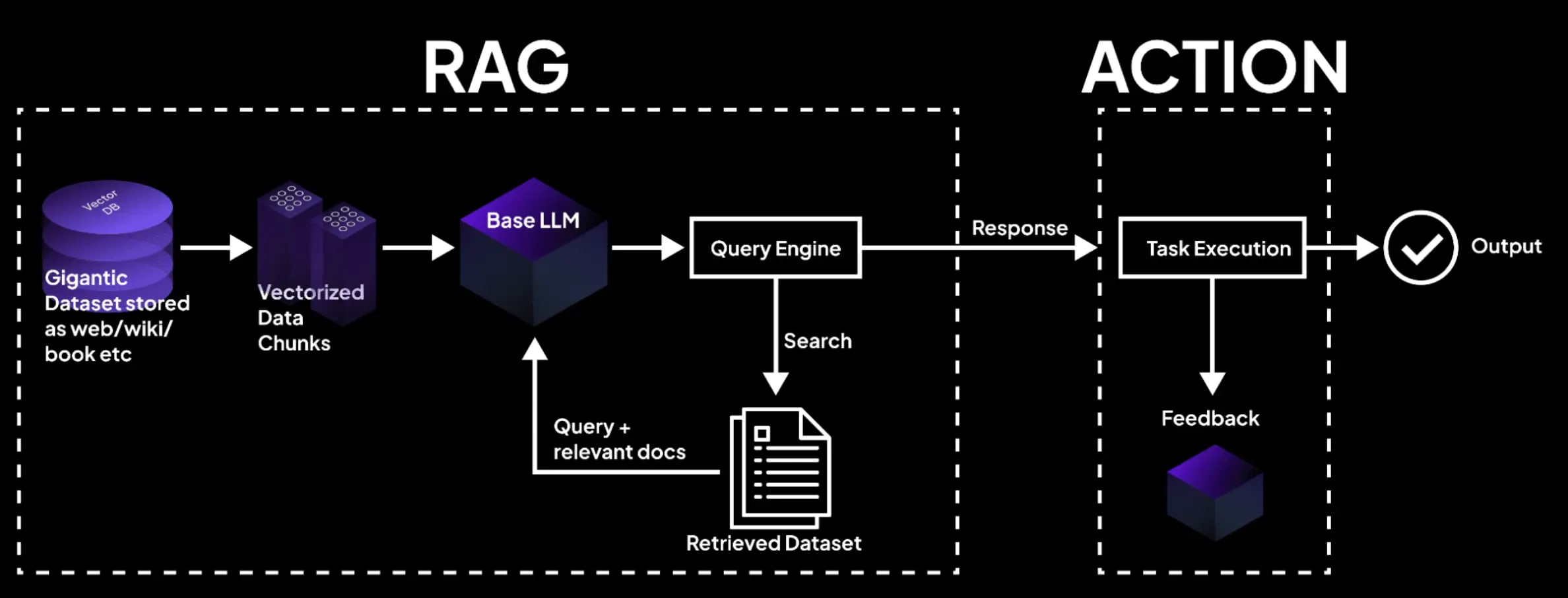
Retrieval-Augmented Generation (RAG) ist ein Ansatz, bei dem ein System zunächst relevante Informationen aus externen Quellen (Wissensdatenbanken, Dokumente, Datenbanken) findet und diese dann als Kontext an das LLM zur Antwortgenerierung übergibt. RAG ersetzt LLM nicht – es ergänzt es im Moment jeder Anfrage mit aktuellen Daten.
Wenn LLM das Gehirn ist, dann ist RAG die Bibliothek, in die das Gehirn vor jeder Antwort schaut.
Kehren wir zur Analogie mit dem Berater zurück. RAG ist, wenn derselbe Experte vor jeder Antwort in Ihre Unternehmensbibliothek geht, die relevantesten Dokumente findet und darauf basierend eine Antwort formuliert. Er nutzt immer noch seine Sprachkenntnisse und sein Reasoning (das ist das LLM), aber jetzt stützen sich seine Antworten auf konkrete, aktuelle Quellen.
