Claude Sonnet 5 disadvantages and user reviews
Claude Sonnet 5 downsides according to developer reviews — hidden costs, agent failures, refusals. What was confirmed and what wasn't.
Useful articles about Java, Spring, SEO, frontend, and modern technologies. Tips, examples, and lifehacks for developers

Claude Sonnet 5 downsides according to developer reviews — hidden costs, agent failures, refusals. What was confirmed and what wasn't.

Claude Sonnet 5 vs Gemini 3.1 Pro and 3.5 Flash — price, multimodality, benchmarks, agent capabilities. What to choose.

Claude Sonnet 5 vs Kimi K2.5 — price, Agent Swarm, benchmarks, open-weight vs closed. What to choose for agent tasks in 2026

Claude Sonnet 5 vs GPT-5.5 — price, coding benchmarks, agent capabilities, context, and security. What to choose in 2026

Claude Sonnet 5 — tests, capabilities, API price, and whether to switch from GPT-5.5 in 2026. Full technical review

Practical analysis of GPT-5.5-Cyber: static code analysis, OWASP Top 10, malware search, reverse engineering, AI agents, and model limitations
Detailed comparison of GPT-5.5-Cyber, Claude Opus, and Gemini for cybersecurity. Find out which AI model is better at vulnerability analysis

OpenAI introduced GPT-5.5-Cyber, a new model for detecting vulnerabilities in code and security systems, enhancing cybersecurity and automated protection.

Junior developers are disappearing from the market due to AI. Why does this threaten a shortage of seniors and burnout in IT? Data analysis

DeepSeek released DSpark: 60-85% acceleration for V4 Flash/Pro without retraining. We analyze the mechanics, the 661% figures, and how to connect without a GPU.

Grok has started actively generating adult content. Why has this caused scandals, legal investigations, and how will it change the porn industry and our lives?

Analysis of the new AI Performance Report in Google Search Console: AI Overviews, GEO, SEO, metrics, report limitations, and the future of search in 2026.
HNSW or IVFFlat for pgvector? Real-world cases, memory and recall figures, the stale centroid trap, and clear thresholds for transitioning from brute-force to index.

Classic hacking is dead. We'll break down how a hidden prompt in a PDF hijacks your AI agent and forces it to leak your entire company database.

8GB Mac and LM Studio: an honest review of which models are actually enough — Phi-4-mini, Gemma 4 E4B, Metal and context settings, and why AI advice is sometimes wrong.

LM Studio explained in simple terms: MCP, MLX on Apple Silicon, how it differs from Ollama and ChatGPT, and when to choose LM Studio for local AI on Mac.

You're no longer a programmer, you just write prompts? Why Vibe Coding is losing its power and what skills developers will need in 2026.

Is RAG worth it in 2026, when context has reached 2 million tokens? Inference economics, lost in the middle, multitenant data security — an analysis with real numbers.

Q4_K_M, Q8_0, IQ4_XS — what GGUF suffixes mean and what quantization to choose for Ollama. RAM table for 7B–70B + memory calculation formula.

