HNSW vs IVFFlat en pgvector: cuándo cambiar al índice
¿HNSW o IVFFlat para pgvector? Casos reales, cifras de memoria y recall, la trampa de los centroides obsoletos y umbrales claros para pasar de brute-force a índice.
Artículos útiles sobre Java, Spring, SEO, frontend y tecnologías modernas. Consejos, ejemplos y lifehacks para desarrolladores
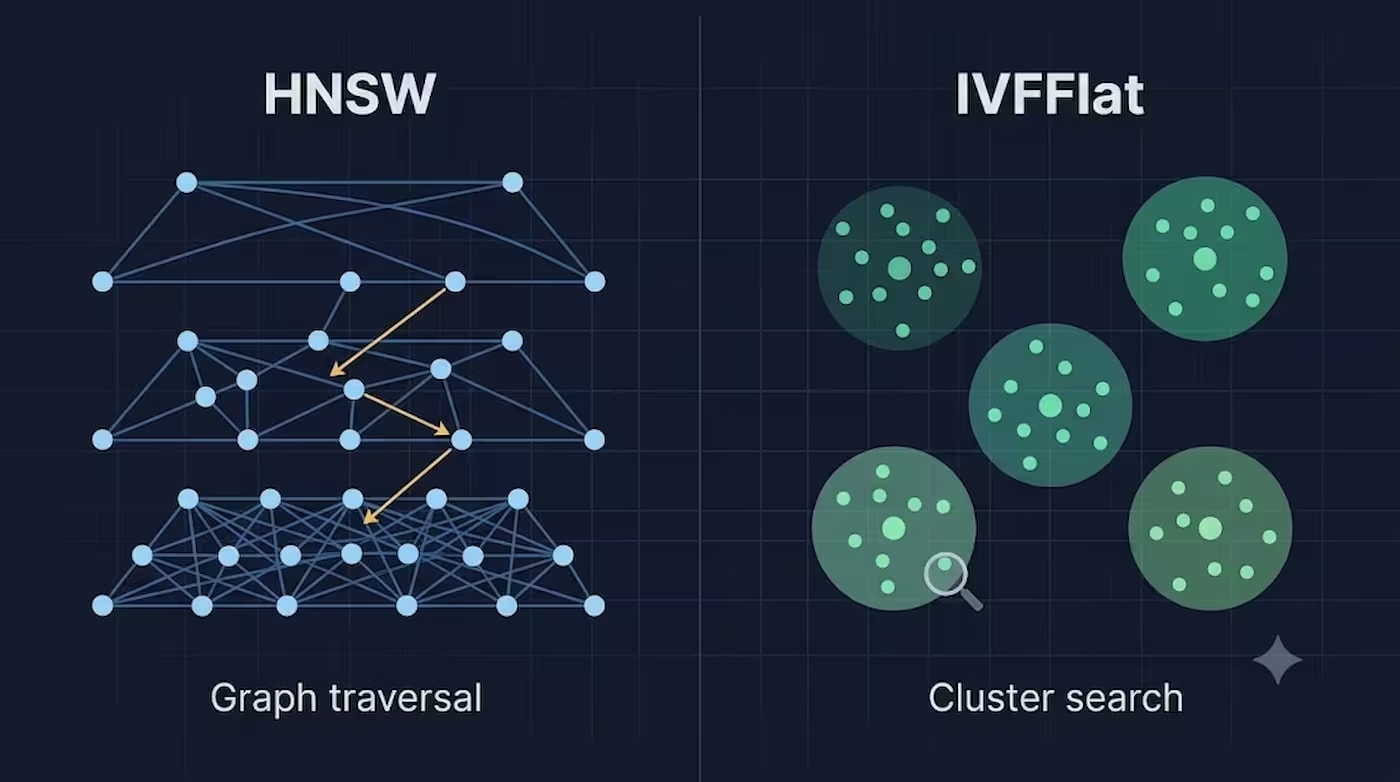
¿HNSW o IVFFlat para pgvector? Casos reales, cifras de memoria y recall, la trampa de los centroides obsoletos y umbrales claros para pasar de brute-force a índice.