Der Begriff RAG tauchte erstmals in einer Studie von Meta AI (2020) auf, in der Forscher vorschlugen, eine Retrieval-Komponente mit einem generativen Modell zu kombinieren, um die Qualität von Antworten bei wissensintensiven Aufgaben zu verbessern. Seitdem hat sich RAG von einem einfachen Muster zu einer vollwertigen Produktionsarchitektur mit Dutzenden von Komponenten entwickelt.
Wie RAG funktioniert – in einfachen Worten
Der Prozess besteht aus drei Schritten. Der erste ist Retrieval (Abruf): Wenn eine Anfrage eingeht, sucht das System die relevantesten Fragmente in Ihrer Wissensdatenbank (Dokumente, Wikis, Datenbanken). Der zweite ist Augmentation (Erweiterung): Die gefundenen Fragmente werden als Kontext zur Anfrage hinzugefügt. Der dritte ist Generation (Generierung): Das LLM generiert eine Antwort, die sich auf den bereitgestellten Kontext stützt und nicht nur auf sein „eingefrorenes“ Wissen.
Der entscheidende Punkt: Das LLM bleibt das „Gehirn“ des Systems. RAG ändert das Modell nicht – es ändert die Informationen, die das Modell vor der Generierung erhält. Das bedeutet, dass RAG mit jedem LLM funktioniert: GPT-4o, Claude, Gemini, Llama – ohne dass ein erneutes Training erforderlich ist.
Was das in der Praxis bringt
Aktualität. Wenn sich Preise, Vorschriften oder Dokumentationen ändern, aktualisieren Sie die Wissensdatenbank, anstatt das Modell neu zu trainieren. Wie Wikipedia feststellt: „Anstatt das Modell neu zu trainieren, genügt es, die externe Wissensdatenbank mit frischen Informationen zu aktualisieren.“
Reduzierung von Halluzinationen. Laut AllAboutAI (2025) ist RAG die effektivste Technik zur Reduzierung von Halluzinationen und senkt diese bei korrekter Implementierung um 71 %. Eine klinische Studie des National Cancer Center Japan (2025) bestätigte: RAG mit zuverlässigen Quellen senkte die Halluzinationsrate von GPT-4 von ~40 % (ohne RAG) auf 0 % (mit RAG auf überprüften medizinischen Daten).
Zitierung und Audit. RAG ermöglicht es, jede Aussage mit einem bestimmten Dokument und einer Seite zu verknüpfen. Dies ist entscheidend für Compliance, juristische und finanzielle Anwendungen.
Vertraulichkeit. Ihre Daten gelangen nicht zum Training in das Modell – sie werden lokal verarbeitet und als Kontext bereitgestellt. Dies ermöglicht die Arbeit mit sensiblen Daten (medizinische, finanzielle, juristische) ohne das Risiko eines Datenlecks.
Fazit: RAG ist kein Ersatz für LLM, sondern eine Erweiterung davon. LLM ist für Sprachkenntnisse und Reasoning zuständig. RAG stellt sicher, dass diese Fähigkeiten auf aktuellen, relevanten und überprüften Daten basieren.
Wesentliche Unterschiede – eine Vergleichstabelle
LLM und RAG unterscheiden sich in 7 Schlüsselkriterien
LLM und RAG sind unterschiedliche Architekturebenen eines KI-Systems. LLM ist ein generatives Modell mit festem Wissen. RAG ist ein Muster, das LLM in Echtzeit mit externen Daten ergänzt. Sie konkurrieren nicht – sie arbeiten zusammen.
