In brief: On June 9, 2026, Anthropic released Claude Fable 5 — the first public model of the Mythos class, previously restricted due to cybersecurity risks. The same technological foundation as Mythos 5, but with active safety classifiers. Price: $10 / $50 per million tokens. Benchmarks: 80.3% SWE-Bench Pro, #1 on FrontierCode Diamond.
Claude Fable 5: why Anthropic released a model considered too dangerous for months
In April 2026, Anthropic introduced Claude Mythos and immediately restricted access to it: only for selected organizations involved in critical infrastructure protection. On June 9, the same company announced Claude Fable 5 — a public version of the model based on the same technological foundation. What has changed in two months, and why now?
What is Claude Fable 5
Claude Fable 5 is the first publicly available model of Anthropic's new Mythos class. The name is not accidental: fable from Latin is fabula, "that which is told" — the same root as the Greek mythos. This is not a marketing game, but a signal: Fable 5 and Mythos 5 are built on the exact same model weights. The difference is not in the architecture, but in the safety layer.
Anthropic positions the Mythos class as a level above Opus. The first model of this class, Claude Mythos Preview, was released in April 2026 through the closed Project Glasswing — and remained unavailable to the general public until June 9.
Why was the Mythos model hidden from the public
The main reason is cybersecurity. Back in April, Anthropic described Mythos's capabilities as being able to "extremely effectively detect and exploit vulnerabilities in software." It was this characteristic that impressed both Wall Street and US government structures — and it was precisely because of this that the company did not plan to release the model to the public.
The access scheme unfolded in stages:
April 2026 — Mythos Preview available only to a select few partners within Project Glasswing, exclusively for critical infrastructure protection.
End of May 2026 — the program expanded to several hundred organizations in 15 countries, but again, only for defensive tasks.
June 9, 2026 — release of Claude Fable 5 to the general public.
Concurrently, the company publicly warned: frontier models are becoming so powerful that in the coming months they may reach the level of recursive self-improvement (RSI) — that is, autonomous improvement of their own code without human intervention. At first glance, this contradicts the decision to release Fable 5 now. But Anthropic's logic is different: not to wait until the model becomes even more powerful, but to release it with a verified defense layer — while control is still possible.
Fable 5 vs Mythos 5: what's the difference
The key point is: it's the same model. The difference is exclusively in the configuration of the safety classifiers. Fable 5 has an active defense layer; Mythos 5 is the same architecture but with partially removed restrictions for verified partners of Project Glasswing.
The table below shows ExploitBench: an industry benchmark that measures the model's ability to find and exploit real-world software vulnerabilities. This specific metric was the main reason for the limited release of Mythos.
Will be opened for trusted partners in future versions
ExploitBench
~0% (blocked by classifier)
78.0%
Price
$10 / $50 per million tokens
$10 / $50 per million tokens
Anthropic confirmed: on benchmarks not related to blocked domains, the difference in results between Fable 5 and Mythos 5 is 1–3 percentage points — within statistical noise.
Benchmarks: The Numbers and What They Mean