After 30 messages, the bot starts to forget the beginning of the conversation. I'll explain how I solved this through several layers of memory — without increasing token
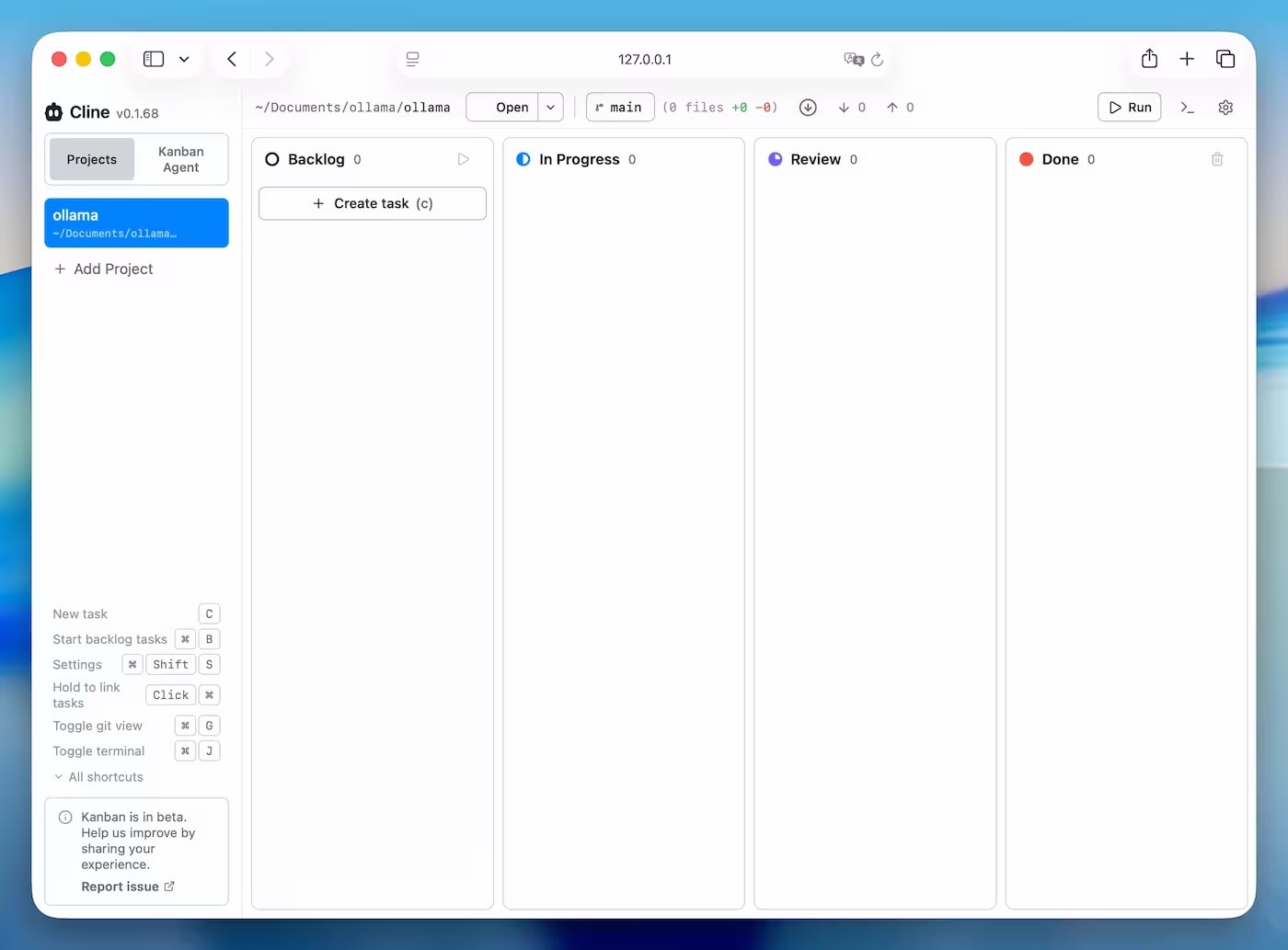
Real experience installing Cline via Ollama: Node >=22 errors, EACCES, PATH after Homebrew, and running Kanban Board on 127.0.0.1:3484.
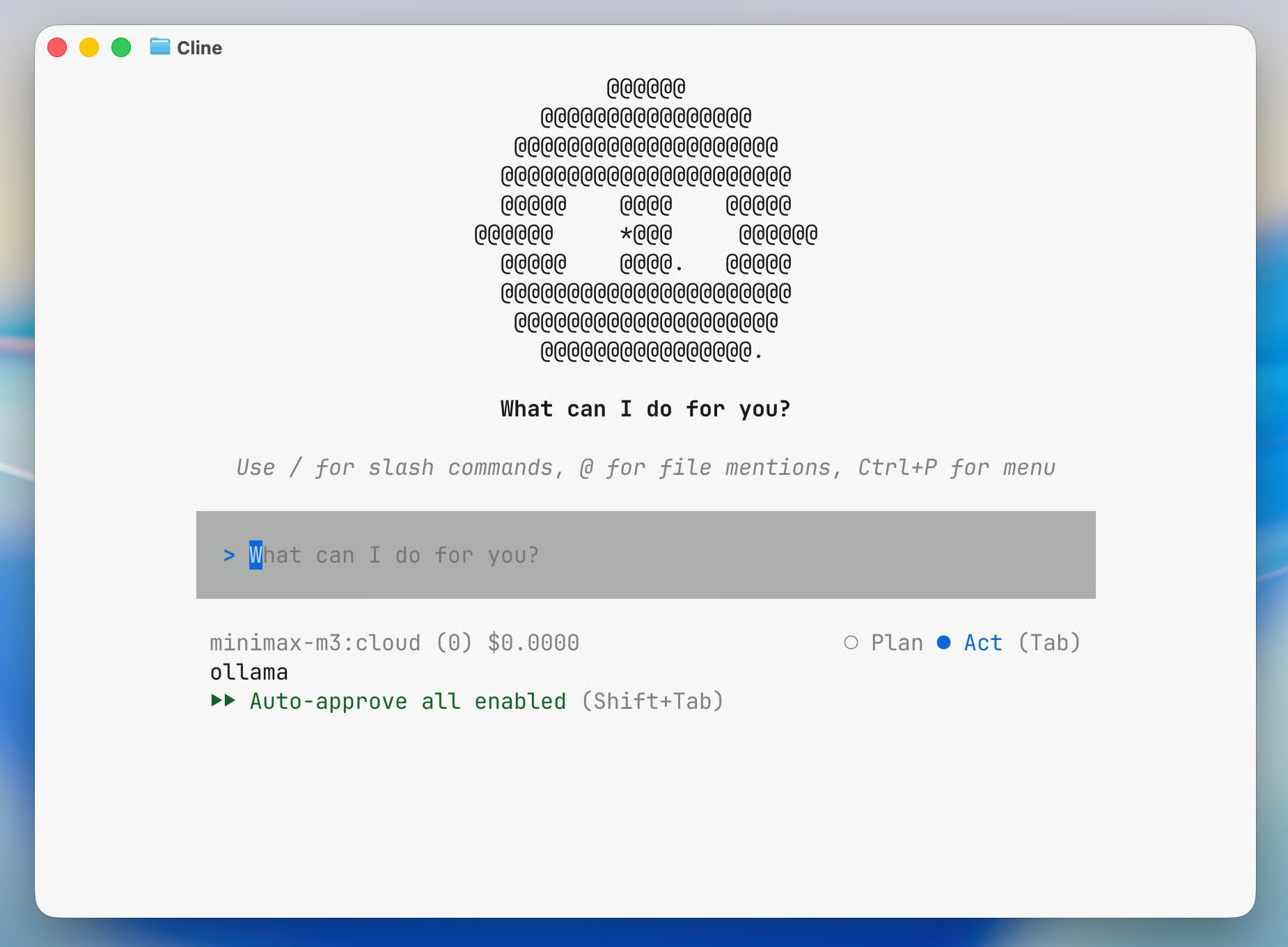
Ollama announced ollama launch cline — AI agent in a single line in the terminal. Local and cloud models, Kanban Board, comparison with Cursor and Claude Code.

Google released DiffusionGemma — an open 26B parameter diffusion model that generates text 4x faster than GPT, Llama, and Qwen. What this means
LangChain or LlamaIndex? Qdrant or pgvector? Comparison of 12 open-source RAG tools with trade-off tables, 5 ready-made stacks, and antipatterns.

Anthropic released Claude Fable 5 — the first public Mythos-class model. We analyze benchmarks, pricing, limitations, and the reason for the release after months of silen