| Kriterium | LLM (ohne RAG) | RAG (LLM + Retrieval) |
|---|
| Wissensquelle | Trainingsdaten (eingefroren zum Trainingsdatum) | Externe Dokumente + Wissensdatenbanken (in Echtzeit aktualisiert) |
| Aktualität der Informationen | Veraltet ohne erneutes Training (Monate, Millionen $) | Wird ohne erneutes Training aktualisiert – Indexaktualisierung genügt |
| Halluzinationen | Hohes Risiko (0,7–30 % je nach Modell und Domäne) | Deutlich reduziert (bis zu 71 % Reduzierung bei korrekter Implementierung) |
| Zitierung von Quellen | Unmöglich – das Modell weiß nicht, woher es die Informationen hat | Ja – jede Aussage wird einem bestimmten Dokument zugeordnet |
| Kosten für Wissensaktualisierung | Neues Training des Modells (Wochen, GPU-Stunden, 10.000–1.000.000 $+) | Indexaktualisierung (Minuten–Stunden, minimale Kosten) |
| Datenvertraulichkeit | Daten können in den Trainingsdatensatz gelangen | Daten bleiben lokal, werden als Kontext bereitgestellt |
| Latenz (Antwortgeschwindigkeit) | Schnell (~0,5–2 s) | Etwas langsamer (~1–3 s aufgrund des Suchschritts) |
| Zugriff auf Ihre Daten | Nein – das Modell sieht nur das, was im Prompt steht | Ja – das System sucht in Ihrer Wissensdatenbank |
Fazit: LLM und RAG sind keine Alternativen, sondern Ergänzungen. RAG beinhaltet immer LLM als Komponente. Die Frage ist nicht „LLM oder RAG“, sondern „reicht LLM ohne RAG für meine Aufgabe aus“.
Wann ein „reines“ LLM ausreicht
LLM ohne RAG eignet sich für Aufgaben, bei denen die Antwort nicht von Ihren spezifischen oder aktuellen Daten abhängt
Wenn die Aufgabe allgemeines Wissen, Sprachkenntnisse oder Reasoning erfordert – und nicht von spezifischen internen Dokumenten oder aktuellen Daten abhängt – arbeitet LLM ohne zusätzliches Retrieval effektiv.
Nicht jede Aufgabe erfordert RAG. In vielen Szenarien ist ein „reines“ LLM das optimale und ausreichende Werkzeug. Dies sind Aufgaben, bei denen die Qualität der Antwort durch die Sprachkenntnisse und das allgemeine Wissen des Modells bestimmt wird und nicht durch den Zugriff auf spezifische Quellen.
Konkrete Szenarien, in denen LLM ausreicht
Textgenerierung und Copywriting: Schreiben von Artikeln, E-Mails, Marketingtexten, Social-Media-Posts. Das Modell arbeitet mit seinen eigenen Sprachmustern – externe Daten sind nicht erforderlich.
Zusammenfassung öffentlicher Informationen: Komprimierung von Artikeln, Berichten, Büchern. LLM arbeitet mit dem Text, der im Prompt bereitgestellt wird – Retrieval fügt keinen Wert hinzu.
Übersetzung: Ein Sprachmodell verfügt bereits über Kenntnisse der Grammatik und des Wortschatzes – für die Übersetzung sind externe Dokumente in der Regel nicht erforderlich.
Reasoning und Analyse: Logische Aufgaben, Mathematik, Codegenerierung und -erklärung, Brainstorming von Ideen. Das Modell nutzt seine Reasoning-Fähigkeiten.
Kreative Aufgaben: Drehbücher, Gedichte, Spielnarrative, bei denen die Genauigkeit der Fakten nicht entscheidend ist.
Fazit des Abschnitts: Wenn die Antwort nicht von Ihren spezifischen, vertraulichen oder aktualisierbaren Daten abhängt, ist ein LLM ohne RAG völlig ausreichend. Komplizieren Sie die Architektur nicht unnötig.
Wann RAG benötigt wird
RAG wird benötigt, wenn die Antwort von spezifischen, aktuellen oder vertraulichen Daten abhängt
Für 80–90 % der Unternehmensaufgaben, bei denen KI mit internen Dokumenten, aktualisierbaren Daten arbeitet oder Zitate erfordert, ist RAG der Standard- und empfohlene Ansatz. Er gewährleistet Aktualität, Rückverfolgbarkeit und Datenkontrolle ohne erneutes Training des Modells.