Below are key benchmarks from Anthropic's official announcement and independent tests as of June 9–10, 2026. The ★ symbol indicates that the result belongs to Mythos 5; Fable 5 drops to the level of Opus 4.8 in these categories due to fallback.
SWE-Bench Pro is a more reliable benchmark than SWE-Bench Verified. OpenAI has acknowledged data contamination in the Verified version; the Pro version tests real-world tasks on closed repositories.
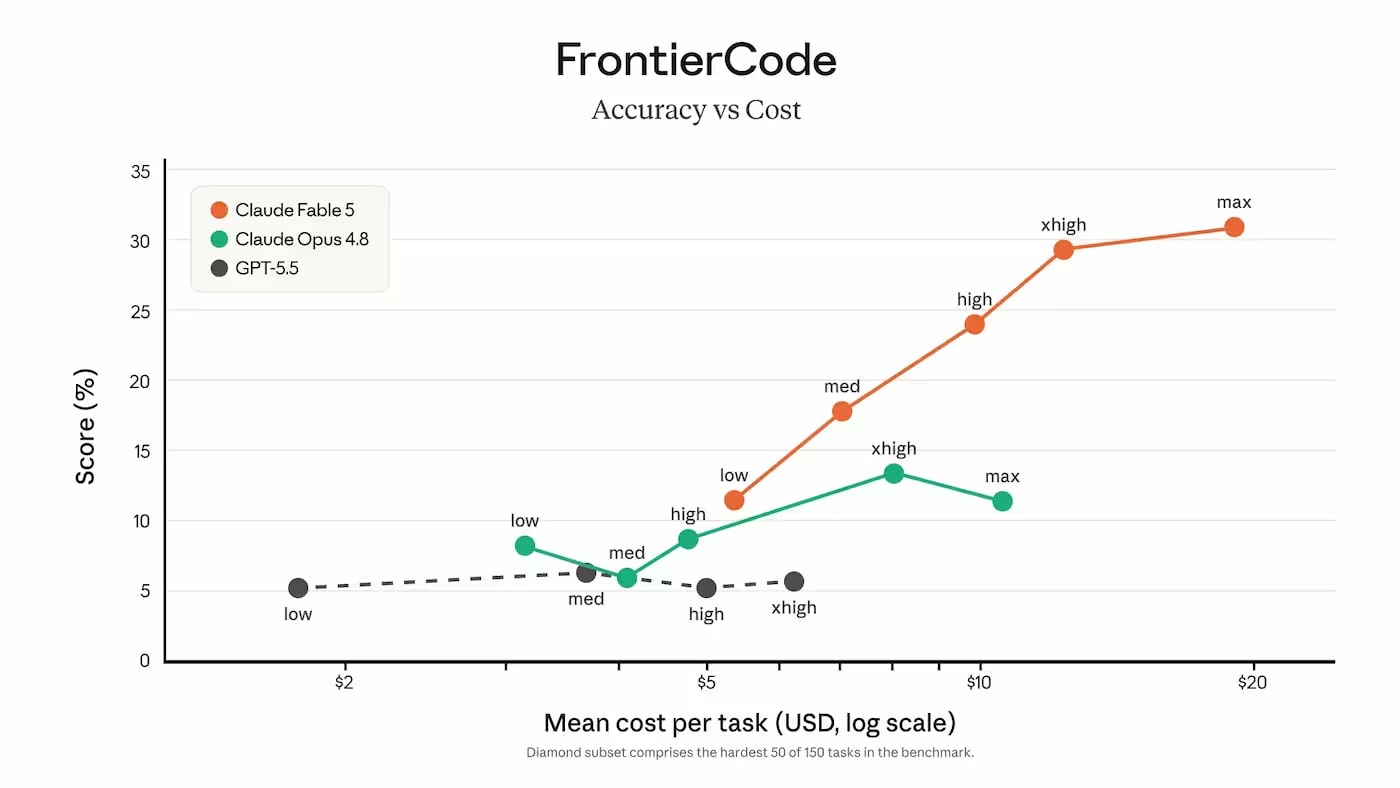
FrontierCode is the most representative for production code. 29.3% compared to 13.4% for Opus 4.8 means Fable 5 solves more than twice as many complex engineering tasks.
ExploitBench is a mirror of the architectural decision. Mythos 5 scores 78%, Fable 5 scores close to zero. This is the essence of the distinction between the two models.
Anthropic has implemented a classifier layer that intercepts requests in four categories and redirects them to Claude Opus 4.8:
Cybersecurity — vulnerability searching and exploitation, offensive software development
Biology — synthesis of dangerous substances, pathogen design
Chemistry — synthesis of dual-use substances
Model Distillation — attempts to replicate internal weights through outputs
Technically: when the classifier triggers, the API returns an HTTP 200 with stop_reason: "refusal" and a stop_details.category field with the value "cyber", "bio", "reasoning_extraction", or null. If no output was generated, the request is not charged.
According to Anthropic, the classifiers trigger in less than 5% of sessions on average. The company acknowledges the existence of false positives and promises to reduce them with new version releases.
Before the release, Anthropic conducted an external bug bounty: over 1,000 hours of testing did not reveal any universal jailbreaks.
For Which Tasks Does Anthropic Recommend Fable 5
Scenario
Why Fable 5 is Suitable
Programming and Code Review
80.3% SWE-Bench Pro, #1 FrontierCode — best for long agent tasks and migrations
Data Analysis and Finance
#1 on Hebbia Finance Benchmark for senior level: tables, charts, root-cause analysis
Agent Tasks (Claude Code)
Autonomous operation for weeks without human intervention; in the Stripe test, it compressed 2 months of team work into one day
Computer Vision
State-of-the-art: recreating a web application from a screenshot, precise reading of scientific graphs
Scientific Research
Hypothesis generation in molecular biology (via Mythos 5); Fable 5 for literature and genomics analysis without restrictions
Legal Work
In a blind review, lawyers rated Fable 5's redlines as equal to or better than the previous model in 100% of cases
For routine tasks where SWE-Bench Pro level complexity is not required, Claude Opus 4.8 remains a more rational choice: twice as cheap for the same tokens.
How to access Claude Fable 5
Access Method
Details
Claude Pro / Max / Team / Enterprise (subscriptions)
Free until June 22, 2026; from June 23 — usage credits required; standard plans to be reinstated later
Claude API
Model ID: claude-fable-5; available now
Amazon Bedrock
Available from release day
Google Cloud / Microsoft Foundry
Available from release day
GitHub Copilot
Available; requires up to 30 days of prompt+output retention for classifiers to work (disabled by default in Copilot admin)
Claude Code (CLI)
Available from release day
Practical tip: if the model hasn't appeared in your list yet, I'd recommend simply refreshing the page or logging out and back in. In my case, Claude Fable 5 appeared after reloading the interface, without any additional settings.
