Anthropic has made a quiet but principled move: the new model
Claude Opus 4.8 is not just an update to benchmarks.
The company is shifting its focus from "which model is smarter" to "which model can be
trusted more." Let's break down what has really changed and why it's important for
developers.
What is Claude Opus 4.8
Claude Opus 4.8 is Anthropic's flagship public model,
released on May 28, 2026. It is a direct
continuation of Opus 4.7 and belongs to the same price category:
$5 per 1 million input tokens and $25 per 1 million output.
Opus 4.8 focuses on three areas:
Coding and software engineering — including understanding large repositories and multi-step tasks;
Reasoning and handling complex tasks — long contexts, legal and financial documents, data analysis;
Reliability and honesty — a new point of differentiation from competitors.
According to Anthropic's official announcement,
the model is available via API as claude-opus-4-8 and is already
running on all company platforms: claude.ai, Claude Code, API.
It's worth noting: TechCrunch
draws attention to the unusually short update cycle — only
41 days after Opus 4.7. The reasons are the cool reception
of the previous version and pressure from competitors: OpenAI updated Codex,
Google released Gemini 3.5 Flash.
Main Changes in Opus 4.8
Better honesty: a model that admits its mistakes
This is Anthropic's main editorial bet in this release — and the most interesting
analytical signal for the market.
According to Anthropic,
Opus 4.8 is approximately four times less likely than
the previous model to overlook errors in its own code.
The model more often admits uncertainty, "invents confident
answers" less often, and is less prone to hallucinations in agentic tasks.
The Anthropic Alignment team has noted: Opus 4.8 has reached new
heights in prosocial characteristics — supporting user autonomy, acting in the user's best interest. The level of deceptive behavior
and facilitation of abuse is significantly lower than in Opus 4.7, and
comparable to Claude Mythos Preview — a model that Anthropic itself called "the most aligned we've ever trained."
Early testers confirm: according to a representative from
Bridgewater, the biggest difference in Opus 4.8 is its
"tendency to proactively flag issues in input and output data of analysis, which other models regularly missed and left users to discover themselves."
Source: anthropic.com.
I believe the AI industry is gradually moving
from the paradigm of "maximally intelligent AI" to "maximally reliable AI."
For enterprise users, legal, and financial workflows, this may be
more important than raw benchmark scores. Anthropic is clearly trying to make this
its point of differentiation against OpenAI and Google.
Dynamic Workflows: Claude as an Orchestration Engine
Perhaps the most significant functional novelty of the release, and the one that has garnered the most attention from
TechCrunch
and
The New Stack.
Dynamic Workflows (available in research preview)
allow Claude Code to launch hundreds of parallel sub-agents within a single session. The workflow is as follows:
The user sets a large-scale task.
Claude plans the work and distributes it among sub-agents.
Sub-agents execute tasks in parallel.
Claude verifies the results before returning them to the user.
Anthropic provides a specific example: Claude Code with Opus 4.8 can now perform codebase migration on hundreds of thousands of lines of code — from start to a ready merge — using the existing test suite as a quality criterion.
Source: anthropic.com.
The feature is available for Enterprise, Team, and Max plans.
In simple terms: in my opinion, Claude is no longer just a chatbot that answers questions. It is becoming closer to an autonomous orchestration engine that can independently manage complex multi-stage processes.
This is a fundamental shift in how AI integrates into the development workflow.
Also, an important technical update for developers:
the Messages API now accepts system entries within the message array. This allows instructions to be updated during an active agent session without interrupting the prompt cache or missing updates through a user turn.
Source: anthropic.com.
Coding Improvements
Coding remains the main battleground between Anthropic, OpenAI, and Google. According to
Anthropic,
Opus 4.8 has improved across all key coding metrics:
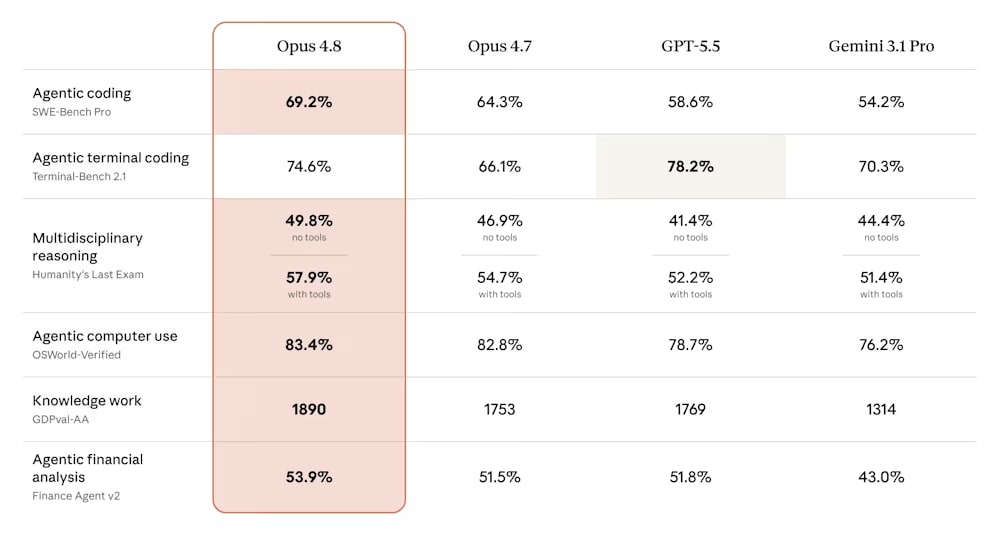
Agentic coding — 69.2% compared to 64.3% for Opus 4.7;
Agentic computer usage — 83.4% compared to GPT-5.5 (78.7%) and Gemini 3.1 Pro (76.2%);
Repo-level reasoning — better understanding of large codebases and inter-component dependencies;
Multi-step tasks — ability to maintain context over long, multi-step tasks.