RAG wird notwendig, wenn die Aufgabe über das allgemeine Wissen des Modells hinausgeht. Im Folgenden sind fünf Schlüsselszenarien aufgeführt, in denen RAG die richtige Wahl ist.
Szenario 1: Interne Unternehmensdaten
Dokumentationen, Wissensdatenbanken, Vorschriften, Wikis, CRM-Daten – ein LLM sieht nichts davon. RAG ermöglicht es dem KI-Assistenten, Anfragen basierend auf Ihren spezifischen Dokumenten zu beantworten: „Wie lautet unsere Rückgaberichtlinie?“, „Was besagt die Vorschrift über Urlaube?“, „Welche Schritte sind zur Eskalation eines Tickets erforderlich?“.
Szenario 2: Häufig aktualisierte Daten
Preislisten, rechtliche Normen, technische Dokumentationen, Finanzberichte – alles, was sich häufiger ändert, als das Modell neu trainiert werden kann. Mit RAG aktualisieren Sie den Index in Minuten, anstatt das Modell in Wochen neu zu trainieren.
Szenario 3: Zitate und Audit erforderlich
In Compliance-, Rechts- und Finanzszenarien muss jede Antwort auf eine bestimmte Quelle verweisen. RAG gewährleistet Rückverfolgbarkeit: „Diese Antwort basiert auf Dokument X, Seite Y, Abschnitt Z“. Ohne dies würde das KI-System keine Audit-Überprüfung bestehen.
Szenario 4: Vertraulichkeit
Medizinische, finanzielle, juristische Daten dürfen nicht in den Trainingsdatensatz des Modells gelangen. RAG ermöglicht es, Daten lokal zu speichern und als Kontext bereitzustellen – das Modell sieht die Daten nur im Moment der Anfrage und speichert sie nicht.
Szenario 5: Große Dokumentenkorpora
Hunderttausende von Dokumenten passen nicht in das Kontextfenster eines einzigen Modells. RAG löst dies durch Retrieval: Anstatt alles „einzuspeisen“, findet das System 5–10 der relevantesten Fragmente und stellt genau diese bereit.
Fazit des Abschnitts: Wenn mindestens eines dieser fünf Szenarien Ihre Aufgabe beschreibt, benötigen Sie RAG. Nicht weil LLM schlecht ist, sondern weil LLM ohne Zugriff auf Ihre Daten keine genaue Antwort geben kann.
Was ist mit Fine-Tuning und Long-Context?
Fine-Tuning und Long-Context ergänzen RAG, ersetzen es aber nicht
Fine-Tuning passt den Stil und die Terminologie des Modells an, löst aber nicht das Problem der Aktualität. Long-Context ermöglicht es, viel Text ohne Suche „einzuspeisen“, ist aber bei großen Korpora teuer und langsam. Im Jahr 2026 dominieren hybride Ansätze (RAG + Long-Context, RAG + Fine-Tuning).
Neben RAG gibt es noch zwei weitere Ansätze für die Arbeit von LLM mit spezifischen Daten. Beide haben ihre Nischen, aber keiner ersetzt RAG in den meisten Unternehmensszenarien.
Fine-Tuning: Das Modell „Ihre Sprache sprechen“ lehren
Fine-Tuning ist ein zusätzliches Training des Modells auf Ihrem Datensatz. Das Modell lernt den Stil, die Terminologie und das Antwortformat Ihrer Domäne (medizinische Sprache, juristischer Stil, Corporate Tone of Voice). Es gibt jedoch eine grundlegende Einschränkung: Das Wissen wird zum Zeitpunkt des Trainings „eingefroren“. Wenn sich die Daten ändern, muss neu trainiert werden. Dies bedeutet Wochen an Arbeit und erhebliche GPU-Kosten.