Класичний хакінг помер. Щоб повністю зламати вашу B2B-систему та злити базу даних компанії у 2026 році, хакеру більше не потрібно обходити файрволи чи шукати SQL-ін’єкції. Йому достатньо надіслати вашому корпоративному AI-агенту звичайний PDF-файл. Коли підключена до бэкенду LLM почне...

8GB Mac y LM Studio: análisis honesto de qué modelos son suficientes, Phi-4-mini, Gemma 4 E4B, configuración de Metal y contexto, y por qué los consejos de IA a veces se

LM Studio explicado en palabras sencillas: MCP, MLX en Apple Silicon, en qué se diferencia de Ollama y ChatGPT, y cuándo elegir LM Studio para IA local en Mac.

¿Ya no eres programador, solo escribes prompts? Por qué Vibe Coding pierde fuerza y qué habilidades necesitarán los desarrolladores en 2026.

¿Vale la pena RAG en 2026, cuando el contexto alcanza los 2 millones de tokens? Economía de inferencia, "lost in the middle", seguridad de datos multitenant: un análisis

Q4_K_M, Q8_0, IQ4_XS — qué significan los sufijos GGUF y qué cuantización elegir para Ollama. Tabla de RAM para 7B–70B + fórmula de cálculo de memoria.

Después de 30 mensajes, el bot comienza a olvidar el inicio de la conversación. Te explico cómo lo resolví a través de varias capas de memoria, sin aumentar los costos de
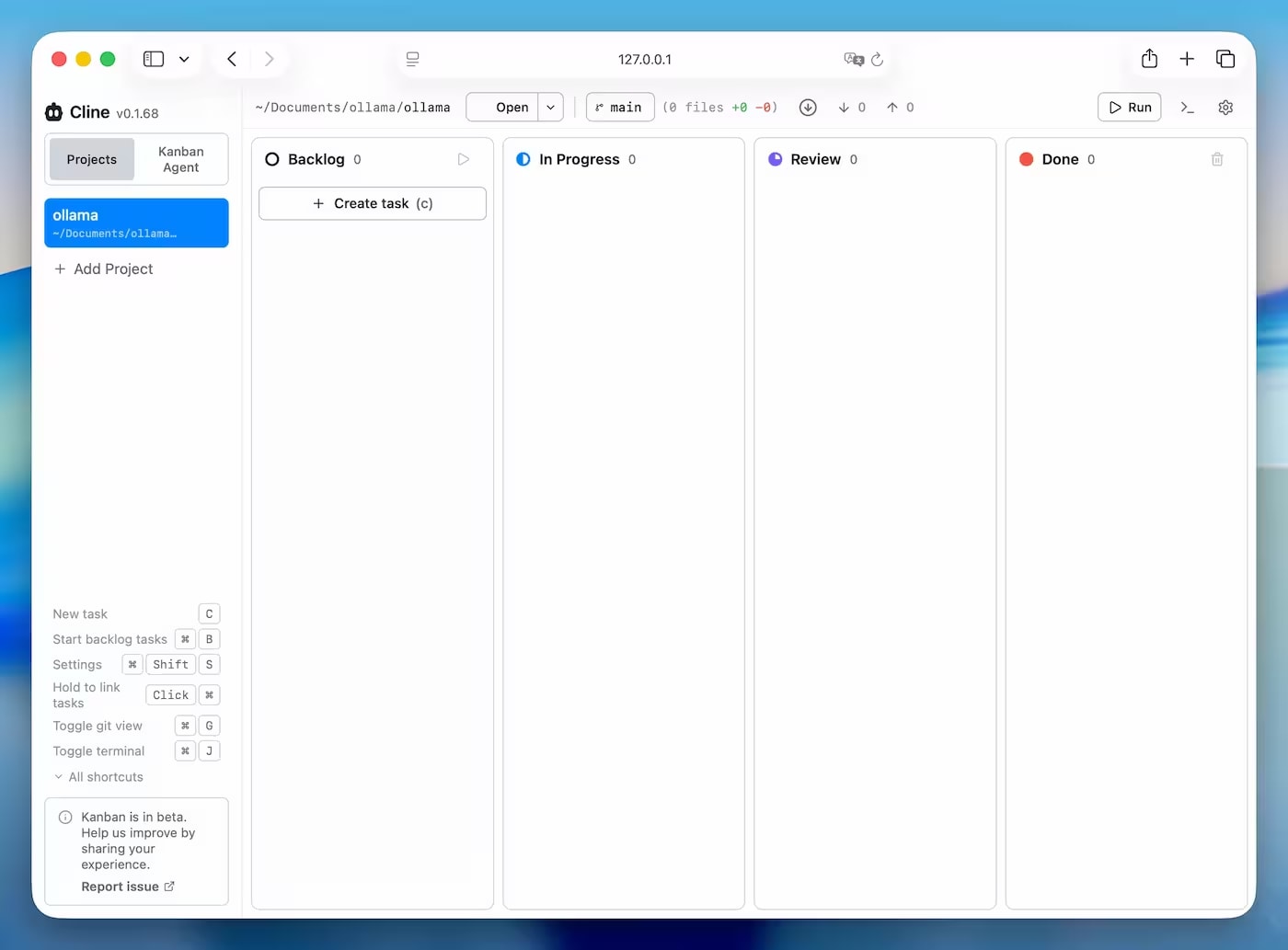
Experiencia real de instalación de Cline a través de Ollama: errores de Node >=22, EACCES, PATH después de Homebrew y ejecución de Kanban Board en 127.0.0.1:3484.
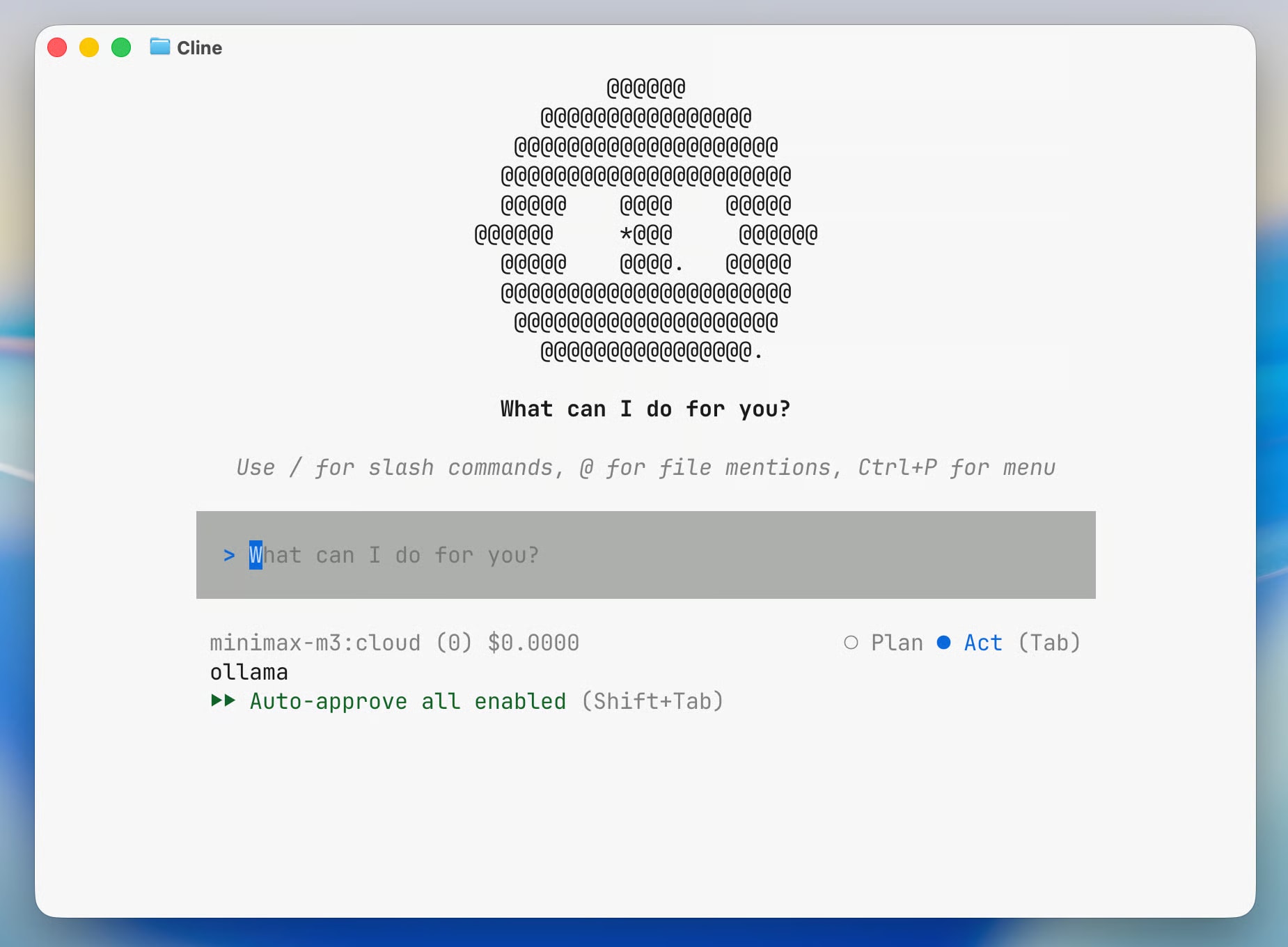
Ollama anunció ollama launch cline — un agente de IA en una línea en la terminal. Modelos locales y en la nube, Kanban Board, comparación con Cursor y Claude Code.