Testers from Cursor (an AI-powered IDE) note:
Opus 4.8 surpasses all previous versions at any level of effort, and tool invocation has become noticeably more efficient — fewer steps for the same result.
Exception: agentic coding in the terminal — here, Opus 4.8
currently lags behind GPT-5.5 by 3.6%.
Effort Control: reasoning budget at your fingertips
The new effort control feature is an interesting practical tool, especially for the developer audience.
According to Anthropic,
Opus 4.8 operates at high effort by default — Anthropic considers this the optimal balance of quality and experience.
But now the user has a choice:
Extra / xhigh (in Claude Code) — the model thinks deeper and more often, uses more tokens, and delivers better results on complex tasks;
Max — maximum reasoning depth for the most complex asynchronous workflows;
Essentially, this is adjustable reasoning depth — the ability to explicitly manage the trade-off between speed, cost, and quality.
For large teams working with Claude Code on the Enterprise plan, this offers direct budget savings without compromising quality where high quality is not critical.
Good news for the budget: Fast Mode (2.5× faster than standard) is now three times cheaper than in previous models.
Prices: $10 per 1 million input tokens and $50 per 1 million output tokens.
What is Claude Mythos and why is everyone talking about it
In parallel with the release of Opus 4.8, Anthropic made another important announcement: work on the next class of models — significantly more powerful than Opus — is actively ongoing.
Claude Mythos is a separate tier of Anthropic models that surpasses Opus in intelligence and capabilities. Currently, only a small group of partners has access to it as part of
Project Glasswing — primarily for cybersecurity tasks.
The reason for limited access is not technical, but security-related.
According to
TechCrunch,
an early preview in April 2026 revealed cybersecurity risks that require separate protective mechanisms before a broad release.
Anthropic sent a clear signal: progress in developing these mechanisms is rapid, and the company expects to provide access to the Mythos class of models to all customers "in the coming weeks."
Source: anthropic.com.
Important: Mythos is not "Claude 5." It is a new category where Anthropic is gradually forming a separate tier for extremely powerful tasks with enhanced security requirements. Opus
remains the main public flagship.
Why This Matters for Developers
If you're a developer using AI in your daily work, Opus 4.8
brings several practical changes—not revolutionary, but noticeable.
IDE Agents and Autonomous Coding
Thanks to Dynamic Workflows and improved repo-level reasoning, Claude
can now independently handle project-wide tasks: refactoring, library migration, and identifying inter-module dependencies. For large Java/Spring projects, this means you can delegate real work to Claude, not just receive suggestions.
AI Pair Programming
Improved honesty is a practical advantage in pair programming.
The model is less likely to confidently offer incorrect solutions. It
more often signals: "I'm not sure about this part—it's best to double-check." For developers, this reduces debugging time for AI-generated code.
Effort Control in Dev Workflow
The ability to explicitly control reasoning depth allows for building
more efficient pipelines: using high/max effort for
critical architectural decisions and low effort for routine tasks
(generating boilerplate, formatting, simple documentation queries).
DevOps and Automated Workflows
The update to the Messages API—system entries within the message array—directly simplifies building agent pipelines: you can update instructions, permissions, and token budgets right during an active session without interrupting the agent's work.
Large Codebases and Long-Context Tasks
Based on testing results (
anthropic.com),
Opus 4.8 better maintains context in long sessions and is less likely to "lose" important details during multi-stage tasks—this is noticeable when working with large monorepositories.
Conclusion
I think Claude Opus 4.8 isn't a revolution. And Anthropic itself practically admits this.
But behind this update lies an important editorial choice by the company:
instead of racing for benchmark scores, Anthropic is betting on
reliability, honesty, and autonomous workflows.
This is a response to the real needs of the enterprise market—AI that can
be trusted with long, complex, critical tasks.
For developers, the practical outcome is as follows:
the model is less likely to "confidently err"—less time spent on verification;
Dynamic Workflows enable a truly autonomous level of task execution;
Effort Control provides control over the quality/cost/speed trade-off;
Fast Mode has become significantly cheaper.
Mythos is on the horizon. But even now, Opus 4.8 is Anthropic's most mature
public tool for those building serious AI systems.