Fine-Tuning eignet sich, wenn Format und Stil bei relativ statischem Wissen angepasst werden müssen. Es ist nicht für dynamische Daten geeignet.
Long-Context: Alles in den Kontext „einspeisen“
Moderne Modelle unterstützen große Kontextfenster: Gemini (Google) – bis zu 2M+ Token, Claude (Anthropic) – ~1M. Theoretisch könnte man Hunderte von Dokumenten direkt in den Prompt „laden“. In der Praxis ist dies jedoch teuer (die Kosten pro Anfrage steigen proportional zur Anzahl der Token), langsam (2–45+ Sekunden gegenüber 1–3 Sekunden bei RAG) und bei großen Mengen ungenau: Studien zeigen eine Verschlechterung des Recalls um 25–45 % für Informationen in der Mitte des Kontexts (der „Lost in the Middle“-Effekt).
Long-Context ist in einem engen Szenario vorteilhaft: ein kleiner statischer Korpus (bis zu 50 Dokumente), bei dem ein globales Verständnis des gesamten Kontexts gleichzeitig erforderlich ist.
Hybride – der Trend des Jahres 2026
In der Praxis werden Ansätze kombiniert. RAG + Long-Context: RAG findet 20–50 relevante Dokumente, die dann einem Long-Context LLM zur tiefgehenden Analyse zugeführt werden. RAFT (Microsoft, 2024) – ein Hybrid aus RAG + Fine-Tuning: Das Modell lernt, effektiv mit dem abgerufenen Kontext zu arbeiten und Rauschen zu ignorieren. Dies ist der Trend des Jahres 2026 – jeden Ansatz dort einzusetzen, wo er am effektivsten ist. Für ein tieferes Verständnis, wie große Sprachmodelle im Geschäftskontext funktionieren, ihre Stärken und Schwächen sowie wie man den richtigen Ansatz (LLM, RAG oder Hybrid) wählt, siehe den Artikel „LLM: Überblick und wie man große Sprachmodelle in Unternehmen und Inhalten einsetzt“.
Fazit: Fine-Tuning passt den Stil an, Long-Context funktioniert für kleine statische Korpora. Für dynamische, große oder vertrauliche Daten bleibt RAG der Standard – und Fine-Tuning sowie Long-Context ergänzen es als obere Schichten.
Typische Fehler bei der Wahl zwischen LLM und RAG
Fünf häufigste Fehler
Die meisten Fehler entstehen durch ein Missverständnis des Unterschieds zwischen Modell (LLM) und Architektur (RAG). Diese Fehler führen zu teuren Implementierungen, die entweder halluzinieren oder ein ständiges erneutes Training erfordern.
Fehler 1: „Wir haben ChatGPT angeschlossen – wozu brauchen wir RAG?“
ChatGPT (oder jedes andere LLM) hat keinen Zugriff auf Ihre internen Daten. Es wird auf der Grundlage allgemeinen Wissens antworten oder halluzinieren. Ein LLM anzuschließen ist nur der erste Schritt. Damit das System mit Ihren Daten arbeiten kann, ist eine Retrieval-Schicht, also RAG, erforderlich.
Fehler 2: „RAG wird unser LLM ersetzen“
RAG funktioniert nicht ohne LLM – es ist eine Erweiterung, kein Ersatz. RAG ist für die Suche nach relevanten Informationen zuständig. LLM ist für die Formulierung der Antwort auf der Grundlage des Gefundenen zuständig. Das eine ohne das andere ist sinnlos.
Fehler 3: „Es reicht aus, das Dokument in den Prompt einzufügen“
Das funktioniert für 1–2 kurze Dokumente. Für einen Korpus von Tausenden von Dokumenten passt nicht alles in den Prompt. Selbst Long-Context-Modelle mit 1M+ Token haben Probleme mit der Genauigkeit bei großen Mengen und sind um ein Vielfaches teurer. RAG löst dies elegant: statt „alles in den Prompt“ – nur die Suche nach dem Relevanten.