How much does Claude Fable 5 cost
Parameter
Fable 5 / Mythos 5
Opus 4.8
Mythos Preview (pre-release)
Input (per million tokens)
$10
$5
>$22 (estimated)
Output (per million tokens)
$50
$25
>$110 (estimated)
Batch input
$5
$2.5
—
Batch output
$25
$12.5
—
Prompt caching
-90%
-90%
—
Context window
1M input / 128K output
200K / 32K
—
If you're using LLMs for programming, it's worth looking not only at the price per token but also at the conditional cost of getting the correct result. In such evaluations, Fable 5 might appear more cost-effective than Opus 4.8 due to a higher success rate, which reduces the number of retries and overall costs for solving a task.
What the Fable 5 release means for the AI market
In my opinion, the main issue here is not technical. If just this spring a Mythos-class model was considered too risky for broad access, what exactly has changed in a few months? Anthropic's answer is not that the model has become less powerful, but that the company has begun to trust its own safety layer. According to Anthropic, an external bug bounty program could not bypass these mechanisms even after over 1,000 hours of testing and attack attempts. In fact, we are seeing the first major precedent where a frontier model is released to the public with a clearly documented system of restrictions and automatic fallback to a less risky model for specific categories of requests.
After analyzing the Fable 5 release, I've noticed several trends that could be important for companies implementing AI solutions or evaluating the strategies of major AI vendors.
Safety mechanisms instead of bans are becoming the new standard. OpenAI, Anthropic, and Google are gradually moving away from the "release or not release" approach. Instead, they are building multi-layered control systems that allow access to powerful models while restricting specific risky scenarios. Fable 5 is currently one of the most transparent examples of this approach.
The gap between public and private versions of models is becoming structural. Mythos 5 and Fable 5 demonstrate a new model of AI distribution. Formally, it's one technological platform, but with different access levels and different capabilities in specific domains. It's highly likely that we'll see a similar scheme in future generations of frontier models.
Commercialization and security are no longer contradictory. For Anthropic, the Fable 5 release is not just a technological achievement but also a business signal. The company is demonstrating that it can bring the most powerful models to market without completely abandoning its safety principles. For investors, this is an important indicator of platform maturity.
Mythos-level capabilities will gradually become the new norm. In my opinion, within the next 6-12 months, capabilities that are currently associated with the Mythos class will begin to be perceived as standard for flagship models. A similar process already occurred after the emergence of GPT-4: what initially seemed like a breakthrough became a basic market expectation a year later.
If we view the Fable 5 launch not as another model release, but as a signal to the entire industry, the main conclusion for me is this: major AI companies are no longer trying to hide their most powerful models from the general public. Instead, they are investing in control mechanisms that allow them to open access to frontier models without losing control over the most risky usage scenarios.
FAQ: Frequently asked questions about Claude Fable 5
Can Claude Fable 5 be run locally?
No. Fable 5 is a cloud-based model, accessible exclusively through the Anthropic API, Claude.ai, and partner platforms (Amazon Bedrock, Google Cloud, Microsoft Foundry). Anthropic does not publish model weights and does not plan to do so. If you need a local model, that's a different class of solutions.
Will Fable 5 replace Claude Opus 4.8?
No, at least not immediately. Opus 4.8 remains in the lineup and costs half as much. Moreover, Fable 5 automatically switches to Opus 4.8 for requests in blocked categories. For most routine tasks, Opus 4.8 is a more rational choice. Fable 5 justifies its price on long agent tasks and complex code, where the success rate is fundamentally different.
How does Fable 5 differ from Mythos 5?
Not at all at the architecture level — it's the same model with the same weights and the same price. The difference is solely in the classifier configuration: in Fable 5, they are active and redirect risky requests (cyberattacks, synthesis of dangerous substances) to Opus 4.8. In Mythos 5, some of these restrictions are removed — but the model itself is only available to verified organizations through Project Glasswing.
Is Claude Fable 5 available via API?
Yes. Model ID: claude-fable-5. Available from June 9, 2026, without a queue. Supports 1M tokens of context on input and up to 128K tokens in response. Batch API: $5 / $25 per million tokens. When the safety classifier triggers, it returns HTTP 200 with stop_reason: "refusal" — it's not an error and is not billed if there was no output.
Is Fable 5 safe for production right now?
It depends on the domain. For code, analytics, legal, and financial tasks — yes, Anthropic conducted an external bug bounty with no results after 1,000+ hours of testing. However, the classifiers are still configured conservatively: false positives are possible in less than 5% of sessions. If your product relates to cybersecurity or biochemistry, some requests will fall back to Opus 4.8, which needs to be considered in the architecture.
When will Fable 5 become part of standard subscriptions?
Until June 22, 2026 — free for all paid subscribers (Pro, Max, Team, Enterprise). From June 23 — via usage credits. Anthropic promises to reinstate the model in standard plans as soon as capacity allows — there are no specific dates yet.