Gemma 4 26B MoE: підводні камені і коли це реально виграє
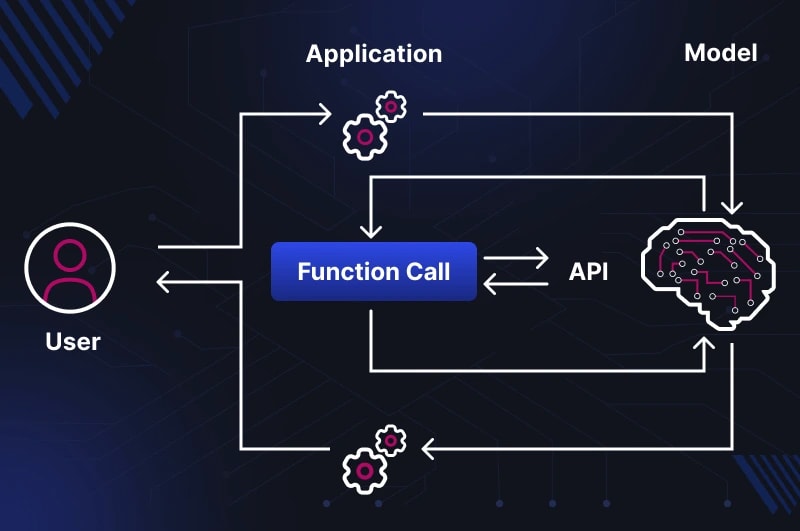
Коротко: Gemma 4 26B MoE рекламують як "якість 26B за ціною 4B". Це правда щодо швидкості інференсу — але не щодо пам'яті. Завантажити потрібно всі 18 GB. На Mac з 24 GB — свопінг і 2 токени/сек. Комфортно працює на 32+ GB. Читай перш ніж завантажувати. Що таке MoE і чому 26B...