Fehler 4: „Fine-Tuning wird das Problem der Aktualität lösen“
Fine-Tuning „friert“ das Wissen zum Zeitpunkt des Trainings ein. Wenn sich Preise ändern, Vorschriften aktualisiert werden oder ein neues Produkt erscheint, ist ein erneutes Training erforderlich. RAG aktualisiert das Wissen in Minuten durch eine Indexaktualisierung. Fine-Tuning ist eine Stilanpassung, keine Lösung für das Problem der Aktualität.
Fehler 5: „RAG eliminiert Halluzinationen vollständig“
RAG reduziert Halluzinationen erheblich (bis zu 71 % bei korrekter Implementierung), eliminiert sie aber nicht vollständig. Wenn das Retrieval jedoch irrelevante Dokumente findet oder das Modell den Kontext ignoriert, sind Halluzinationen immer noch möglich. Stanford (2025) zeigte, dass selbst Enterprise-RAG-Systeme im juristischen Bereich 17–33 % der Zeit halluzinieren. Produktions-RAG erfordert Evaluation und Observability – es ist kein „einmal einrichten und vergessen“.
Fazit des Abschnitts: Die meisten Fehler entstehen durch ein vereinfachtes Verständnis: „LLM = KI, RAG = andere KI“. Tatsächlich sind dies verschiedene Schichten eines Systems, von denen jede ihre eigene Aufgabe löst.
Wie man den Ansatz wählt – ein Entscheidungsbaum
Fünf Fragen zur Bestimmung des richtigen Ansatzes
Die Wahl zwischen einem „reinen“ LLM, RAG, Fine-Tuning oder Long-Context hängt von der Art Ihrer Daten ab: Sind sie spezifisch, werden sie aktualisiert, sind Zitate erforderlich, wie groß ist der Korpus? Die fünf Fragen unten geben eine klare Route vor.
Statt abstrakter Empfehlungen – ein konkreter Auswahlalgorithmus:
Frage 1: Hängt die Antwort von Ihren spezifischen Daten ab?
Nein → LLM ist ausreichend. Verwenden Sie ChatGPT, Claude oder Gemini direkt.
Frage 2: Werden die Daten häufiger als einmal pro Quartal aktualisiert?
Nein → Fine-Tuning könnte passen (wenn Stil-/Terminologieanpassung erforderlich ist).
Ja → RAG (Indexaktualisierung statt erneutes Training).
Frage 3: Sind Zitate, Audit oder Compliance erforderlich?
Ja → RAG (Rückverfolgbarkeit bis zum Dokument).
Frage 4: Ist der Korpus klein und statisch (weniger als 50 Dokumente)?
Ja → Long-Context könnte einfacher sein (der gesamte Kontext im Prompt).
Nein → RAG (Retrieval skaliert auf Millionen von Dokumenten).
Frage 5: Ist Vertraulichkeit erforderlich (medizinische, finanzielle, juristische Daten)?
Ja → RAG mit lokalen Embeddings und ACL-Filtern.
Für die meisten Unternehmensaufgaben lautet die Antwort auf Frage 1 „Ja“, und der Weg führt zu RAG. Das bedeutet nicht, dass andere Ansätze unnötig sind – oft ist RAG die Grundlage, und Fine-Tuning sowie Long-Context ergänzen es für spezifische Unteraufgaben.
Fazit: Wenn Ihre Daten spezifisch, aktualisiert oder vertraulich sind, beginnen Sie mit RAG. Dies ist die sicherste und flexibelste Ausgangswahl für die meisten Geschäftsszenarien.
Häufig gestellte Fragen (FAQ)
Ist RAG ein eigenständiges Modell?
Nein. RAG ist ein Architekturmuster (Ansatz), das eine Retrieval-Komponente (Suche in einer Wissensdatenbank) mit einem generativen Modell (LLM) kombiniert. RAG verwendet immer ein LLM intern – es ist kein Ersatz für das Modell, sondern eine Erweiterung davon.
Kann RAG mit jedem LLM verwendet werden?