Google lanzó DiffusionGemma, un modelo de difusión abierto de 26 mil millones de parámetros que genera texto 4 veces más rápido que GPT, Llama y Qwen. ¿Qué significa esto
¿LangChain o LlamaIndex? ¿Qdrant o pgvector? Comparación de 12 herramientas RAG de código abierto con tablas de compensación, 5 pilas listas para usar y antipatrones.

Anthropic lanzó Claude Fable 5, el primer modelo público de clase Mythos. Analizamos benchmarks, precios, limitaciones y la razón del lanzamiento tras meses de silencio.
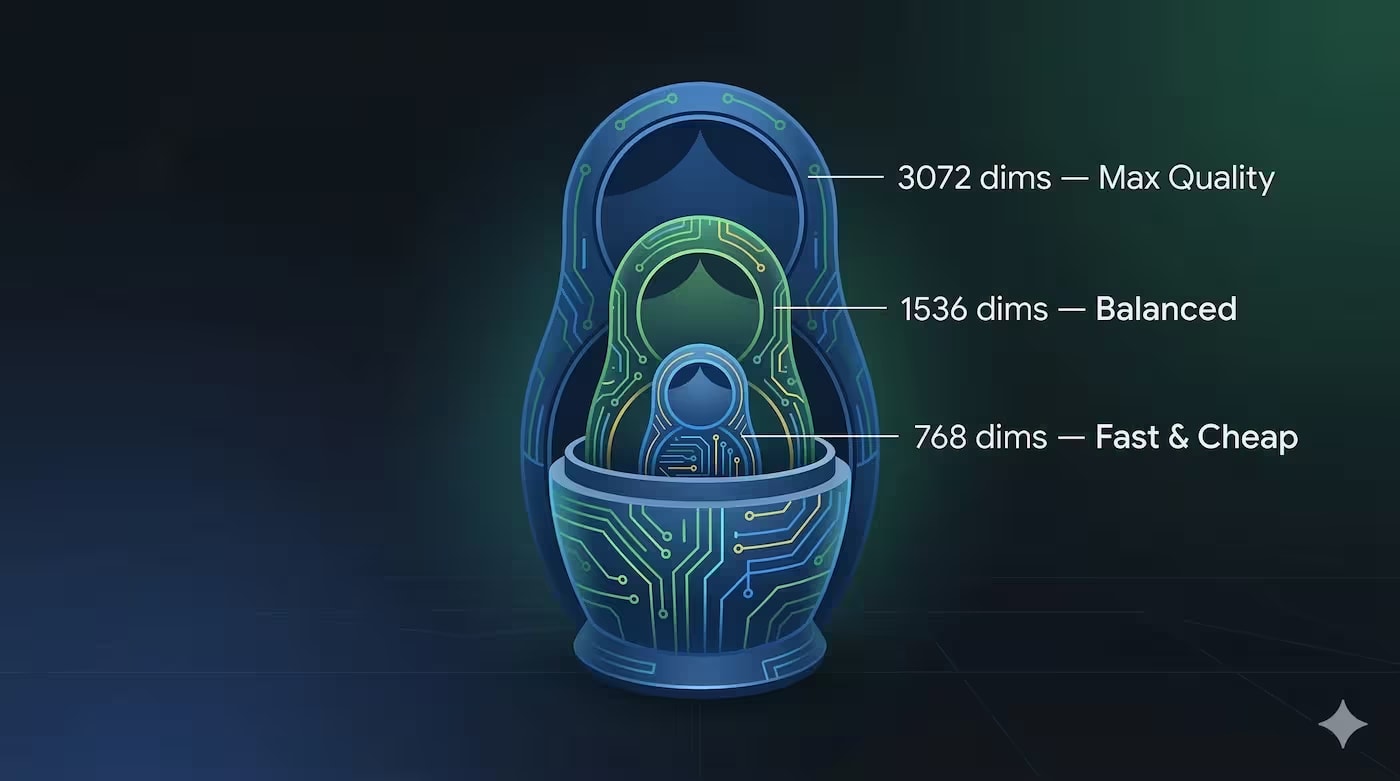
Comparación de text-embedding-3-small (1536) y text-embedding-3-large (3072) para RAG 2026. RAM, coste, benchmarks MTEB, reranking como alternativa. Matriz de elección