Ja. RAG funktioniert mit jedem generativen Modell: GPT-4o, Claude, Gemini, Llama, Mistral und anderen. RAG ändert das Modell nicht – es fügt ihm vor der Generierung externen Kontext hinzu.
Eliminiert RAG Halluzinationen vollständig?
Nein, aber es reduziert sie erheblich. Laut AllAboutAI (2025) reduziert RAG Halluzinationen bei korrekter Implementierung um 71 %. Wenn das Retrieval jedoch irrelevante Dokumente findet oder das Modell den Kontext ignoriert, bleiben Fehler bestehen. Produktions-RAG erfordert Evaluation und Monitoring.
Wie viel kostet die Implementierung von RAG?
Ein grundlegender PoC (Prototyp) kann in 1–2 Tagen mit Open-Source-Tools (LlamaIndex, LangChain, Qdrant) praktisch kostenlos erstellt werden. Ein Produktionsniveau erfordert 2–12 Wochen Arbeit, abhängig von Komplexität und Umfang. Die TCO für 1 Million Anfragen/Monat mit semantischem Caching beträgt schätzungsweise 500–2000 US-Dollar (im Vergleich zu 5000–50000+ US-Dollar für den Long-Context-Ansatz bei ähnlichem Volumen).
Wird Long-Context (1M+ Token) RAG ersetzen?
Nein. Long-Context eignet sich für kleine statische Korpora, ist aber teurer, langsamer (2–45+ Sekunden gegenüber 1–3 Sekunden) und bei großen Mengen weniger genau (Recall-Degradation von 25–45 % für Informationen in der Mitte des Kontexts). Im Jahr 2026 wird Long-Context zu einer oberen Schicht in einer hybriden Architektur, in der RAG die Rolle eines Rauschfilters übernimmt.
Was ist besser für ein kleines Unternehmen – RAG oder Fine-Tuning?
In den meisten Fällen – RAG. Es erfordert keine GPU-Kosten für das Training, funktioniert mit jedem LLM über API und wird in Minuten aktualisiert. Fine-Tuning ist nur dann gerechtfertigt, wenn eine enge domänenspezifische Stilanpassung bei statischem Wissen erforderlich ist.
Wird ein Entwickler für die Einrichtung von RAG benötigt?
Für einen grundlegenden PoC reicht ein Entwickler mit Python- und API-Erfahrung aus. Für ein Produktionsniveau ist ein Team von 1–3 Ingenieuren mit Verständnis für Retrieval, Evaluation und DevOps erforderlich.
Fazit
LLM und RAG sind keine Konkurrenten, sondern verschiedene Ebenen eines Systems. LLM ist das Gehirn, das Antworten generiert. RAG ist der Zugang zu Wissen, der diesem Gehirn vor jeder Antwort aktuelle, überprüfte Informationen liefert.
Wenn Ihre Aufgabe Textgenerierung, Zusammenfassung, Übersetzung oder Reasoning auf der Grundlage allgemeinen Wissens ist, ist LLM ohne RAG ausreichend. Wenn Ihre Aufgabe von spezifischen, aktualisierbaren, vertraulichen Daten abhängt oder Zitate erfordert, ist RAG der Standard- und empfohlene Ansatz.
Drei Schlüsselthesen zum Merken. RAG ist kein eigenständiges Modell, sondern eine Architektur, die jedes LLM mit externen Daten ergänzt. RAG reduziert Halluzinationen um 71 %, erfordert aber eine Evaluation für das Produktionsniveau. Für 80–90 % der Unternehmensaufgaben mit internen Daten ist RAG die sicherste und flexibelste Ausgangswahl.
Wenn RAG Ihre Wahl ist, besteht der nächste Schritt darin, die Produktionsarchitektur zu verstehen: wie man ein System aufbaut, das nicht nur funktioniert, sondern zuverlässig, schnell und mit messbarer Qualität arbeitet. Der vollständige Leitfaden – RAG im Jahr 2026: Von PoC zur Produktion.