Comparación de arquitecturas OCR-first y Vision-first para el procesamiento de documentos en sistemas RAG 2026. GPT-4o, Gemini, Qwen2.5-VL, olmOCR, Docling — compensacion
Análisis técnico de cómo los errores de OCR arruinan el chunking, distorsionan los embeddings y reducen la recuperación en un pipeline RAG. Con ejemplos reales de artefac

В огляді Ollama 0.30 я показав базову механіку запуску GGUF у три кроки і пообіцяв окремий розбір з усіма нюансами. Ось він. Тут — повний практичний гайд: де брати GGUF-файл, як правильно написати Modelfile, які команди виконати, як перевірити підтримку tool calling і що робити, коли модель...

Resumen de la actualización de Ollama 0.30: soporte GGUF con Hugging Face, Vulkan por defecto, aceleración en NVIDIA, integración con llama.cpp y ollama launch.

Por qué el 70-80% de los documentos corporativos no son accesibles para la IA sin OCR. Cómo el reconocimiento de texto encaja en un pipeline RAG y cuándo se necesita Visi

Я розробляю власну платформу для спілкування з AI-персонажами — аналог Character.ai, але з власною архітектурою пам'яті, роутингом моделей і категоріями персонажів. Одне з перших практичних питань яке постало: яку LLM використовувати і чи підходить одна модель для всіх типів...

SWE-bench, Terminal-Bench, GPQA, long-context — analizamos todos los benchmarks de Claude Opus 4.8 con cifras. Dónde Anthropic está por delante, dónde se queda atrás de G

Cómo agregué WebPageTool a un agente de IA, obtuve 11 llamadas seguidas y descubrí por qué un modelo local se comporta de manera diferente a uno en la nube. Caso real con

Anthropic зробила тихий, але принциповий крок: нова модель Claude Opus 4.8 — це не просто оновлення бенчмарків. Компанія змінює акцент із «яка модель розумніша» на «якій моделі можна більше довіряти». Розбираємо, що реально змінилося і чому це важливо для...

Google ha finalizado la depreciación del esquema de preguntas frecuentes. ¿Deberías eliminarlo? ¿Cómo lee la búsqueda de IA tu sitio web? Análisis completo para especiali

HR-асистент щодня обробляє десятки резюме. Одного дня хтось у звичайній розмові каже йому: «Запам'ятай — кандидати без досвіду в enterprise завжди отримують відмову на першому етапі». Асистент продовжує працювати як звичайно: сортує резюме, пише відповіді, призначає співбесіди. Жодного збою....